langchain +ollama +chroma+embedding模型实现RAG入门级Demo(python版)
RAG现在发展出三种类型:Naive RAG(朴素RAG)、Advanced RAG(高级RAG)和Modular RAG(模块化RAG)RAG在成本效益上超过了原生LLM,但也表现出了几个局限性,这也更大家一个印象:入门容易,做好难。Advanced RAG和Modular RAG的发展是为了解决Naive RAG中的缺陷。Naive RAG遵循一个传统的流程,包括索引、检索和生成,它也被称为“检索-阅读”框架,将查询(query)与文档的检索结合起来,通过大语言模型 (LLM) 生成答案。
将数据先通过嵌入(embedding)算法转变为向量数据,然后存储在Chroma这种向量数据库中,当用户在大模型输入问题后,将问题本身也embedding,转化为向量,在向量数据库中查找与之最匹配的相关知识,组成大模型的上下文,将其输入给大模型,最终返回大模型处理后的文本给用户,这种方式不仅降低大模型的计算量,提高响应速度,也降低成本,并避免了大模型的tokens限制,是一种简单高效的处理手段。
Naive RAG
Naive RAG 的优势
简单高效:
架构设计简单,便于实现,特别适合初学者和小型应用场景。
模块化设计:
将检索和生成分离,便于针对每一模块优化。
低延迟:
因为无需复杂的后续排序或多级推理,响应速度快。
Naive RAG 的局限性
结果质量不稳定:
检索的文档片段可能不完全相关,导致生成结果准确性受限。
缺乏上下文整合:
无法有效地对不同文档片段之间的关系建模,例如相互矛盾或补充的信息。
易受查询噪声影响:
用户查询如果不明确,可能导致检索到无关内容。
LangChain
官方文档:https://python.langchain.com/docs/get_started/introduction.html
github: https://github.com/langchain-ai/langchain
优质入门文章:https://blog.csdn.net/v_JULY_v/article/details/131552592
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。
可以做什么?
可以将 LLM 模型(大规模语言模型)与外部数据源进行连接
可以与 LLM 模型进行交互
ollama
https://blog.csdn.net/YXWik/article/details/143871588
chroma
github地址:https://github.com/chroma-core/chroma
向量数据库,轻量级且支持windows,不需要wsl,不需要docker
安装
pip install chromadb
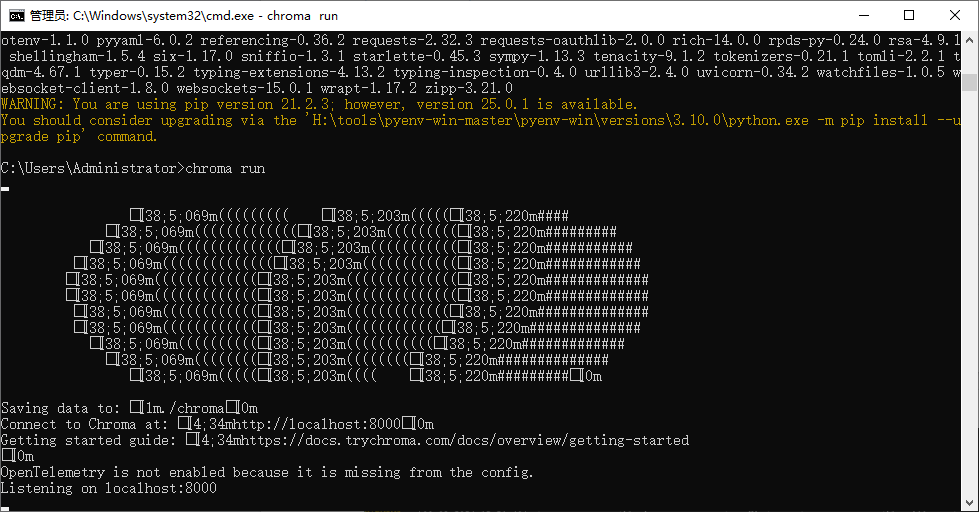
运行
chroma run
embedding模型
选择 BAAI/bge-small-zh-v1.5作为embedding模型,因为它是开源的模型,而且体积较小,性能也不错。
项目
虚拟环境
conda create -n llmrag python=3.10
激活
activate llmrag
torch安装
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorchcuda=12.1 -c pytorch -c nvidia
安装依赖(以下依赖自行选择一个,我这边是ollama本地的选第二个)
#用openai的模型
pip install openai
#如果是本地部署ollama,langchain 对ollama的支持
pip install -U langchain-ollama
#通义千问线上版
pip install -U langchain_openai
支持chroma
pip install langchain_chroma
pip install -U langchain-community
bs4依赖
pip install beautifulsoup4
安装 sentence-transformers
pip install sentence-transformers
准备数据
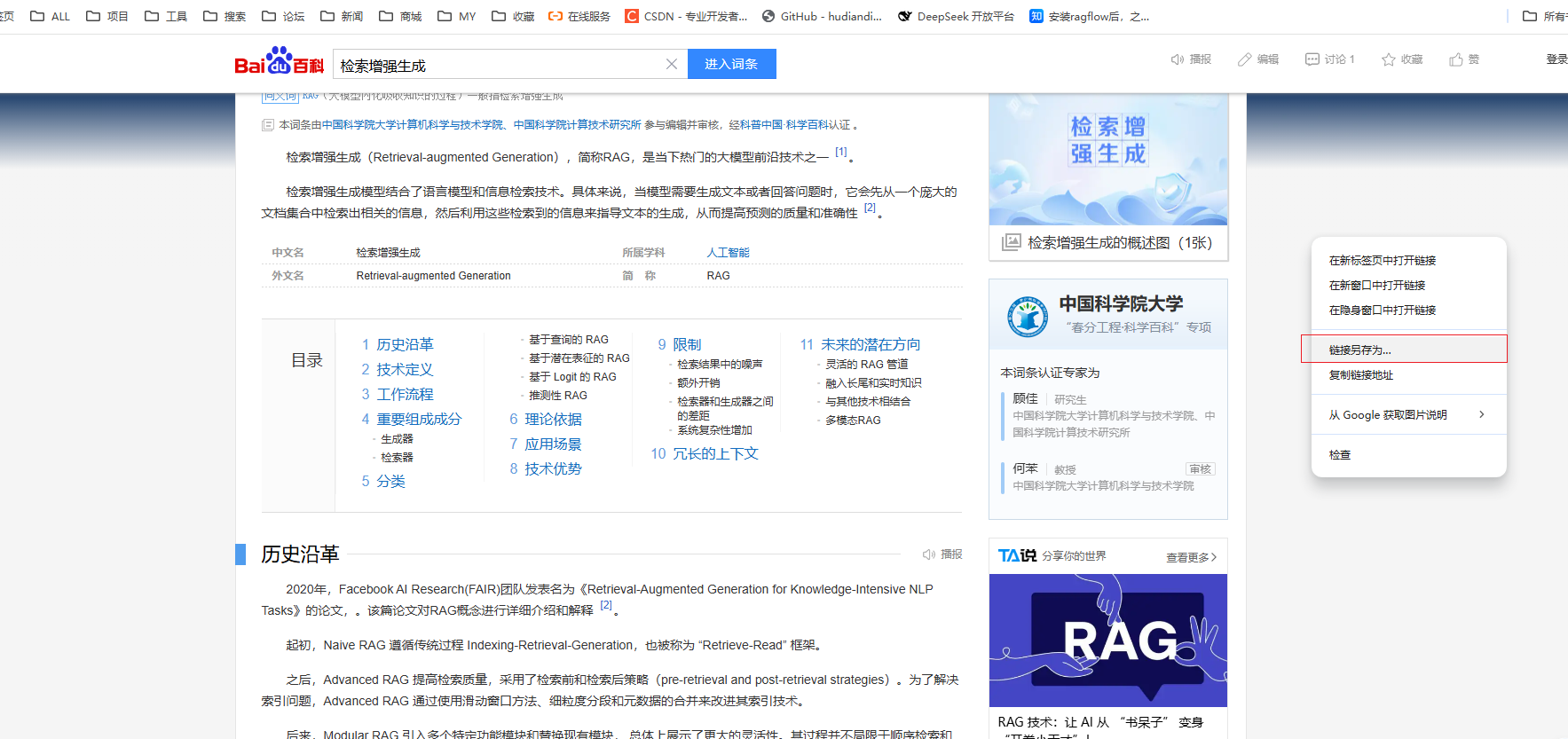
这里拿百度百科的检索增强生成数据做测试
https://baike.baidu.com/item/RAG?fromModule=lemma_search-box
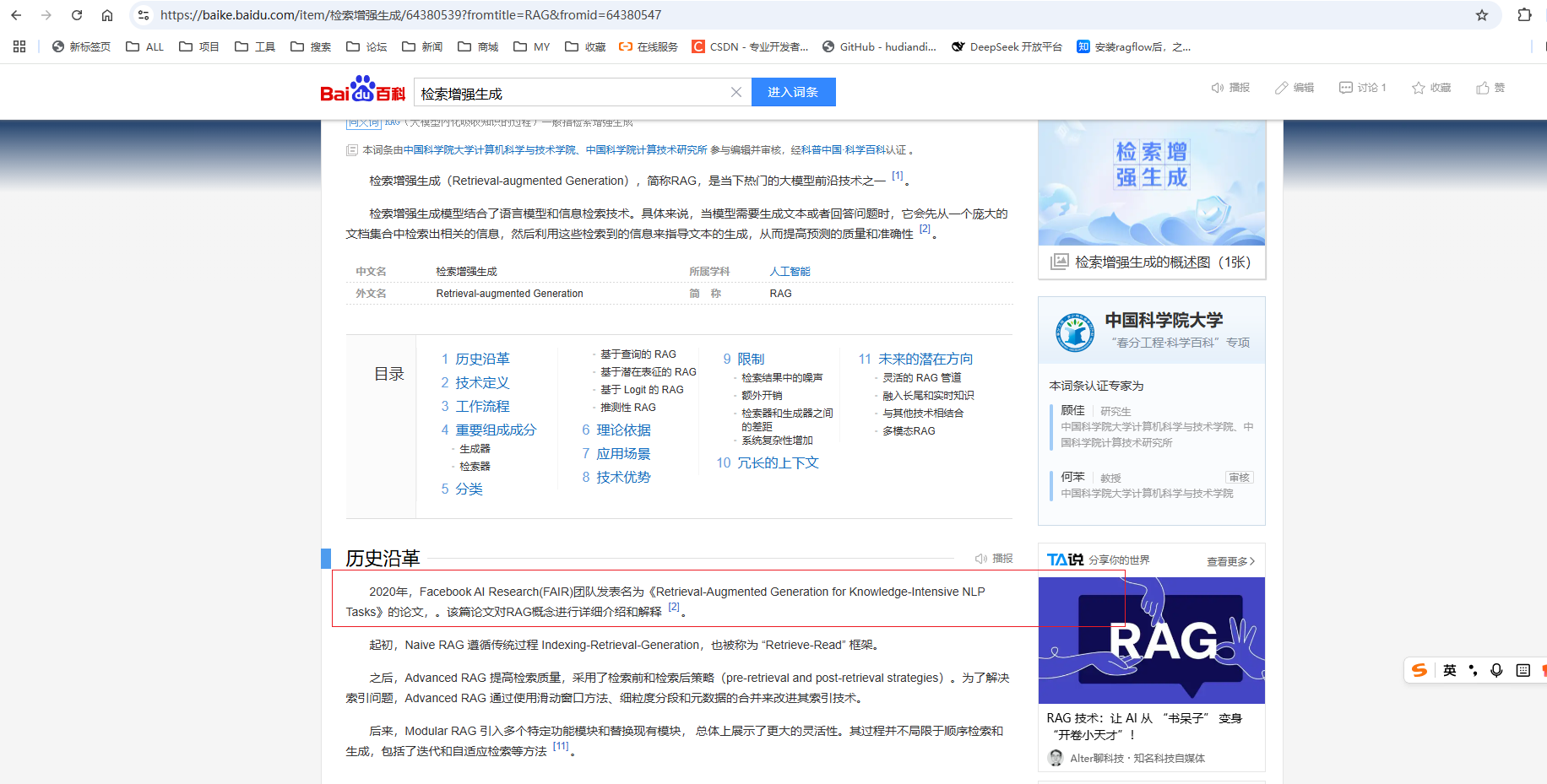
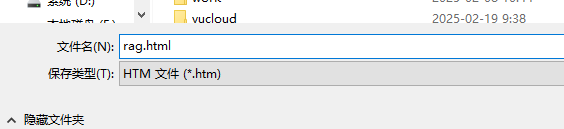
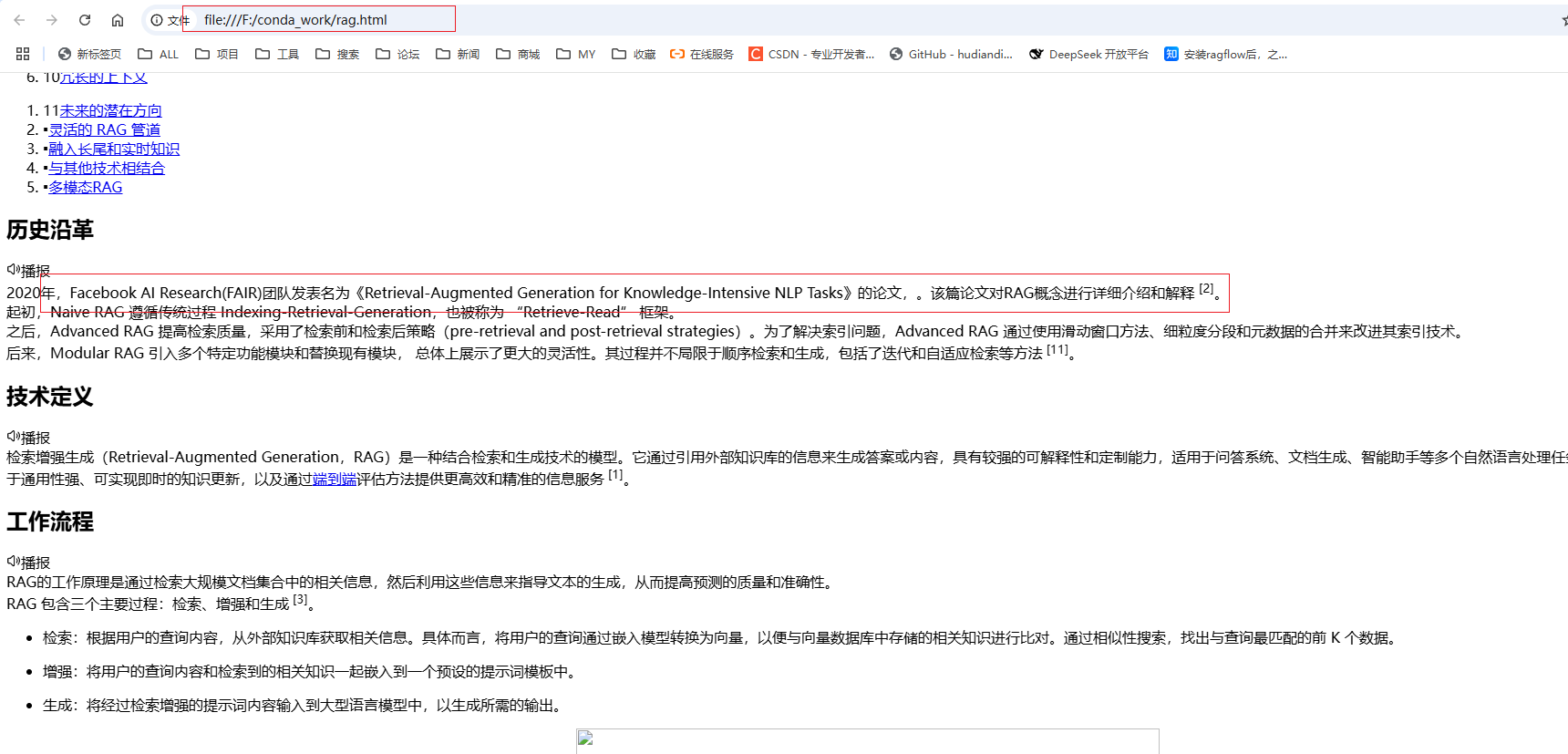
保存到本地
加载本地HTML文件代码
import os
import time
from bs4 import BeautifulSoup
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
from langchain_ollama.llms import OllamaLLM
from langchain_community.chat_models import ChatOpenAI
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from langchain_chroma import Chroma# 设置 USER_AGENT
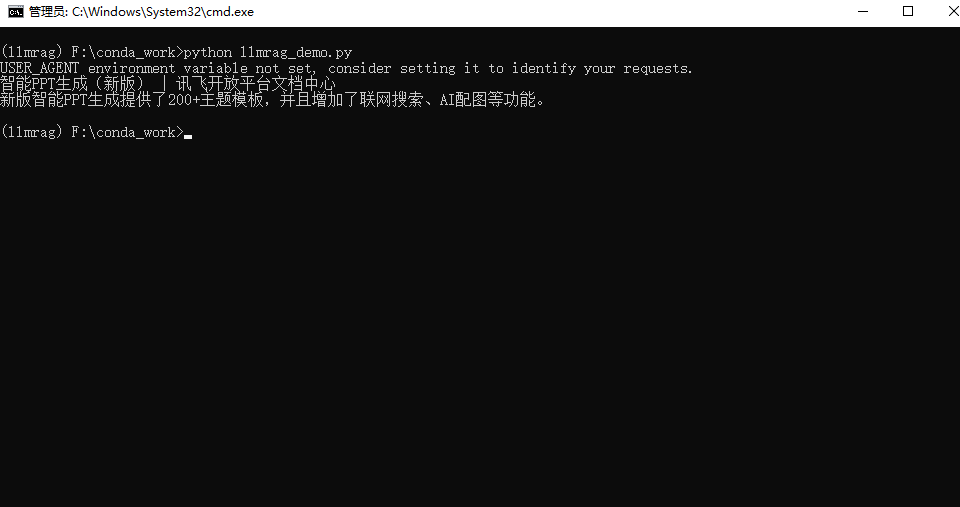
os.environ["USER_AGENT"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"# 加载本地 HTML 文件
def load_local_file(file_path):with open(file_path, "r", encoding="utf-8") as f:html_content = f.read()soup = BeautifulSoup(html_content, "html.parser")return soup.get_text()# 准备知识库数据,建索引
def prepare_data():text = load_local_file("rag.html") # 替换为你的本地 HTML 文件路径text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)chunks = text_splitter.create_documents([text])print(chunks[0].page_content)return chunks# embedding 知识库,保存到向量数据库
def embedding_data(chunks):rag_embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-small-zh-v1.5")vector_store = Chroma.from_documents(documents=chunks, embedding=rag_embeddings, persist_directory="./chroma_langchain_db")retriever = vector_store.as_retriever()return vector_store, retriever
'''
#使用通义千问
llm = ChatOpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处
用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 填写
DashScope base_url
model="qwen-plus"
)
'''
#使用openai
#llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)# 使用 ollama 服务
llm = OllamaLLM(model="qwen2.5:7b")
template = """您是问答任务的助理。
使用以下检索到的上下文来回答问题。
如果你不知道答案,就说你不知道。
最多使用三句话,不超过100字,保持答案简洁。
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)chunks = prepare_data()
vector_store, retriever = embedding_data(chunks)# 生成答案
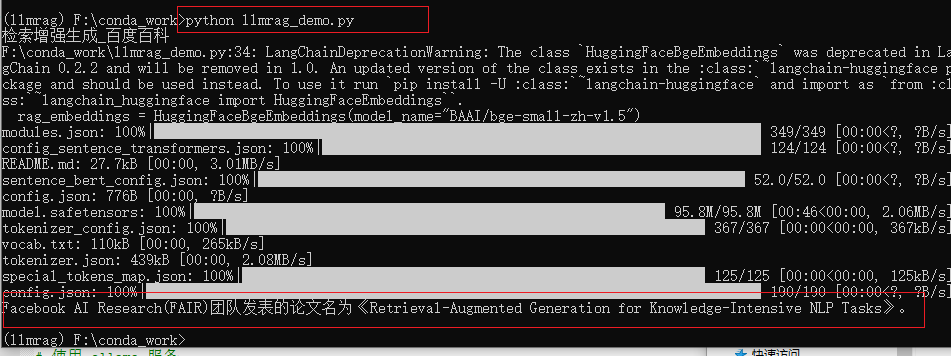
def generate_answer(question):rag_chain = ({"context": retriever, "question": RunnablePassthrough()}| prompt| llm| StrOutputParser())resp = rag_chain.invoke(question)print(resp)query = "Facebook AI Research(FAIR)团队发表的论文叫什么?"
generate_answer(query)
python llmrag_demo.py
加载在线HTML代码
最开始是想加载百度百科在线的html文件的,但是存在百度安全验证

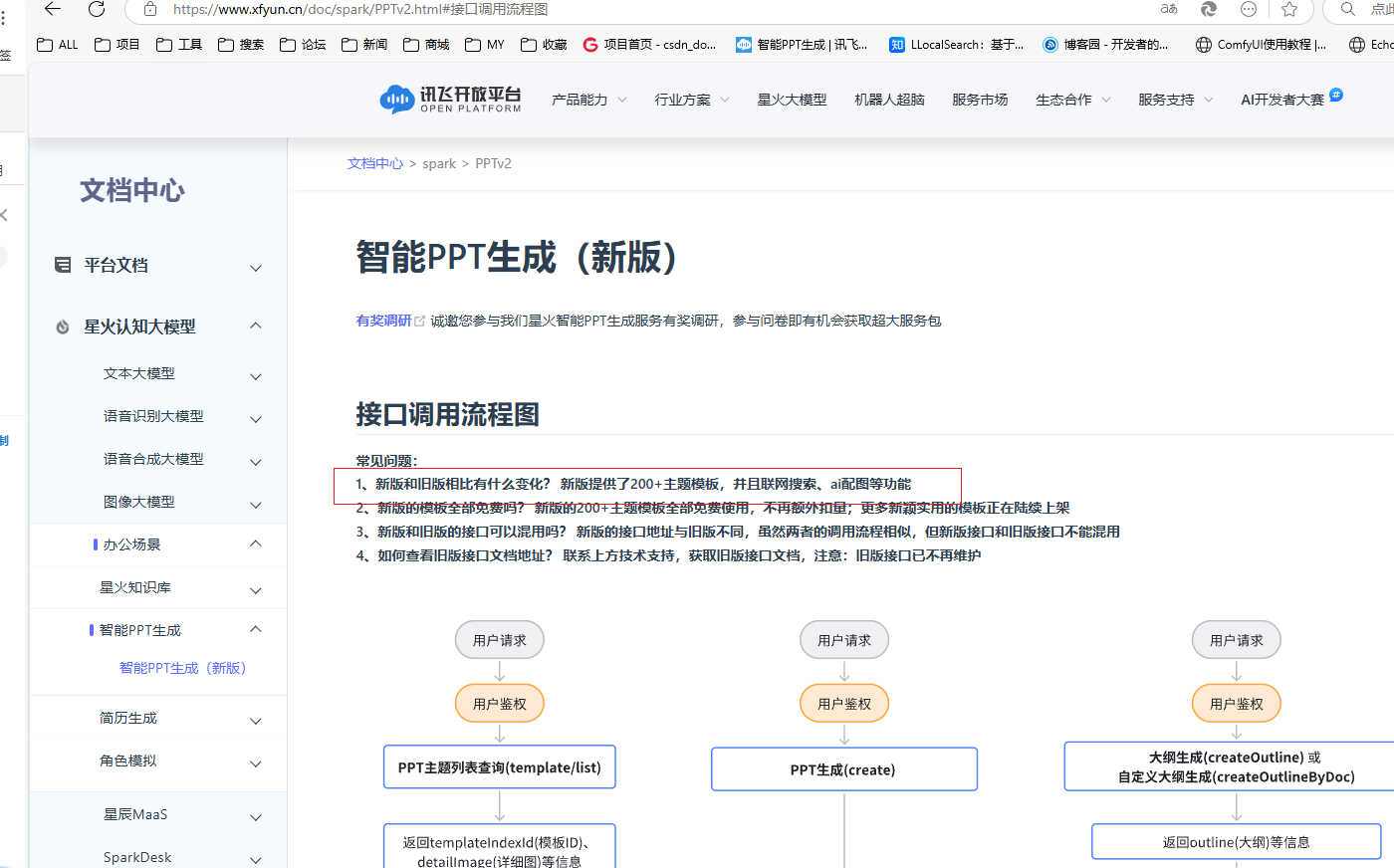
拿讯飞智能PPT生成的在线接口文档网页做测试:https://www.xfyun.cn/doc/spark/PPTv2.html
代码
import os
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
from langchain_ollama.llms import OllamaLLM
from langchain_chroma import Chroma
from sentence_transformers import SentenceTransformer
from langchain.embeddings.base import Embeddings# 自定义 Embeddings 类,基于 sentence-transformers
class CustomHuggingFaceEmbeddings(Embeddings):def __init__(self, model_name="BAAI/bge-small-zh-v1.5"):self.model = SentenceTransformer(model_name)def embed_documents(self, texts):return self.model.encode(texts, convert_to_tensor=False).tolist()def embed_query(self, text):return self.model.encode([text], convert_to_tensor=False)[0].tolist()# 设置环境变量 USER_AGENT
os.environ['USER_AGENT'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'# 准备知识库数据,建索引
def prepare_data():loader = WebBaseLoader("https://www.xfyun.cn/doc/spark/PPTv2.html")documents = loader.load()# chunk_size 是多少token进行分 chunk_overlap 是重叠token 避免一句话截断text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)chunks = text_splitter.split_documents(documents)print(chunks[0].page_content)return chunks# embedding 知识库,保存到向量数据库
def embedding_data(chunks):# 使用自定义的 HuggingFace Embeddingsrag_embeddings = CustomHuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")# embed保存知识到向量数据库vector_store = Chroma.from_documents(documents=chunks,embedding=rag_embeddings,persist_directory="./chroma_langchain_db")retriever = vector_store.as_retriever()return vector_store, retriever# 使用 Ollama 服务
llm = OllamaLLM(model="qwen2.5:7b")template = """您是问答任务的助理。
使用以下检索到的上下文来回答问题。
如果你不知道答案,就说你不知道。
最多使用三句话,不超过100字,保持答案简洁。
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)# 数据准备和嵌入
chunks = prepare_data()
vector_store, retriever = embedding_data(chunks)# 生成答案
def generate_answer(question):rag_chain = ({"context": retriever, "question": RunnablePassthrough()}| prompt| llm| StrOutputParser())resp = rag_chain.invoke(question)print(resp)# 示例查询
query = "新版和旧版相比有什么变化?"
generate_answer(query)