损失函数总结
目录
- 回归问题
- L1损失 平均绝对值误差(MAE)
- Smooth L1 Loss
- L2损失 均方误差损失MSE
- 分类问题
- 交叉熵损失
- KL 散度损失 KLDivLoss
- 负对数似然损失 NLLLoss
- 排序
- MarginRankingLoss
回归问题
L1损失 平均绝对值误差(MAE)
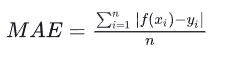
指模型预测值f(x)和真实值y之间绝对差值的平均值
优点:
- L1损失函数的导数是常量,有着稳定的梯度,所以不会有梯度爆炸的问题。
- 对于离群点造成的惩罚是固定的,不会被放大。
缺点:
- 在0处不可导。
- MAE的导数为常数,所以在较小的损失值时,得到的梯度也相对较大,可能造成模型震荡不利于收敛。
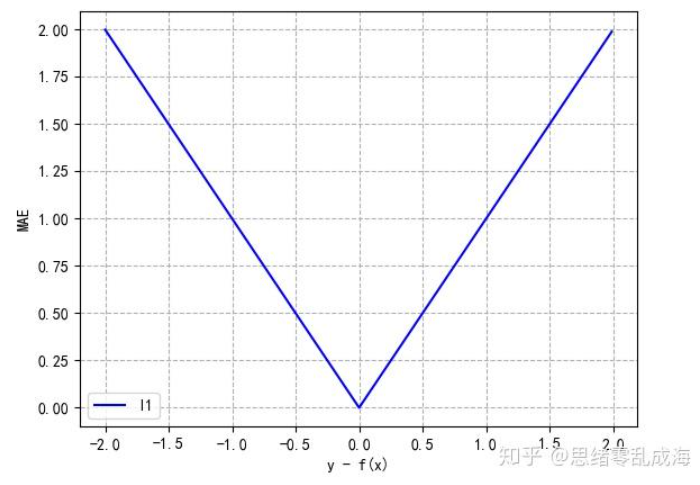
Smooth L1 Loss
一个平滑版的L1 Loss,其公式如下:

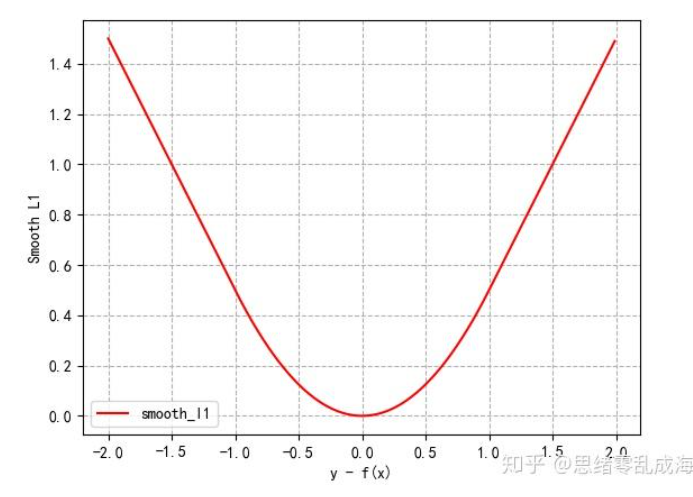
L2损失 均方误差损失MSE
mean squared error loss
M S E = ∑ ( y − y ^ ) 2 n MSE=\frac{\sum(y-\hat y)^2}{n} MSE=n∑(y−y^)2
其中,y表示真实值,ŷ表示模型的预测值,n表示样本数量,∑表示求和运算。
MSE损失计算预测值与真实值之间的差异,然后将差值平方,再对所有样本进行求和,最后除以样本数量,得到平均值。MSE是预测值与真实值差异的平方的平均值。
特点:
- 对较大的预测误差有较高的惩罚,因为差异的平方放大了较大的误差。当函数的输入值距离中心值较远的时候,使用梯度下降法求解的时候梯度很大,可能造成梯度爆炸。
- 函数曲线连续,处处可导,随着误差值的减小,梯度也减小,有利于收敛到最小值。
目标检测回归损失函数——L1、L2、smooth L1
分类问题
交叉熵损失
Cross Entropy loss
在多分类任务中,经常采用 softmax 激活函数+交叉熵损失函数,因为交叉熵描述了两个概率分布的差异。


KL 散度损失 KLDivLoss
KL散度(Kullback-Leibler divergence),可以以称作相对熵(relative entropy)或信息散度(information divergence)。KL散度的理论意义在于度量两个概率分布之间的差异程度,当KL散度越大的时候,说明两者的差异程度越大;而当KL散度小的时候,则说明两者的差异程度小。如果两者相同的话,则该KL散度应该为0。
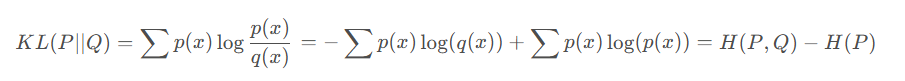
最后得到的第一项称作P和Q的交叉熵(cross entropy),后面一项就是熵。
在信息论中,熵代表着信息量,H ( P ) H§H§代表着基于P PP分布自身的编码长度,也就是最优的编码长度(最小字节数)。而H ( P , Q ) H(P,Q)H(P,Q)则代表着用Q QQ的分布去近似P PP分布的信息,自然需要更多的编码长度。并且两个分布差异越大,需要的编码长度越大。所以两个值相减是大于等于0的一个值,代表冗余的编码长度,也就是两个分布差异的程度。所以KL散度在信息论中还可以称为相对熵(relative entropy)。
————————————————
原文链接:https://blog.csdn.net/Rocky6688/article/details/103470437
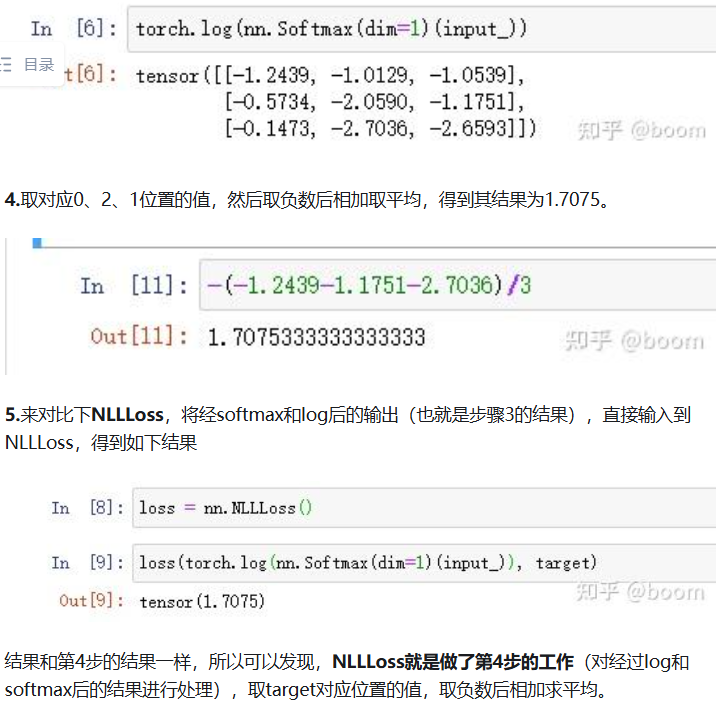
负对数似然损失 NLLLoss
负对数似然损失(Negative Log-Likelihood Loss,NLLLoss)是一种常用的损失函数,用于多类别分类任务中的概率建模。它基于最大似然估计的原理,鼓励模型预测正确类别的概率尽可能高。
N L L L o s s = − l o g ( p ( y ) ) NLLLoss=-log(p(y)) NLLLoss=−log(p(y))
详解pytorch的损失函数:NLLLoss()和CrossEntropyLoss()
排序
MarginRankingLoss
MarginRankingLoss(边际排序损失)是一种用于学习排序模型的损失函数,常用于训练具有排序目标的模型,目标是将正样本的预测得分(正例)与负样本的预测得分(负例)之间的差异最大化,同时保持一定的边际(margin)。这样可以促使模型在预测时更好地区分正负样本,从而提高排序性能。
loss(x1, x2, y) = max(0, -y * (x1 - x2) + margin)
其中,y为标签,取值为1或-1,表示正样本或负样本;x1为正样本的预测得分;x2为负样本的预测得分;margin为边际,是一个预先指定的超参数。
MarginRankingLoss首先计算正样本的预测得分与负样本的预测得分之差,然后将其与边际进行比较。如果差异大于边际,则损失为0,表示模型已经达到了边际的要求。如果差异小于边际,则损失为差异的负值,以惩罚模型对正负样本的错误排序。
通过最小化MarginRankingLoss来调整模型的参数,可以使模型更好地区分正负样本,从而提高排序任务的性能。适当选择边际参数可以根据具体任务的需求来平衡模型对正负样本的排序关系。