MySQL索引和B+Tree的关系
MySQL索引和B+Tree的关系
一、B+Tree 数据结构基础
Mysql InnoDB 引擎的索引默认基于B+Tree(平衡多路查找树)实现,其结构设计转为磁盘I/O优化(磁盘一次I/O,读取一个数据页,通常是16KB)
1.1、核心特点
1、层级少,通常3-4层即可支撑千万级别的数据(减少磁盘I/O次数)
2、非叶子节点存 索引键,仅用于导航,不存完整数据
3、叶子节点存完整数据行/主键id;叶子节点间通过双向链表链接,支持高效范围查询
4、平衡结构,插入/删除时自动调整,避免偏树导致查询变慢
二、数据页
InnoDB以数据页为最小存储单位(默认16KB),B+Tree的所有节点(根、子、叶子)都被封装成数据页存储在磁盘上,数据页不仅包含B+Tree的索引键和指针,还包含页头、页尾等元数据,用于管理页面完整性和逻辑关系

2.1、数据页与节点的关系
B+Tree 的 根节点 = 一个标记为 “根节点类型” 的数据页;根节点(第1层):存储"大范围"索引键数组(如首字母/首字分组) + 子节点指针数组
B+Tree 的 子节点 = 一个标记为 “子节点类型” 的数据页;子节点节点(中间层):存储"中范围"索引键数组(如张姓下的细分) + 子节点指针数组
B+Tree 的 叶子节点 = 一个标记为 “叶子节点类型” 的数据页;叶子节点(最后层):存储"具体值"数组 + 主键ID/SQL记录 数组 (区分非聚簇索引和聚簇索引)
非叶子节点(根节点、子节点)中存储的子节点指针,本质就是子节点所在数据页的物理磁盘地址(或内存地址,若数据页已被缓存),就是子节点对应数据页的页号(Page Number),InnoDB会将磁盘空间划分为连续的16KB块,每个块分配一个唯一的页号,通过页号可直接定位到磁盘上的数据页的位置
2.2、指针的工作流程(查询时)
当MySQL需要通过根节点的指针访问子节点时,步骤如下:
解析根节点数据页中的指针值(如201) —> 得到子节点的数据页号,通过InnoDB的 页表(记录页号与磁盘物理地址的映射),将页号201转换为磁盘的物理地址(如 /var/lib/mysql/test/user.idb 文件的第201 x 16KB偏移处);发起磁盘I/O请求,将页号201的数据页加载到内存的 缓冲区(Buffer Pool)中;继续遍历子节点的数据页,重复上述过程,直至找到叶子节点
三、有索引 vs 无索引的查询区别
索引的核心价值是 避免全表扫描,通过 B+Tree 直接定位数据
3.1、无索引查询(全表扫描)
执行过程:
查询 id = 3 —> 扫描数据页1 —> 扫描数据页2 —> 扫描数据页3 —> 找到结果(无匹配) (无匹配) (匹配成功)
3.2、有索引查询(B+Tree 定位)
聚簇索引执行过程:
查询 id = 3 —> 索引根节点(3命中) —> 子节点 —> 叶子节点(直接存储完整sql) —> 找到结果
非聚簇索引执行过程:
查询 id = 3 —> 索引根节点(3命中) —> 子节点 —> 叶子节点(存储主键id) —> 回表 —> 二次查询聚簇索引 —>找到结果
叶子节点中索引键和 主键id/完整sql行 是一一对应的关系,以键值对的形式存储(聚簇索引和非聚簇索引都是),因为主键是唯一的,可以保证索引键找到唯一的数据。
四、聚簇索引和非聚簇索引
InnoDB中索引分为 聚簇索引 和 非聚簇索引(也叫二级索引),核心差异在于:叶子节点存储的内容 和 与数据的关联方式
4.1、聚簇索引
聚簇索引 是 索引与物理数据存储在一起 的索引,叶子节点直接存储 完整的行数据。InnoDB中主键默认是聚簇索引(当建表为明确声明主键id,InnoDB会选择 非空唯一索引 替代显示主键,若没有非空唯一索引,InnoDB会自动生成隐含 Row ID替代显示主键)
核心特点:
1、数据即索引:数据物理存储顺序与主键索引顺序一致(按主键升序排列)2、查询效率最高:通过主键查询时,无需二次查找,直接返回数据3、一个表只有一个:聚簇索引是数据的物理存储方式,无法创建多个
4.2、非聚簇索引
非聚簇索引 是一种与数据物理存储顺序无关的索引结构,其核心作用是通过建立 索引键 与 数据物理位置 的映射关系,快速定位到目标数据,从而提升查询效率;普通索引、唯一索引、复合索引都是非聚簇索引
核心特点:
1、索引与数据分离:非聚簇索引的叶子节点仅存主键,不存完整数据2、需 回表:通过非聚簇索引查询时,若需完整数据,必须二次查询聚簇索引(回表)3、一个表可创建多个非聚簇索引
非聚簇索引优化:覆盖索引(避免回表)
非聚簇索引的 回表 会增加开销,可通过 覆盖索引 优化,若查询的字段都在非聚簇索引中(索引键 + 主键),则无需回表。例如:SELECT id, name FROM User WHERE name = ‘小a’; 非聚簇索引idx_user_name 已包含 name 和 id,直接返回结果,无需回表。
五、数据量很大时,B+Tree层级为什么不会很多?
B+Tree 是 多路平衡树,与二叉树(每层最多2个节点)不同,B+Tree的每个节点可以存储多个索引键(取决于节点大小、键值大小,节点通常为16KB的数据页),这使得树的层级增长非常缓慢
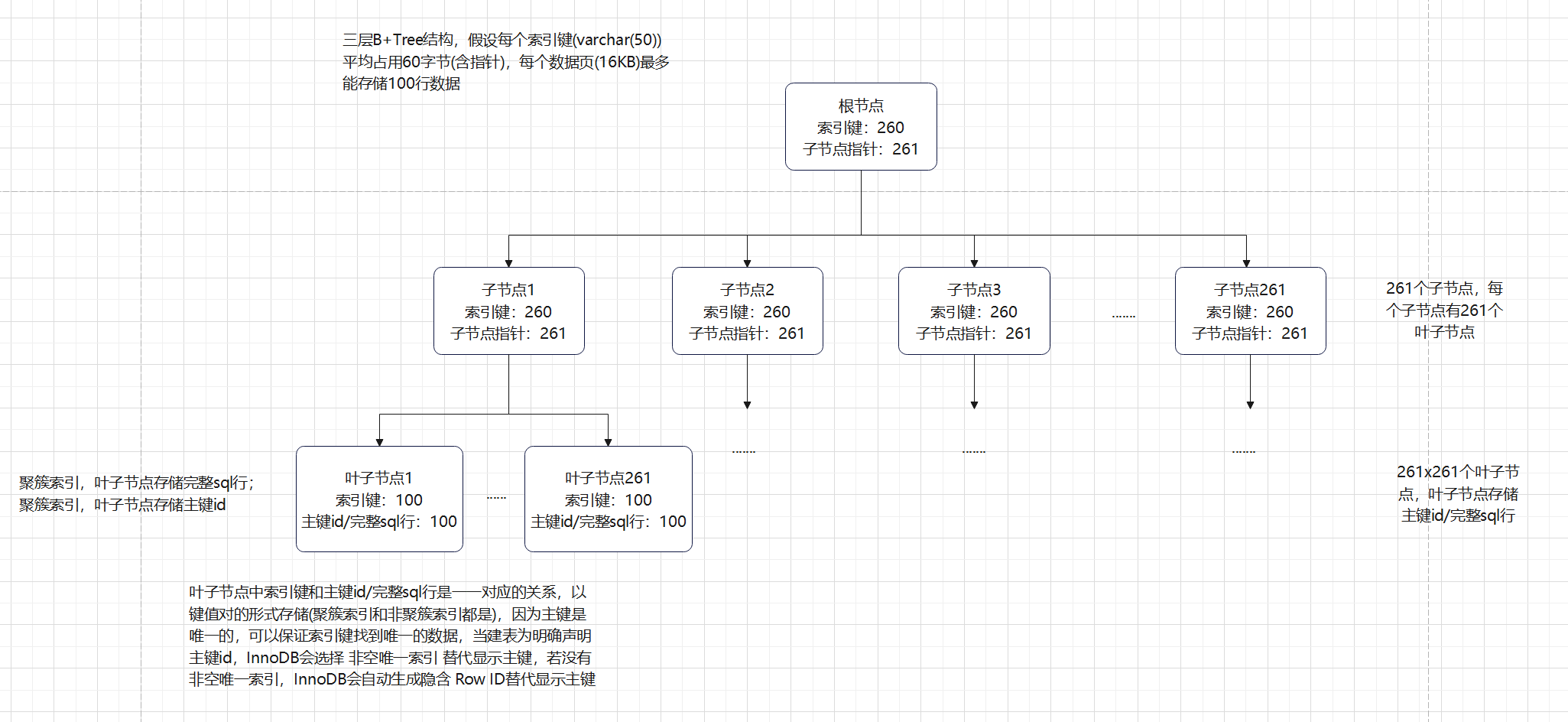
5.1、层级计算示例(以16KB节点、varchar(50)索引键、三层树为例):**
假设每个索引键(varchar(50))平均占用60字节(含指针),16KB的节点可存储约260个索引键(16*1024 / 60 约等于 260), 260个索引键对应261个子节点指针,那么
1层树:根节点,最多存储260个索引键;
2层树:子节点,最多存储 261 * 261 = 68121个索引键
3层树:叶子节点,假设每个数据页(16KB)最多能存储100行数据,那么三层最多约存储681万行数据
如果是4层树,每个数据页(16KB)还是最多能存储100行数据,那么最多约存储 1x261x261x261x100 行数据
六、数据量很大时,varchar类型的索引查找的key越长,效率会下降吗?
不会,因为 B+Tree 始终保持平衡,层级最多3-4层,查找磁盘I/O次数固定3-4次;varchar索引的比较是:前缀匹配 + 字典序,与字符串长度无关,如 张三丰 和 张 的比较逻辑是一致的
七、B+Tree的生命周期
MySQL中的 B+Tree 索引是预先创建并持久化存储的,并非根据每次查询动态生成或销毁。当你为name字段创建非聚簇索引时(CREATE INDEX idx_name ON User(name); ),MySQL会立即在磁盘上构建并存储一颗 B+Tree, 包含所有name字段的值及其对应的主键ID
7.1、B+Tree生命周期**
1、创建:CREATE INDEX时生成,或表创建时随主键自动生成(聚簇索引)
2、存在:只要索引未被删除(DROP INDEX),B+Tree就永远存储在磁盘中
3、更新:数据增删改时自动更新,如插入 name = 王五 的记录时,MySQL会将其插入索引树的对应位置,并保持树平衡
4、销毁:只要执行 DROP INDEX 或 删除表时,B+Tree才会被删除
7.2、B+Tree核心特点
1、一次创建,长期使用:B+Tree在 CREATE INDEX 时生成,之后所有设计name的查询,无论条件时 张三 还是 李四,都复用这棵树
2、持久化存储:B+Tree存储在磁盘的索引文件中,不会因查询结束或时间推移而销毁
3、自动维护:当数据发生增删改时,MySQL会自动更新索引树的结构,保持树平衡,且无需人工干预
7.3、为什么不需要为每个查询创建新树?
1、性能代价太大:B+Tree需要遍历全表数据并排序,百万级表耗时可达分钟级,若每次查询都重建,性能会急剧下降
2、数据一致性:若每个查询生成独立的树,可能导致不同查询看到的数据不一致,如刚插入的数据在新树中存在,旧树中不存在
3、空间浪费:为每个查询创建独立的树会占用大量磁盘空间,索引大小通常时数据量的50%-100%
八、非叶子节点中索引键和子节点指针的关系
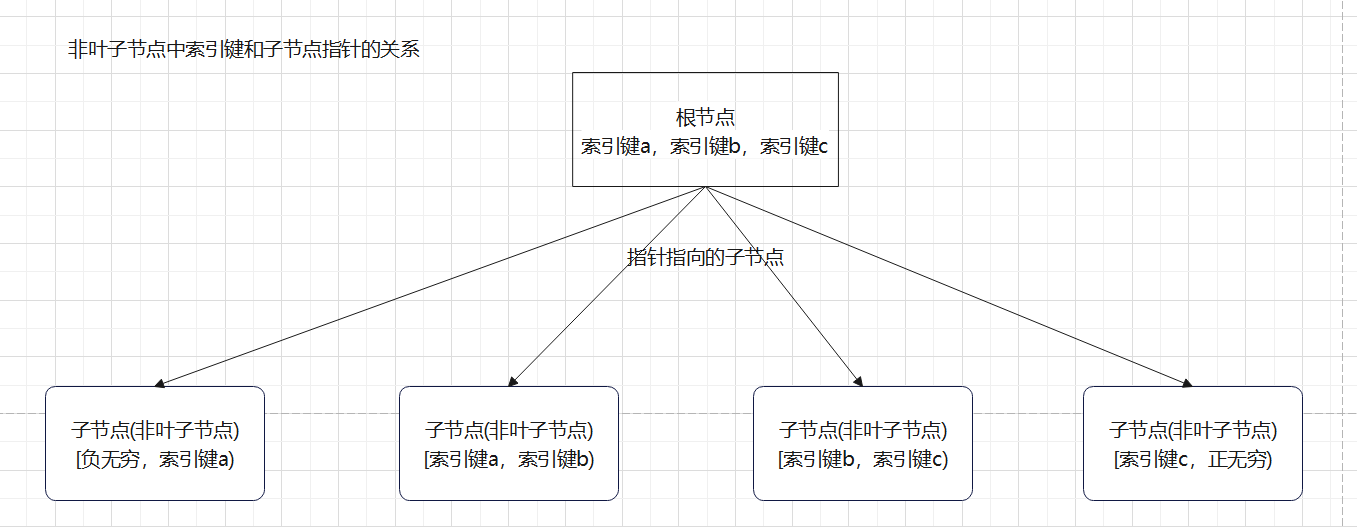
B+Tree 非叶子节点的存储逻辑是:每个节点包含 索引键列表 和 子节点指针列表,且子节点指针列表的长度 = 索引键列表长度 + 1,即索引键:子节点指针 = N : N + 1
非叶子节点的索引键本质上是 范围分隔符,它通过 左闭右开 的规则定义了子节点的范围,B+Tree的非叶子节点中,每个索引键K对应的指针指向的子节点,存储的是所有小于等于K且大于前一个索引键的索引键范围。
这种 隐性范围, 通过索引键的排序自然形成,无需额外存储指针结束位置
8.1、索引键与子节点指针的N:N+1映射实现原理
底层物理存储结构:双数组模型
B+Tree的非叶子节点本质是一个16KB的数据页,内部按固定格式存储 索引键 和 子节点指针,核心是两个并行数组:
索引键数组(Key Array):存储用于分隔范围的索引键,如varchar类型的 李、张、赵子节点指针数组(Pointer Array):存储指向子节点的磁盘地址(每个指针占8字节,64为系统)
8.2、存储顺序
子节点指针数组 和 索引键数组 按:指针1 -> 键1 -> 指针2 -> 键2 … ->键n -> 指针n+1 的顺序连续存储在数据页中
实例解析:3个索引键对应4个指针的存储细节(逻辑结构,便于理解)

8.3、逻辑解析:如何通过双数组实现范围映射?
MySQL读取非叶子节点时,会按:指针 -> 键 -> 指针 的顺序解析双数组,自动建立 范围 - 指针 的映射关系,规则如下:
指针P1:对应范围[负无穷, 键1),即所有小于 李 的索引键
指针P2:对应范围[键1, 键2),即大于等于 李 且小于 张 的索引键
指针P3:对应范围[键2, 键3),即大于等于 张 且小于 赵 的索引键
指针P4:对应范围[键3, 正无穷),即所有大于等于 赵 的索引键
解析流程,以查询 name = '周八’为例:
1、加载非叶子节点到内存,解析出指针数组[P1, P2, P3, P4] 和 索引键数组 [李, 张, 赵]
2、按字典序比较目标 周八 与 索引键
周八 > 李 -> 排除 P1周八 > 张 -> 排除 P2周八 > 赵 -> 排除 P3匹配搭配最后一个指针P4,跳转至子节点D
8.4、数据变更时如何保持 索引键数:子节点指针数 = N:N+1 的结构
当插入/删除索引键时,MySQL会自动调整双数组结构,维持 子节点指针数 = 索引键数 + 1 的关系:
1、插入索引键,例如在 张 和 赵 之间插入 王,会同时在指针数组中插入一个新指针,此时结构变为:P1 -> 李 -> P2 -> 张 -> P3 ->王 -> P4 -> 赵 -> P5(4个键 + 5个指针)
2、删除索引键,例如删除 张,会同时删除对应指针,此时结构变为:P1 -> 李 -> P2 -> 赵 -> P3(2个键 + 3个指针)
3、节点分裂/合并:当节点满时,会分裂为两个节点;当节点过空时,会与相邻节点合并,分裂/合并时仍保持索引键数:子节点指针数 = N:N+1 的结构