Vllm-0.10.1:通过vllm bench serve测试TTFT、TPOT、ITL、E2EL四个指标
一、KVM 虚拟机环境
GPU:4张英伟达A6000(48G)
内存:128G
海光Cpu:128核
大模型:DeepSeek-R1-Distill-Qwen-32B
推理框架Vllm:0.10.1
二、四个性能指标介绍
2.1、TTFT:Time to First token
首次生成token时间(ms),TTFT 越短,用户体验越好,TTFT 受 prompt 长度影响很大,如果输入的prompt越长,TTFT就越长。
2.2、TPOT:Time per output token
除首token之后,每个 token 的平均生成时间(ms),TPOT 反映模型的解码速度,受 GPU 性能、KV Cache、batch size 影响。
2.3、ITL:Inter-Token Latency
两个连续 token 之间的实际时间间隔(ms),如果 ITL 波动大,说明生成不平稳。
2.4、E2EL:End-to-End Latency
从首token到最后token完成的全部时间(ms)
E2EL=TTFT + TPOT × 输出长度
2.5举个例子
假设你问模型:“请写一篇 1000 字的作文。”
TTFT:800ms(你等了 0.8 秒看到第一个字)
TPOT:60ms(每个字平均 60 毫秒)
ITL:[58, 62, 59, 70, 57, ...](有时快,有时慢)
E2EL:800 + 60 × 999 ≈ 60.74 秒
→ 你等了 1 分钟才看到完整答案。
2.6、优化目标
想优化 | 关注指标 | 方法 |
让模型“更快响应” | TTFT | 减少 prompt 长度、启用 chunked prefill、优化 KV Cache |
让回答“说得更流畅” | TPOT | 升级 GPU、使用 vLLM、减少 batch size |
让生成“更稳定” | ITL | 避免资源争抢、使用 PagedAttention |
让整体“更快完成” | E2EL | 降低 TTFT 和 TPOT,或减少输出长度 |
三、测试过程
3.1、启动命令
vllm serve "/mnt/data/models/DeepSeek-R1-Distill-Qwen-32B" \--host "127.0.0.1" \--port 9400 \--gpu-memory-utilization 0.7 \--served-model-name "qwen32b" \--tensor-parallel-size 4 \--chat-template "/mnt/data/models/qwen32_nonthinking.jinja" \--chat-template-content-format "string" \--enable-chunked-prefill \--max-model-len 65536 \--max-num-seqs 32 \--max-num-batched-tokens 131072 \--block-size 32 \--disable-log-requests3.1.1、如何设置max-model-len?
max-model-len最大可以设置为131072(对应config.json的max_position_embeddings)。
哪max-model-len到底设置多大合适呢?
场景 | 推荐 max-model-len |
普通对话、摘要 | 32768 |
长文档处理 | 65536 |
超长上下文(如整本书) | 131072 |
我的应用牵涉长文档处理,所以我采用65536。
3.1.2、如何设置max-num-batched-tokens?
max-num-batched-tokens 占用显存,利用下面的公式来计算max-num-batched-tokens设置多大合适?
KV Cache Size (bytes)=2×num_layers×num_kv_heads×head_dim×dtype_size*max-num-batched-tokens
=2*64*8*128*2*131072
=32 GB
大概每张GPU有8G显存用户kv缓存。
剩余:48*0.7-16-8=9.6G(用于其他,如调度开销)
参数 | 含义 | 范围 |
--max-model-len | 单个请求的最大 token 数(prompt + 生成) | 单 sequence |
--max-num-batched-tokens | 所有并发请求的 token 总数上限(用于批处理调度) | 整个 batch |
3.2、测试命令(sharegpt )
vllm bench serve \--backend vllm \--base_url http://127.0.0.1:9400 \--model qwen32b \--tokenizer /mnt/data/models/DeepSeek-R1-Distill-Qwen-32B \--endpoint-type openai-chat \--endpoint /v1/chat/completions \--dataset-name sharegpt \--dataset-path /mnt/data/tools/vllm/ShareGPT_V3_unfiltered_cleaned_split.json \--sharegpt-output-len 1024 \--percentile-metrics ttft,tpot,itl,e2el \--metric-percentiles 95,99 \--num-prompts 16 \--request-rate 8我的应用要求输出token都比较大,所以我设置成1024。
注:sharegpt-output-len不要设置2048及以上,否则报
Token indices sequence length is longer than the specified maximum sequence length for this model (29557 > 16384). Running this sequence through the model will result in indexing errors
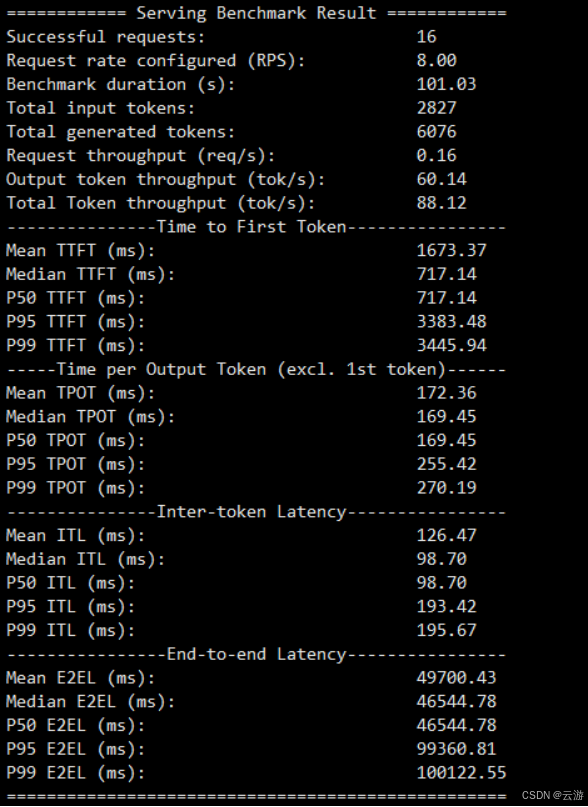
3.2、测试结果