论文阅读:2024 ACM SIGSAC Membership inference attacks against in-context learning
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
Membership inference attacks against in-context learning
https://arxiv.org/pdf/2409.01380
https://www.doubao.com/chat/4030440311895554
速览
这篇论文主要研究了大语言模型中上下文学习(ICL)的隐私安全问题,提出针对ICL的成员推理攻击方法,并探索了相应的防御策略。
- 研究背景:大语言模型发展迅速,但定制模型时计算效率低,ICL作为新方法,通过在输入中添加提示(prompt)来让模型学习,无需更新参数。然而,ICL存在隐私风险,成员推理攻击(MIA)可判断数据样本是否用于模型训练,现有基于概率的攻击在模型只返回生成文本时效果不佳,而本文聚焦于仅基于生成文本的成员推理攻击。
- 攻击方法
- GAP攻击:基于模型对训练数据可能的过拟合现象,将模型正确识别的样本归为“成员”,错误识别的归为“非成员”,但该方法效果不理想。
- Inquiry攻击:直接询问语言模型是否见过特定样本,根据模型回答判断样本成员身份。
- Repeat攻击:利用模型的记忆能力,给模型输入目标样本的前几个单词,通过比较模型生成文本与目标样本的语义相似度判断成员身份。
- Brainwash攻击:在模型输出受限的场景下,通过持续给模型输入错误答案,根据模型接受错误答案所需的查询次数判断样本成员身份。
- 实验评估
- 实验设置:在4种语言模型(GPT2-XL、LLaMA、Vicuna、GPT-3.5 )和3个基准数据集(AGNews、TREC、DBPedia)上进行实验,重复实验500次,用优势值(Advantage)和对数尺度ROC分析评估攻击性能。
- 实验结果:Brainwash和Repeat攻击在大多数情况下表现出色;演示示例数量增加会降低Repeat和Brainwash攻击性能;演示示例在提示中的位置也会影响攻击性能,中间位置的示例对攻击更具抗性;不同版本的GPT-3.5对攻击的抗性不同,没有一个版本能抵御所有攻击。
- 混合攻击:结合Brainwash和Repeat攻击的优点,训练一个两层神经网络作为攻击模型,该混合攻击在不同场景下都表现良好,优于单个攻击方法。
- 防御策略
- 基于指令的防御:让模型设计防止泄露提示相关信息的指令,但该指令对不同攻击和数据集的防御效果不同。
- 基于过滤的防御:根据Repeat攻击原理,修改模型输出以降低其性能,但对其他攻击无效。
- 基于差分隐私(DP)的防御:用DP生成合成演示示例,可降低Repeat攻击效果,但对Brainwash攻击效果有限。多种防御策略结合能更有效地减少隐私泄露。
- 研究结论:提出了首个针对ICL的纯文本成员推理攻击,分析了影响攻击效果的因素,探索的防御策略为提示设计和防御机制提供了参考,但仍需更全面通用的防御策略。
论文阅读
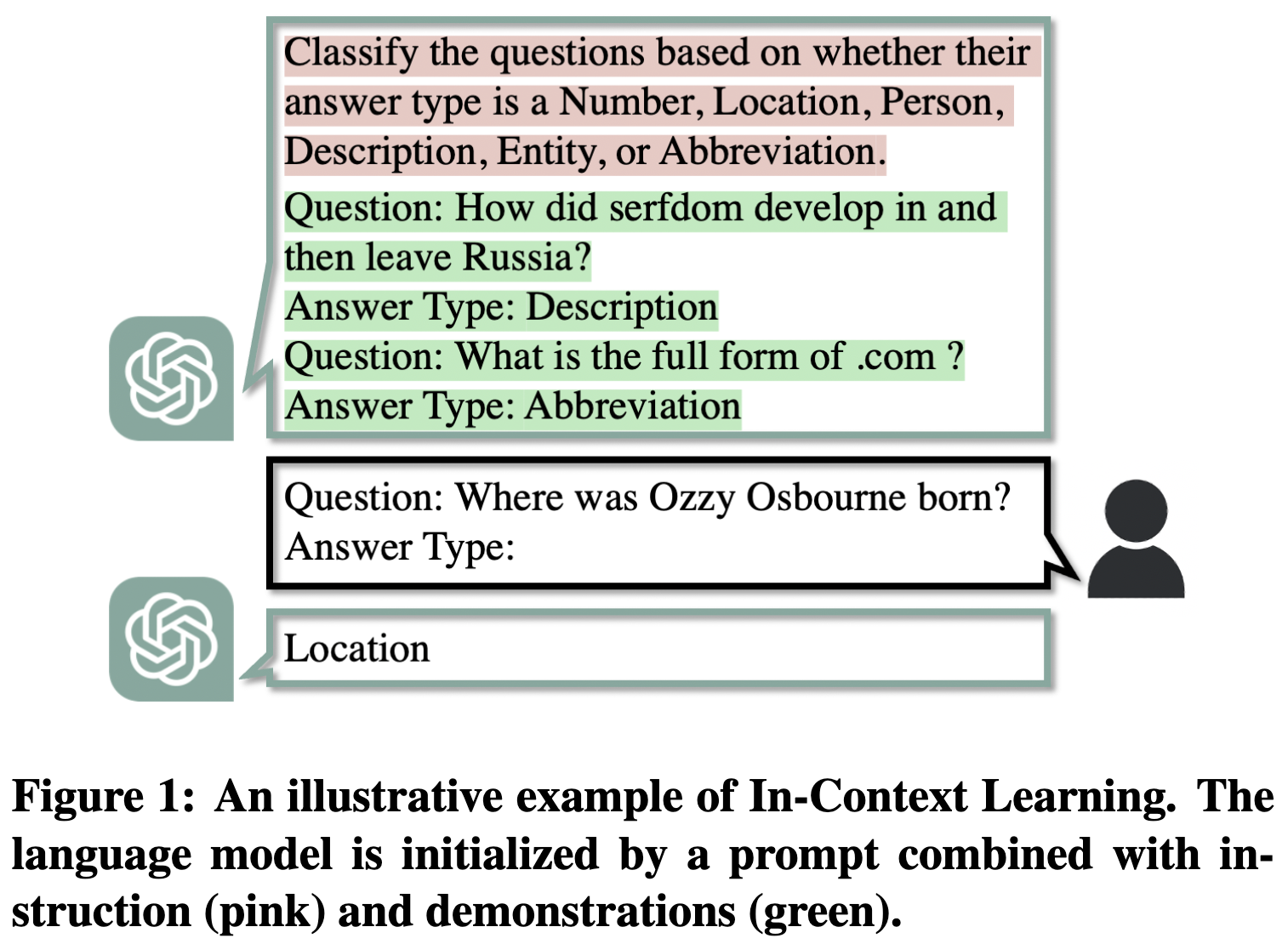

-
内容:展示了上下文学习(ICL)的一个示例。在这个示例中,语言模型要完成的任务是根据问题的答案类型进行分类,比如答案类型可能是数字(Number)、地点(Location)、人物(Person)、描述(Description)、实体(Entity)或缩写(Abbreviation) 。粉色部分是任务指令,告诉模型要做什么;绿色部分是两个示例,也就是演示(demonstration)。模型会根据这些指令和示例来学习如何回答问题。当遇到新问题“Where was Ozzy Osbourne born?”时,模型会按照之前示例的格式和学到的知识来判断答案类型。
-
作用:帮助理解ICL的工作方式,它通过在输入中添加提示(包含指令和演示示例),让语言模型在不更新自身参数的情况下,通过类比示例来完成特定任务。这种方式和传统的模型训练不同,不是通过大量更新参数来学习,而是利用这些额外的上下文信息进行学习。


-
内容:介绍了GAP攻击的具体过程。假设现在有一个要判断的目标样本,把这个样本输入到模型中,然后观察模型的回答。如果模型给出的答案是正确的,就认为这个样本是模型训练数据(这里指用于构建提示的样本集合)中的成员;如果答案错误,就认为它不是成员。比如问题“How did serfdom develop in and then leave Russia?”,模型回答“Description”,答案正确,该样本可能被判定为成员;而对于问题“Where was Ozzy Osbourne born?”,如果模型回答“Person”(错误答案),则该样本被判定为非成员。
-
作用:作为一种成员推理攻击(MIA)的基线方法,展示了一种简单直接的判断样本是否属于模型训练数据的思路。虽然这种方法在实际应用中效果不太好,尤其是对于像GPT-3.5这样性能较好的模型,但它为后续更复杂有效的攻击方法提供了对比和参考。