数据结构与算法:图论——最短路径
最短路径
先给出一些leetcode算法题,以后遇见了相关题目再往上增加
最短路径的4个常用算法是Floyd、Bellman-Ford、SPFA、Dijkstra。不同应用场景下,应有选择地使用它们:
- 图的规模小,用Floyd。若边的权值有负数,需要判断负圈。
- 图的规模大,且边的权值非负,用Dijkstra。
- 图的规模大,且边的权值有负数,用SPFA,需要判断负圈。
| 结点N、边M | 边权值 | 选用算法 | 数据结构 |
|---|---|---|---|
| n<200 | 允许有负 | Floyd | 邻接矩阵 |
| n×m<107 | 允许有负 | Bellman-Ford | 邻接表 |
| 更大 | 有负 | SPFA | 邻接表、前向星 |
| 更大 | 无负数 | Dijkstra | 邻接表、前向星 |
2.1、Floyd算法
- Floyed算法:主要是构建 二维矩阵:dp[i][j] 表示从节点 i 到节点 j 最短距离
- 初始化矩阵时:有方向性、并且同一节点的最短距离为0
// floyed 算法vector<vector<int>> dp(n + 1, vector<int>(n + 1, INT_MAX / 2));for (auto a : times) {dp[a[0]][a[1]] = a[2];}for (int i = 0; i <= n; i++) {dp[i][i] = 0;}for (int k = 0; k <= n; k++) for (int i = 0; i <= n; i++) for (int j = 0; j <= n; j++) if (dp[i][j] > dp[i][k] + dp[k][j]) dp[i][j] = dp[i][k] + dp[k][j];1、743. 网络延迟时间
有 n 个网络节点,标记为 1 到 n。
给你一个列表 times,表示信号经过 有向 边的传递时间。 times[i] = (ui, vi, wi),其中 ui 是源节点,vi 是目标节点, wi 是一个信号从源节点传递到目标节点的时间。
现在,从某个节点 K 发出一个信号。需要多久才能使所有节点都收到信号?如果不能使所有节点收到信号,返回 -1 。
示例 1:
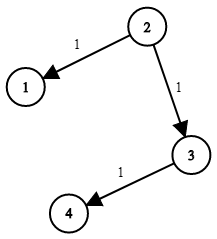
输入:times = [[2,1,1],[2,3,1],[3,4,1]], n = 4, k = 2
输出:2
示例 2:
输入:times = [[1,2,1]], n = 2, k = 1
输出:1
示例 3:
输入:times = [[1,2,1]], n = 2, k = 2
输出:-1
提示:
1 <= k <= n <= 1001 <= times.length <= 6000times[i].length == 31 <= ui, vi <= nui != vi0 <= wi <= 100- 所有
(ui, vi)对都 互不相同(即,不含重复边)
// floyed 算法
class Solution {
public:int networkDelayTime(vector<vector<int>>& times, int n, int k) {vector<vector<int>> dp(n + 1, vector<int>(n + 1, INT_MAX / 2));for (auto a : times) {dp[a[0]][a[1]] = a[2];}for (int i = 0; i <= n; i++) {dp[i][i] = 0;}for (int k = 0; k <= n; k++) {for (int i = 0; i <= n; i++) {for (int j = 0; j <= n; j++) {if (dp[i][j] > dp[i][k] + dp[k][j]) {dp[i][j] = dp[i][k] + dp[k][j];}}}}int res = 0;for (int i = 1; i <= n; i++) {if (dp[k][i] == INT_MAX / 2)return -1;res = max(res, dp[k][i]);}return res;}
};
2、1334. 阈值距离内邻居最少的城市
- 这个用floyed直接算即可。无向图构造矩阵时重复操作即可
有 n 个城市,按从 0 到 n-1 编号。给你一个边数组 edges,其中 edges[i] = [fromi, toi, weighti] 代表 fromi 和 toi 两个城市之间的双向加权边,距离阈值是一个整数 distanceThreshold。
返回能通过某些路径到达其他城市数目最少、且路径距离 最大 为 distanceThreshold 的城市。如果有多个这样的城市,则返回编号最大的城市。
注意,连接城市 i 和 j 的路径的距离等于沿该路径的所有边的权重之和。
示例 1:
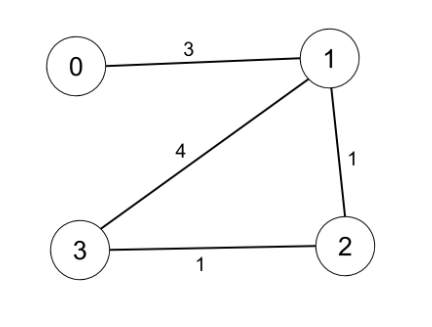
输入:n = 4, edges = [[0,1,3],[1,2,1],[1,3,4],[2,3,1]], distanceThreshold = 4
输出:3
解释:城市分布图如上。
每个城市阈值距离 distanceThreshold = 4 内的邻居城市分别是:
城市 0 -> [城市 1, 城市 2]
城市 1 -> [城市 0, 城市 2, 城市 3]
城市 2 -> [城市 0, 城市 1, 城市 3]
城市 3 -> [城市 1, 城市 2]
城市 0 和 3 在阈值距离 4 以内都有 2 个邻居城市,但是我们必须返回城市 3,因为它的编号最大。
示例 2:
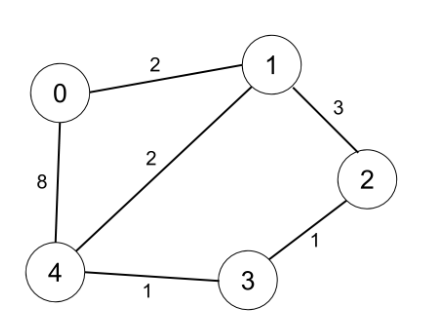
输入:n = 5, edges = [[0,1,2],[0,4,8],[1,2,3],[1,4,2],[2,3,1],[3,4,1]], distanceThreshold = 2
输出:0
解释:城市分布图如上。
每个城市阈值距离 distanceThreshold = 2 内的邻居城市分别是:
城市 0 -> [城市 1]
城市 1 -> [城市 0, 城市 4]
城市 2 -> [城市 3, 城市 4]
城市 3 -> [城市 2, 城市 4]
城市 4 -> [城市 1, 城市 2, 城市 3]
城市 0 在阈值距离 2 以内只有 1 个邻居城市。
class Solution {
public:int findTheCity(int n, vector<vector<int>>& edges, int distanceThreshold) {vector<vector<int>> dp(n, vector<int>(n, INT_MAX / 2));for (auto a : edges) {dp[a[0]][a[1]] = a[2];dp[a[1]][a[0]] = a[2];}for (int k = 0; k < n; k++)for (int i = 0; i < n; i++)for (int j = 0; j < n; j++)if (dp[i][j] > dp[i][k] + dp[k][j])dp[i][j] = dp[i][k] + dp[k][j];// floyed计算完毕,取次数判断即可vector<int> cnt(n, 0);for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {if (i == j)continue;if (dp[i][j] <= distanceThreshold)cnt[i]++;}}int min = *min_element(cnt.begin(), cnt.end());int res;for (int i = n - 1; i >= 0; i--) {if (min == cnt[i]) {res = i;break;}}return res;}
};
2.2、BellmanFord算法
- Bellman-ford算法的思路也很简单,直接就是两层循环,内层循环所有边,外层循环就是循环所有边的次数。
- 时间复杂度是O(n*m)显然不如dijkstra快
- 优点:它可以处理负权边和负权环的情况。并且可以处理限制次数的问题。
// dp[j] 表示节点k到j的最短路径:并且注意每次更新最短路径,是在上一次的dp上更新:
// a[0] 表示起始节点;a[1] 表示最终节点;a[2]表示a[0]到a[1] 的距离大小。
// a[0]->a[1]距离为a[2]:所以每次更新的都是 dp[a[1]] ,但是需要上一次的整体的predp,来取a[0]节点的最短距离// 最标准的形式有前一个的最小距离的predp
int networkDelayTime(vector<vector<int>>& times, int n, int k) {vector<int> dp(n+1,INT_MAX/2);dp[k] = 0;bool flag;while(1){flag = true;vector<int> predp(dp);for(auto a:times){if(dp[a[1]] > predp[a[0]]+a[2]){flag = false;dp[a[1]] = predp[a[0]]+a[2];}}if(flag) break;}int res = *max_element(dp.begin()+1,dp.end());return res==INT_MAX/2?-1:res;}// 然而没有predp也可以,省下来空间
int networkDelayTime(vector<vector<int>>& times, int n, int k) {vector<int> dp(n+1,INT_MAX/2);dp[k ] = 0;bool flag;while(1){flag = true;for(auto a:times){if(dp[a[1]] > dp[a[0]]+a[2]){flag = false;dp[a[1]] = dp[a[0]]+a[2];}}if(flag) break;}int res = *max_element(dp.begin()+1,dp.end());return res==INT_MAX/2?-1:res;
}
1、743. 网络延迟时间
示例 1:
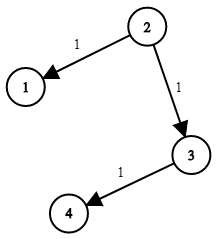
输入:times = [[2,1,1],[2,3,1],[3,4,1]], n = 4, k = 2
输出:2
// BellmanFord算法 算法复杂度为O(m*n)
class Solution {
public:int networkDelayTime(vector<vector<int>>& times, int n, int k) {vector<int> dp(n+1,INT_MAX/2);dp[k ] = 0;bool flag;while(1){flag = true;// vector<int> predp(dp);for(auto a:times){if(dp[a[1]] > dp[a[0]]+a[2]){flag = false;dp[a[1]] = dp[a[0]]+a[2];}}if(flag) break;}int res = *max_element(dp.begin()+1,dp.end());return res==INT_MAX/2?-1:res;}
};
2、787. K 站中转内最便宜的航班
- 经典使用BellmanFord算法题目:最多经过
k站中转的路线
有 n 个城市通过一些航班连接。给你一个数组 flights ,其中 flights[i] = [fromi, toi, pricei] ,表示该航班都从城市 fromi 开始,以价格 pricei 抵达 toi。
现在给定所有的城市和航班,以及出发城市 src 和目的地 dst,你的任务是找到出一条最多经过 k 站中转的路线,使得从 src 到 dst 的 价格最便宜 ,并返回该价格。 如果不存在这样的路线,则输出 -1。
示例 1:
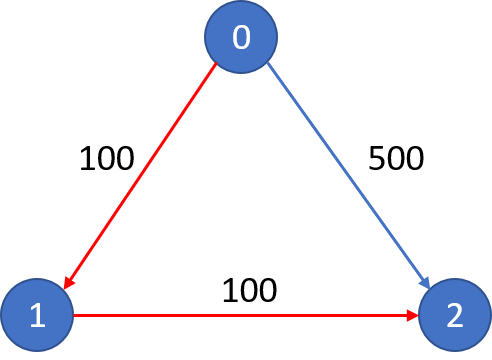
输入:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 1
输出: 200
解释:
城市航班图如下
从城市 0 到城市 2 在 1 站中转以内的最便宜价格是 200,如图中红色所示。
示例 2:
输入:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 0
输出: 500
解释:
城市航班图如下
从城市 0 到城市 2 在 0 站中转以内的最便宜价格是 500,图中蓝色所示。
提示:
1 <= n <= 1000 <= flights.length <= (n * (n - 1) / 2)flights[i].length == 30 <= fromi, toi < nfromi != toi1 <= pricei <= 104- 航班没有重复,且不存在自环
0 <= src, dst, k < nsrc != dst
/*BellmanFord算法::外层的路径就是中转的次数,但是注意K++;是中转1此,那么可以使用两条路径使用BellmanFord算法最标准形式:使用predp形式
*/
class Solution {
public:int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int k) {vector<int> dp(n, 1e5+1);dp[src] = 0;k++;while (k--) {vector<int> predp(dp);// 这里最好加&可以大大提高速度for (auto &a : flights) {if(dp[a[1]]>predp[a[0]]+a[2])dp[a[1]] =predp[a[0]]+a[2];}}return dp[dst] == 1e5+1? -1 : dp[dst];}
};
/*不使用BellmanFord算法最标准形式:无predp形式无法准确得到中转次数:结果不对,但是不考虑次数的话,也能得到最短距离
*/// 结果不对
class Solution {
public:int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst,int k) {vector<int> dp(n, 1e5+1);dp[src] = 0;k++;while (k--) {// vector<int> predp(dp);for (auto &a : flights) {if(dp[a[1]]>dp[a[0]]+a[2])dp[a[1]] =dp[a[0]]+a[2];}}return dp[dst] == 1e5+1? -1 : dp[dst];}
};3、1514. 概率最大的路径
- 本题重点是无向图:两边都要操作一次,重复操作即可
- 无向图:说白了就是条件是有向图的两倍,给反转前后节点即可
给你一个由 n 个节点(下标从 0 开始)组成的无向加权图,该图由一个描述边的列表组成,其中 edges[i] = [a, b] 表示连接节点 a 和 b 的一条无向边,且该边遍历成功的概率为 succProb[i] 。
指定两个节点分别作为起点 start 和终点 end ,请你找出从起点到终点成功概率最大的路径,并返回其成功概率。
如果不存在从 start 到 end 的路径,请 返回 0 。只要答案与标准答案的误差不超过 1e-5 ,就会被视作正确答案。
示例 1:
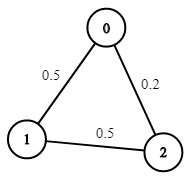
输入:n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.2], start = 0, end = 2
输出:0.25000
解释:从起点到终点有两条路径,其中一条的成功概率为 0.2 ,而另一条为 0.5 * 0.5 = 0.25
示例 2:
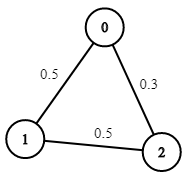
输入:n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.3], start = 0, end = 2
输出:0.30000
示例 3:
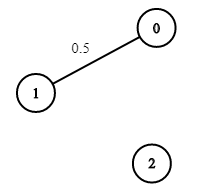
输入:n = 3, edges = [[0,1]], succProb = [0.5], start = 0, end = 2
输出:0.00000
解释:节点 0 和 节点 2 之间不存在路径
提示:
2 <= n <= 10^40 <= start, end < nstart != end0 <= a, b < na != b0 <= succProb.length == edges.length <= 2*10^40 <= succProb[i] <= 1- 每两个节点之间最多有一条边
class Solution {
public:double maxProbability(int n, vector<vector<int>>& edges,vector<double>& succProb, int start_node,int end_node) {vector<double> dp(n, 0);dp[start_node] = 1;while (1) {bool flag = true;for (int i = 0; i < succProb.size(); i++) {// 双向图:反转前后再操作一次即可if (dp[edges[i][1]] < dp[edges[i][0]] * succProb[i]) {flag = false;dp[edges[i][1]] = dp[edges[i][0]] * succProb[i];}if (dp[edges[i][0]] < dp[edges[i][1]] * succProb[i]) {flag = false;dp[edges[i][0]] = dp[edges[i][1]] * succProb[i];}}if (flag) break;}return dp[end_node];}
};
3、1334. 阈值距离内邻居最少的城市
- 这个用floyed直接算即可。使用bellmanFord可以做
有 n 个城市,按从 0 到 n-1 编号。给你一个边数组 edges,其中 edges[i] = [fromi, toi, weighti] 代表 fromi 和 toi 两个城市之间的双向加权边,距离阈值是一个整数 distanceThreshold。
返回能通过某些路径到达其他城市数目最少、且路径距离 最大 为 distanceThreshold 的城市。如果有多个这样的城市,则返回编号最大的城市。
注意,连接城市 i 和 j 的路径的距离等于沿该路径的所有边的权重之和。
示例 1:
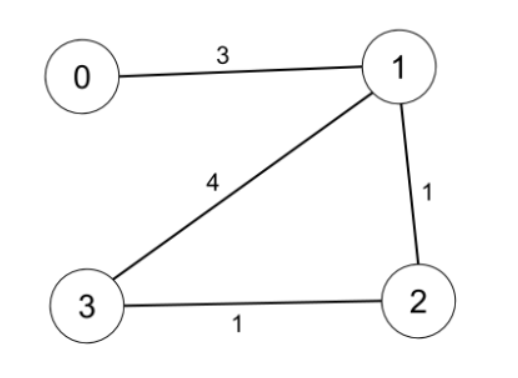
输入:n = 4, edges = [[0,1,3],[1,2,1],[1,3,4],[2,3,1]], distanceThreshold = 4
输出:3
解释:城市分布图如上。
每个城市阈值距离 distanceThreshold = 4 内的邻居城市分别是:
城市 0 -> [城市 1, 城市 2]
城市 1 -> [城市 0, 城市 2, 城市 3]
城市 2 -> [城市 0, 城市 1, 城市 3]
城市 3 -> [城市 1, 城市 2]
城市 0 和 3 在阈值距离 4 以内都有 2 个邻居城市,但是我们必须返回城市 3,因为它的编号最大。
示例 2:
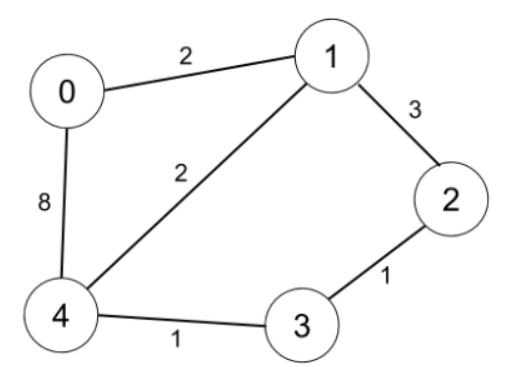
输入:n = 5, edges = [[0,1,2],[0,4,8],[1,2,3],[1,4,2],[2,3,1],[3,4,1]], distanceThreshold = 2
输出:0
解释:城市分布图如上。
每个城市阈值距离 distanceThreshold = 2 内的邻居城市分别是:
城市 0 -> [城市 1]
城市 1 -> [城市 0, 城市 4]
城市 2 -> [城市 3, 城市 4]
城市 3 -> [城市 2, 城市 4]
城市 4 -> [城市 1, 城市 2, 城市 3]
城市 0 在阈值距离 2 以内只有 1 个邻居城市。
class Solution {
public:int targetnum(int n, vector<vector<int>>& edges, int distanceThreshold,int k) {vector<int> dp(n, INT_MAX / 2);dp[k] = 0;while (1) {bool flag = true;vector<int> predp(dp);for (auto& a : edges) {if (dp[a[1]] > predp[a[0]] + a[2]) {flag = false;dp[a[1]] = predp[a[0]] + a[2];}if (dp[a[0]] > predp[a[1]] + a[2]) {flag = false;dp[a[0]] = predp[a[1]] + a[2];}}if (flag)break;}int res = 0;/*这里注意:这个是排除本身for (int i = 0; i < n; i++) {if (i == k)continue;if (dp[i] <= distanceThreshold) {res++;}}若改成:只要碰到i!=k,则跳出这个for循环,后面都不执行了for (int i = 0; i < n && i!=k; i++) {if (dp[i] <= distanceThreshold) {res++;}}*/for (int i = 0; i < n; i++) {if (i == k)continue;if (dp[i] <= distanceThreshold) {res++;}}return res;}// 找到最右边的最小值及坐标。int findTheCity(int n, vector<vector<int>>& edges, int distanceThreshold) {int min_num = 200;int res = 0;for(int i = 0;i<n;i++){int mid = BellmabFord( n, edges, i, distanceThreshold);if(mid<=min_num){min_num = mid;res = i; }}return res;}// 直观但臃肿。int findTheCity(int n, vector<vector<int>>& edges, int distanceThreshold) {int minn = INT_MAX / 2;vector<int> res;for (int i = 0; i < n; i++) {res.push_back(targetnum(n, edges, distanceThreshold, i));}int sul = 0;int minnub = *min_element(res.begin(), res.end());for (int i = n - 1; i >= 0; i--) {if (res[i] == minnub) {sul = i;break;}}return sul;}
};
2.3、dijkstra算法
- 基础型:图的规模大,且边的权值非负,用Dijkstra。时间复杂度O(N*N)。可以看出时间复杂度 只和 n (节点数量)有关系。
// dijkstra算法基础版/*基础版:适用于题目中给出距离矩阵,给出矩阵
*/
vector<int> dijkstra(vector<vector<int>>& value, int start) {//需要一个二维矩阵从0到n,0基本上没有用,无关的都是INT_MAX / 2//对角线为0//返回了一个value[i][j]表示从i到j的最短路径,但是i,j不为0int len = value.size(); // len = n + 1;int n = len - 1;vector<int> res(len, INT_MAX);res[start] = 0;vector<bool> visit(len, false);for (int i = 1; i <= n; i++) {// 找到最小蓝的位置int minbule = 0;for (int j = 1; j <= n; j++) {if (!visit[j] && res[minbule] > res[j]) {minbule = j;}}if(visited[blue]) continue;// 把最小蓝变成白色visit[minbule] = true;// 更新所有最短距离for (int j = 1; j <= n; j++) {res[j] = min(res[j], res[minbule] + value[minbule][j]);}}return res;
}
- 堆优化型:使用边数,边数少的,堆优化比较好。时间复杂度:O(E * (N + logE)) E为边的数量,N为节点数量。
- 适用条件:但 n 很大,边 的数量 很小的时候(稀疏图),是不是可以换成从边的角度来求最短路呢?
int dijkstra_networkDelayTime2(vector<vector<int>>& times, int n, int k) {unordered_map<int, vector<pair<int, int > > > mp;for (auto a : times) {mp[a[0]].push_back({a[1], a[2]});}// 不一定要用map,使用vector效果一样:只不过是保存a[0]点指向的节点和距离vector<vector<pair<int, int>>> g(n);for (auto &t : times) {int x = t[0] - 1, y = t[1] - 1;g[x].emplace_back(y, t[2]);}作者:力扣官方题解
链接:https://leetcode.cn/problems/network-delay-time/solutions/909575/wang-luo-yan-chi-shi-jian-by-leetcode-so-6phc/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。vector<int> dismin(n + 1, INT_MAX / 2);vector<bool> visited(n + 1, false);dismin[k] = 0;// 优先队列<蓝点的最短距离,蓝点坐标>小顶堆priority_queue< pair<int, int>, vector<pair<int, int> >, greater<> > que;que.push({0, k});while (!que.empty()) {int minblue = que.top().second;que.pop();// 变成白点if (visited[minblue]) continue;visited[minblue] = true;// 增加这个白点会有什么影响对于 dismin// 遍历所有与新白点连接的蓝点for (pair<int, int > a : mp[minblue]) {if (!visited[a.first] && dismin[a.first] > a.second + dismin[minblue] ) {dismin[a.first] = a.second + dismin[minblue];que.push({dismin[a.first], a.first});}}}int res = *max_element(dismin.begin() + 1, dismin.end());return res == INT_MAX / 2 ? -1 : res;
}
-
时间复杂度:O(E * (N + logE)) E为边的数量,N为节点数量
-
空间复杂度:O(log(N^2))
-
while (!pq.empty()) 时间复杂度为 E ,while 里面 每次取元素 时间复杂度 为 logE,和 一个for循环 时间复杂度 为 N 。所以整体是 E * (N + logE)
-
sort排序与大顶堆
- 优先队列
- less<>表示从上到下是递减的
- greater<>表示从上到下是递增的
#include <bits/stdc.h> using namespace std;// priority_queue // less<>表示从上到下是递减的 // greater<>表示从上到下是递增的 // 默认 不加默认less<> 大顶堆就是less<> // 如果想要头上最小需要加上greater<> void prio_int() {vector<int> strs = {5,8,2,6,1,8,2};priority_queue<int, vector<int>, less<>> que(strs.begin(),strs.end());while(que.empty()==0){cout<<que.top()<<endl;que.pop();}return; }// 优先队列的自定义 // 优先队列与传统sort的相反 void prio_string() {vector<string> strs = {"xhh", "mmcy", "mi", "xhz", "abcdef"};struct cmp{bool operator()(string a,string b){return a.size()<b.size()||(a.size()==b.size() && a>b);}};priority_queue<string, vector<string>, cmp> que(strs.begin(),strs.end());while(que.empty()==0){cout<<que.top()<<endl;que.pop();}return; }// map自动排序,unordered_map 不排序,想排序直接用 // vector<pair<int,string>>来重新装一下,再排序 void sort_map_int() {map<int, string> mp = {{1, "ab"}, {8, "zx"}, {5, "ac"}, {4, "ae"}};for (auto a : mp) {cout << a.first << "->" << a.second << endl;}return ; }// sort pair使用 a.first a.second // 类型使用auto肯定是对的,但是可能没有提示first、second void sort_pair_int() {vector<pair<int, string>> test_vector = {{5, "abc"}, {1, "ac"}, {1, "ad"}, {2, "ac"}};sort(test_vector.begin(), test_vector.end(), [](auto a, auto b) {return (a.first > b.first || (a.first == b.first && a.second > b.second));});for (auto a : test_vector ) {cout << a.first << "->" << a.second << endl;}return ; }void sort_vector_int() {vector<int> test_vector = {5, 4, 9, 7};sort(test_vector.begin(), test_vector.end(), [](auto a, auto b) {return a > b;});for (auto a : test_vector ) {cout << a << " ";}cout << endl;return ; }void sort_vector_vector_int() {vector<vector<int>> test_vector = {{1, 2}, {9, 8}, {1, 3}, {8, 2}, {6, 5}};sort(test_vector.begin(), test_vector.end(), [](auto a, auto b) {return (a[0] < b[0] || (a[0] == b[0] && a[1] < b[1]));});for (auto a : test_vector ) {for (auto b : a) {cout << b << " ";}cout << endl;}return ; }int main() {sort_vector_int();cout << "****************" << endl;sort_vector_vector_int();cout << "****************" << endl;sort_pair_int();cout << "****************" << endl;sort_map_int();cout << "****************" << endl;prio_string();cout << "****************" << endl;prio_int(); }
1、743. 网络延迟时间
有 n 个网络节点,标记为 1 到 n。
给你一个列表 times,表示信号经过 有向 边的传递时间。 times[i] = (ui, vi, wi),其中 ui 是源节点,vi 是目标节点, wi 是一个信号从源节点传递到目标节点的时间。
现在,从某个节点 K 发出一个信号。需要多久才能使所有节点都收到信号?如果不能使所有节点收到信号,返回 -1 。
示例 1:
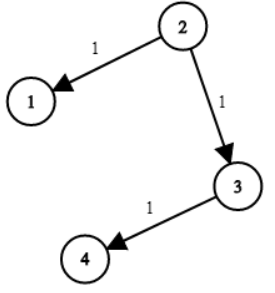
输入:times = [[2,1,1],[2,3,1],[3,4,1]], n = 4, k = 2
输出:2
示例 2:
输入:times = [[1,2,1]], n = 2, k = 1
输出:1
示例 3:
输入:times = [[1,2,1]], n = 2, k = 2
输出:-1
提示:
1 <= k <= n <= 1001 <= times.length <= 6000times[i].length == 31 <= ui, vi <= nui != vi0 <= wi <= 100- 所有
(ui, vi)对都 互不相同(即,不含重复边)
/*普通版本
*/class Solution {
public:int networkDelayTime(vector<vector<int>>& times, int n, int k) {vector<int> dp(n + 1, INT_MAX / 2);dp[k] = 0;vector<vector<int>> dis(n + 1, vector<int>(n + 1, INT_MAX / 2));for (auto& a : times) {dis[a[0]][a[1]] = a[2];}vector<int> visited(n + 1, false);//for(int i = 0;i<=n;i++){while(1) {int blue = 0;for (int i = 0; i <= n; i++) {if (!visited[i] && dp[blue] > dp[i]) {blue = i;}}// 再次遇到说明最小值就是0了,结束了if(visited[blue]) break;visited[blue] = true;for (int i = 0; i <= n; i++) {if (dp[i] > dp[blue] + dis[blue][i]) {dp[i] = dp[blue] + dis[blue][i];}}}int res = *max_element(dp.begin() + 1, dp.end());return res == INT_MAX / 2 ? -1 : res;}
};// 堆优化版本
class Solution {
public:int networkDelayTime(vector<vector<int>>& times, int n, int k) {priority_queue<pair<int, int>, vector<pair<int, int>>, greater<>> que;// que.push({k,0});que.push({0, k});vector<bool> visited(n + 1, false);vector<int> dp(n + 1, INT_MAX / 2);dp[k] = 0;while (!que.empty()) {auto blue = que.top();que.pop();// 这里不用想那么多:看见置true直接在前面加判断if( visited[blue.second]) continue;visited[blue.second] = true;for (auto& a : times) {// 这里直接取头节点不是这个blue的直接跳过,已经为白的直接跳过// 目的是为了取最小的蓝if (a[0] != blue.second || visited[a[1]] )continue;if (dp[a[1]] > dp[blue.second] + a[2]) {dp[a[1]] = dp[blue.second] + a[2];que.push({dp[a[1]], a[1]});}}}int res = *max_element(dp.begin() + 1, dp.end());return res == INT_MAX / 2 ? -1 : res;}
};
2、1334. 阈值距离内邻居最少的城市
- 直接使用堆优化:注意双向图即可
有 n 个城市,按从 0 到 n-1 编号。给你一个边数组 edges,其中 edges[i] = [fromi, toi, weighti] 代表 fromi 和 toi 两个城市之间的双向加权边,距离阈值是一个整数 distanceThreshold。
返回能通过某些路径到达其他城市数目最少、且路径距离 最大 为 distanceThreshold 的城市。如果有多个这样的城市,则返回编号最大的城市。
注意,连接城市 i 和 j 的路径的距离等于沿该路径的所有边的权重之和。
示例 1:
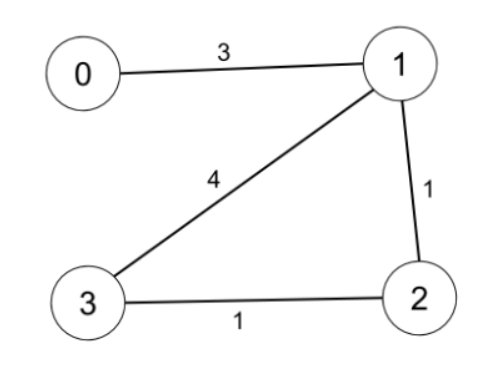
输入:n = 4, edges = [[0,1,3],[1,2,1],[1,3,4],[2,3,1]], distanceThreshold = 4
输出:3
解释:城市分布图如上。
每个城市阈值距离 distanceThreshold = 4 内的邻居城市分别是:
城市 0 -> [城市 1, 城市 2]
城市 1 -> [城市 0, 城市 2, 城市 3]
城市 2 -> [城市 0, 城市 1, 城市 3]
城市 3 -> [城市 1, 城市 2]
城市 0 和 3 在阈值距离 4 以内都有 2 个邻居城市,但是我们必须返回城市 3,因为它的编号最大。
示例 2:
输入:n = 5, edges = [[0,1,2],[0,4,8],[1,2,3],[1,4,2],[2,3,1],[3,4,1]], distanceThreshold = 2
输出:0
解释:城市分布图如上。
每个城市阈值距离 distanceThreshold = 2 内的邻居城市分别是:
城市 0 -> [城市 1]
城市 1 -> [城市 0, 城市 4]
城市 2 -> [城市 3, 城市 4]
城市 3 -> [城市 2, 城市 4]
城市 4 -> [城市 1, 城市 2, 城市 3]
城市 0 在阈值距离 2 以内只有 1 个邻居城市。
/*无向图的堆优化djikstra算法:
*/
class Solution {
public:int target(int n, vector<vector<int>>& edges, int distanceThreshold,int k) {priority_queue<pair<int, int>, vector<pair<int, int>>, greater<>> que;que.push({0, k});vector<int> dis(n, INT_MAX / 2);dis[k] = 0;vector<bool> visited(n, false);while (!que.empty()) {int blue = que.top().second;que.pop();if (visited[blue])continue;visited[blue] = true;for (auto& a : edges) {if (a[0]==blue && dis[a[1]] > dis[a[0]] + a[2]) {dis[a[1]] = dis[a[0]] + a[2];que.push({dis[a[1]], a[1]});}if (a[1]==blue && dis[a[0]] > dis[a[1]] + a[2]) {dis[a[0]] = dis[a[1]] + a[2];que.push({dis[a[0]], a[0]});}}}int res = 0;for (auto& a : dis) {if (a <= distanceThreshold)res++;}return res;}int findTheCity(int n, vector<vector<int>>& edges, int distanceThreshold) {int res = INT_MAX / 2;int resdex = 0;for (int i = 0; i < n; i++) {int mid = target(n, edges, distanceThreshold, i);if (mid <= res) {res = mid;resdex = i;}}return resdex;}
};