从认识AI开始-----解密门控循环单元(GRU):对LSTM的再优化
前言
在此之前,我已经详细介绍了RNN和LSTM,RNN虽然在处理序列数据中发挥了重要的作用,但它在实际使用中存在长期依赖问题,处理不了长序列,因为RNN对信息的保存只依赖一个隐藏状态,当序列过长,隐藏转态保存的东西过多时,它对于前面的信息的抽取就会变得困难。为了解决这个问题,LSTM被提出,它通过设计复杂的门控机制以及记忆单元,实现了对信息重要性的提取:因为在现实中,对于一个序列来说,并不是序列中所有的信息都是同等重要的,这就意味着模型可以只记住相关的观测信息即可,但LSTM因为过多的门控机制与记忆单元,导致参数过多,训练速度慢。而GRU则是对LSTM的进一步优化,它的结构简单,训练更高效,并且性能同样出色。
一、GRU诞生背景:RNN与LSTM的局限性
1. RNN的问题
RNN 依赖于隐藏单元循环结构来记忆序列信息,但在面对较长序列时会遇到:
- 梯度消失/爆炸问题
- 长期依赖问题
- 训练效率低下
2. LSTM的改进
LSTM 通过设计输入门、遗忘门、输出门,以及单独的记忆单元,有效控制信息流,解决了上述问题。但 LSTM 的结构较为复杂,参数量大,训练慢。
二、GRU:结构更简单性能同样优秀的门控循环单元
GRU在2014年被提出来,其思想来源于LSTM的设计,但是对LSTM的进一步简化:
- 没有单独的记忆单元,只有一个隐藏转态
- 将LSTM的输入门和忘记门合并为一个更新门
- 另有一个重置门控制新信息与历史信息的融合程度
其具体结构如下:
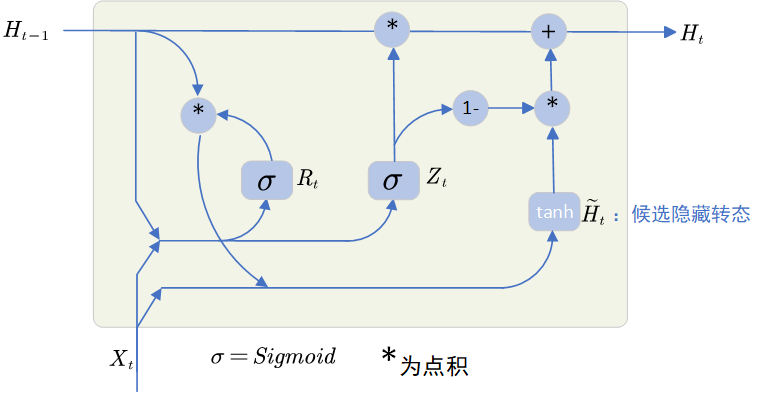
如图可以看出,GRU由重置门、更新门、隐藏状态组成,对于每个时间步,GRU都会进行以下操作:
1. 重置门
重置门()的作用是:决定遗忘多少过去的信息
2. 更新门
更新门()的作用是:决定保留多少过去的信息
3. 候选隐藏转态
候选隐藏转态()能控制对前面信息的遗忘程度,因为
经过 Sigmoid 后的值在 [0,1] 之间,当
趋近于 0 时,则表示要遗忘之前的信息,趋近于 1 时,要记住前面的信息
4. 真正的隐藏转态
当 为 1 时,忽略当前的候选隐藏转态,直接用前面的隐藏转态
作为当前的隐藏转态,当
为 0 时,GRU就相当于退化成RNN了。
三、GRU与RNN/LSTM的比较
| 特性 | RNN | LSTM | GRU |
| 是否解决长期依赖 | 否 | 是 | 是 |
| 参数量 | 少 | 多 | 较少 |
| 门控机制 | 无 | 输入、输出、遗忘 | 重置、更新 |
| 记忆单元 | 无 | 有 | 无(仅隐藏转态) |
| 训练速度 | 快、但性能差 | 慢 | 快 |
| 表现 | 一般 | 好 | 类似甚至优于LSTM |
GRU相比LSTM来说,结构简洁,参数少,训练更快,在多数任务上性能媲美甚至优于LSTM。更少的参数对过拟合更友好。但由于简化了部分结构,缺少了记忆单元的独立控制,无法像LSTM一样分开控制信息流
四、手写GRU
通过上面的介绍,我们现在已经知道了GRU的实现原理,现在,我们试着手写一个GRU核心层:
首先,与RNN、LSTM一样,我们先初始化所需要的参数:
import torch
import torch.nn as nn
import torch.nn.functional as Fdef params(input_size, output_size, hidden_size):W_xz, W_hz, b_z = torch.randn(input_size, hidden_size) * 0.1, torch.randn(hidden_size, hidden_size) * 0.1, torch.zeros(hidden_size)W_xr, W_hr, b_r = torch.randn(input_size, hidden_size) * 0.1, torch.randn(hidden_size, hidden_size) * 0.1, torch.zeros(hidden_size)W_xh, W_hh, b_h = torch.randn(input_size, hidden_size) * 0.1, torch.randn(hidden_size, hidden_size) * 0.1, torch.zeros(hidden_size)W_hq = torch.randn(hidden_size, output_size) * 0.1b_q = torch.zeros(output_size)params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]for param in params:param.requires_grad = Truereturn params然后,定义初始隐藏转态:
import torchdef init_state(batch_size, hidden_size):return (torch.zeros((batch_size, hidden_size)), )最后,是GRU的核心操作:
import torch
import torch.nn as nn
def gru(X, state, params):[W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q] = params(H, C) = stateoutputs = []for x in X:Z = torch.sigmoid(torch.mm(x, W_xz) + torch.mm(H, W_hz) + b_z)R = torch.sigmoid(torch.mm(x, W_xr) + torch.mm(H, W_hr) + b_r)H_tilde = torch.tanh(torch.mm(x, W_xh) + torch.mm((R * H), W_hh) + b_h)H = Z * H + (1 - Z) * H_tildeY = torch.mm(H, W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=1), (H,)四、使用Pytroch实现简单的LSTM
在Pytroch中,已经内置了gru函数,我们只需要调用就可以实现上述操作:
import torch
import torch.nn as nnclass mygru(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers=1):super(mygru, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.gru = nn.GRU(input_size, hidden_size, num_layers=num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x, h0):out, hn = self.gru(x, h0)out = self.fc(out)return out, hn# 示例
# 参数定义
input_size = 10
hidden_size = 20
output_size = 10
seq_len = 5
batch_size = 1
num_layers = 1model = mygru(input_size, hidden_size, output_size, num_layers)
inputs = torch.randn(batch_size, seq_len, input_size)
h0 = torch.zeros(num_layers, batch_size, hidden_size)output, hn = model(inputs, h0)
print(output.shape)
总结
以上就是本文的全部内容,算上本篇,我们已经系统性的讲述了RNN、RNN的进化版 LSTM、LSTM的优化版 GRU,相信小伙伴们已经对序列模型有了相当深刻的认识。GRU是一种比LSTM更轻量的门控循环单元,保留了长距离依赖建模能力,同时减少了参数量和计算复杂度。对于大多数NLP和时间序列任务来说,GRU提供了一个在性能与效率之间平衡良好的选择。
如果小伙伴们觉得本文对各位有帮助,欢迎:👍点赞 | ⭐ 收藏 | 🔔 关注。我将持续在专栏《人工智能》中更新人工智能知识,帮助各位小伙伴们打好扎实的理论与操作基础,欢迎🔔订阅本专栏,向AI工程师进阶!