【HDFS入门】HDFS性能调优实战:压缩与编码技术深度解析
目录
1 HDFS性能调优概述
2 HDFS压缩技术原理与应用
2.1 常见压缩算法比较
2.2 压缩流程架构
2.3 压缩配置实践
3 列式存储编码技术
3.1 ORC与Parquet对比
3.2 ORC文件结构
3.3 Parquet编码流程
4 性能调优实战建议
4.1 压缩选择策略
4.2 编码优化技巧
5 性能测试与监控
5.1 基准测试方法
5.2 关键监控指标
6 总结
1 HDFS性能调优概述
Hadoop分布式文件系统(HDFS)作为大数据生态系统的存储基石,其性能直接影响整个数据处理流程的效率。在实际生产环境中,合理的性能调优可以显著提升HDFS的吞吐量、降低存储成本并优化资源利用率。本文将重点探讨HDFS中的压缩与编码技术,包括Snappy、Gzip等压缩算法以及ORC/Parquet等列式存储格式。
2 HDFS压缩技术原理与应用
2.1 常见压缩算法比较
| 压缩算法 | 压缩比 | 压缩速度 | 解压速度 | CPU消耗 | 适用场景 |
| Gzip | 高 | 中等 | 中等 | 高 | 冷数据存储 |
| Bzip2 | 最高 | 慢 | 慢 | 很高 | 归档数据 |
| Snappy | 低 | 非常快 | 非常快 | 低 | 实时处理 |
| LZO | 中等 | 快 | 快 | 中等 | 通用场景 |
| Zstd | 高 | 快 | 快 | 中等 | 平衡场景 |
2.2 压缩流程架构

流程说明:
- 原始数据根据业务需求选择合适的压缩算法
- 判断压缩格式是否支持分割(splittable)
- 可分割格式(如Bzip2)可直接被MapReduce处理
- 不可分割格式(如Gzip)需要预处理解压
- 最终实现高效的数据处理流程
2.3 压缩配置实践
<!-- core-site.xml -->
<property><name>io.compression.codecs</name><value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
</property><!-- mapred-site.xml -->
<property><name>mapreduce.map.output.compress</name><value>true</value>
</property>
<property><name>mapreduce.map.output.compress.codec</name><value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>3 列式存储编码技术
3.1 ORC与Parquet对比
| 特性 | ORC | Parquet |
| 设计目标 | Hive优化 | 通用列式存储 |
| 压缩效率 | 高(使用zlib或Snappy) | 高(使用Gzip或Snappy) |
| 查询性能 | Hive查询极快 | 跨平台查询性能好 |
| 模式演化 | 有限支持 | 完善支持 |
| 适用场景 | Hive生态系统 | 多计算引擎(Spark, Impala等) |
3.2 ORC文件结构
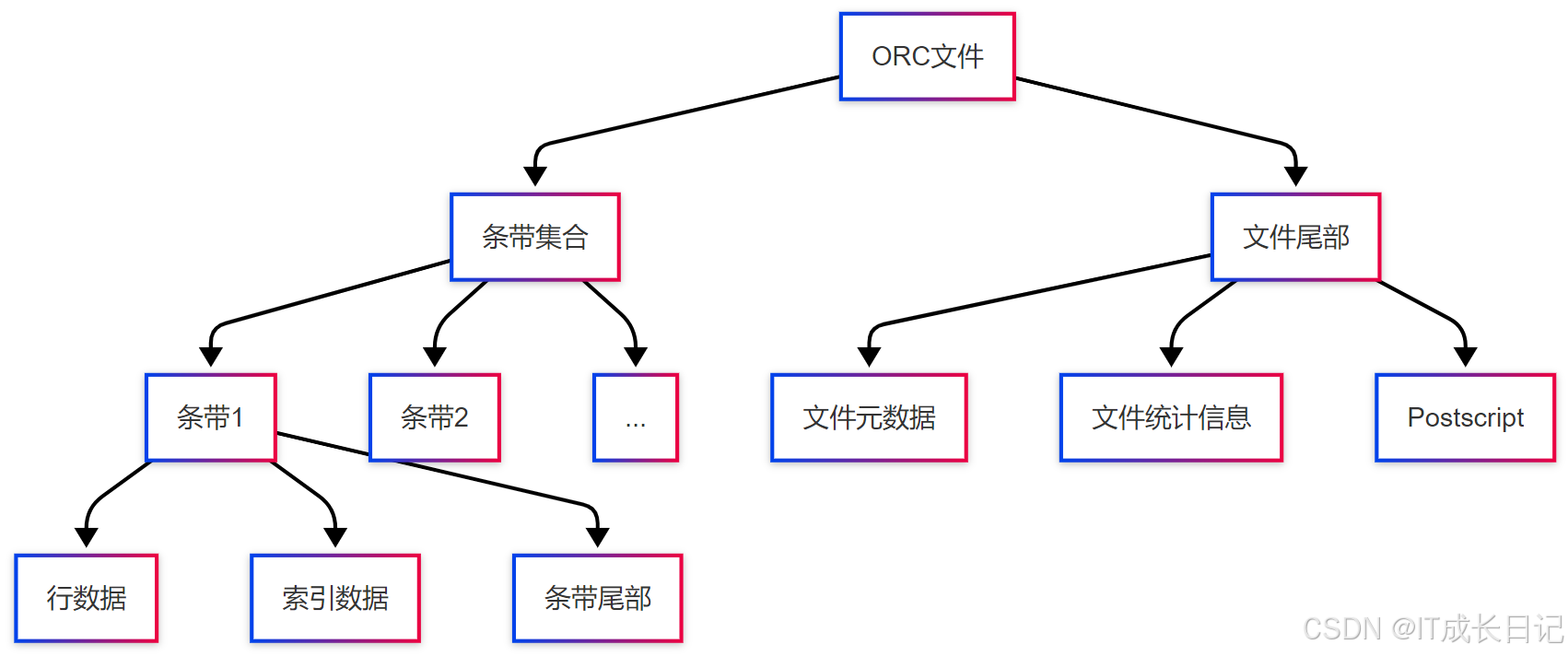
结构说明:
- ORC文件由多个条带(stripe)组成,默认每个256MB
- 每个条带包含多行数据,内部按列存储
- 索引数据包含每列的最小/最大值,实现谓词下推
- 文件尾部包含全局元数据和统计信息
- Postscript存储压缩参数和版本信息
3.3 Parquet编码流程
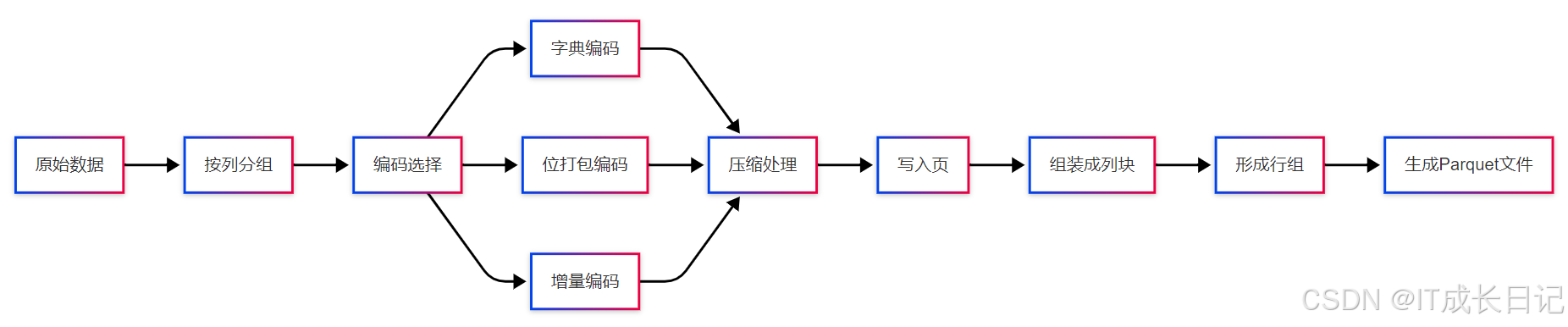
编码流程:
- 数据首先按列分组处理
- 根据数据类型和特征选择最佳编码方式
- 字典编码适用于低基数列
- 位打包适合布尔值或小范围整型
- 增量编码适合有序数值列
- 编码后进行压缩处理
- 最终形成页、列块、行组的多层结构
4 性能调优实战建议
4.1 压缩选择策略
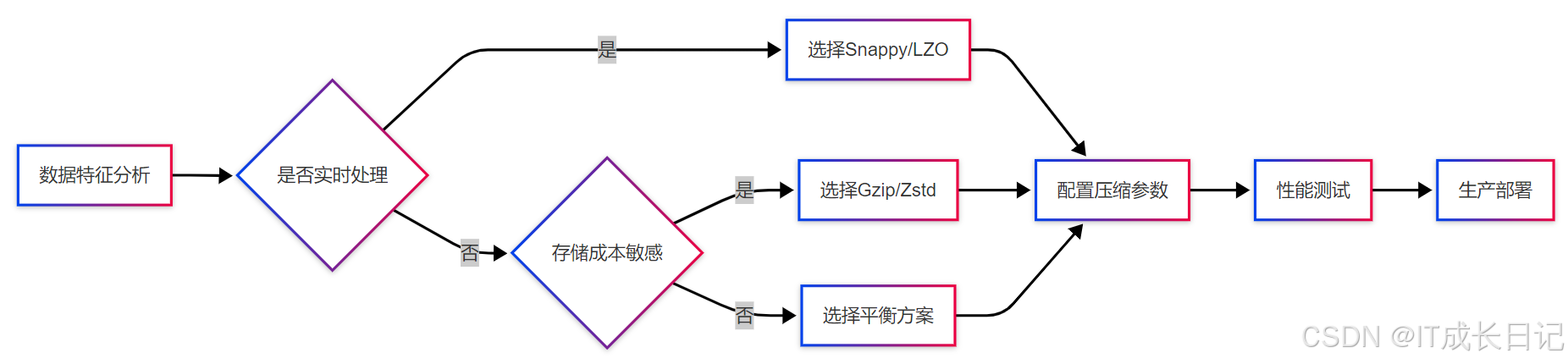
决策流程:
- 首先分析数据处理时效性要求
- 实时处理场景优先选择低延迟压缩算法
- 离线批处理考虑存储成本因素
- 中间方案可选择Zstd等平衡型算法
- 最终通过性能测试确定最佳配置
4.2 编码优化技巧
- ORC调优参数
CREATE TABLE ads_test_orc (...
) STORED AS ORC
TBLPROPERTIES ("orc.compress"="ZSTD","orc.create.index"="true","orc.bloom.filter.columns"="user_id,product_id","orc.stripe.size"="268435456", -- 256MB"orc.row.index.stride"="10000"
);- Parquet优化建议
// Spark中配置Parquet参数
spark.conf.set("spark.sql.parquet.compression.codec", "snappy")
spark.conf.set("parquet.block.size", "256MB")
spark.conf.set("parquet.page.size", "1MB")
spark.conf.set("parquet.dictionary.enabled", "true")- 混合存储策略
- 热数据:Snappy压缩 + 高频列单独存储
- 温数据:Zstd压缩 + 适度索引
- 冷数据:Gzip压缩 + 最小元数据
5 性能测试与监控
5.1 基准测试方法

5.2 关键监控指标
压缩效率指标
- 压缩比 = 原始大小 / 压缩后大小
- 压缩耗时/解压耗时
- CPU利用率变化
I/O性能指标
- 读取吞吐量(MB/s)
- HDFS字节读取/写入量
- 平均I/O等待时间
查询性能指标
- 扫描数据量减少比例
- 查询响应时间提升
- 资源使用效率(CPU/MEM/IO)
6 总结
通过合理的压缩与编码策略,我们可以在HDFS上实现显著的性能提升。实际调优时需要综合考虑数据类型、访问模式、资源限制等多方面因素。