ElasticSearch学习笔记
与solr对比
ES开箱即用,solr安装略微复杂
solr利用zookeeper进行分布式管理,而ElasticSearch自身带有分布式协调管理功能
solr支持更多格式的数据,比如json,xml,csv,elasticSearch支持json文件格式
solr官方提供的功能更多,而elasticSearch本身更注重核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana支撑
solr查询快,但更新索引慢(插入删除慢),用于电商等查询多的应用;ES建立索引快,实时性查询快,
solr比较成熟,有更大,更成熟的用户,开发和贡献者社区
ElasticSearch安装
下载
官网下载,版本8.1.3
安装
解压就可以使用
目录:
bin:启动文件
config:配置文件
lib:相关JAR包
modules:功能模块
plugins:插件
使用
熟悉目录
bin 启动文件 config 配置文件 log4j2:日志配置文件 jvm.options:虚拟机配置 修改配置:-Xms256m -Xmx1g elasticsearch.yml:配置文件,默认端口9200
启动
修改config/elasticsearch.yml,
xpack.security.enabled: false
双击elasticsearch.bat文件
访问http://127.0.0.1:9200
安装elasticsearch head可视化插件
下载解压,在命令行工具中当前文件夹目录下使用cnpm install命令进行初始化
使用命令npm run start启动项目,访问:http://127.0.0.1:9100/
解决跨域问题:
打开config/elasticsearch.yml,
http.cors.enabled: true
http.cors.allow-origin: "*"概念
索引:类似库
文档:类似库中数据
head:数据展示工具,后面所有的查询,kibana
ELK
elasticSearch
Logstash
Kibana
也将这三个开源框架叫做Elastic Stack,收集清洗数据-分析-展示
Kibana
kibana是一个针对elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在elasticsearch索引中的数据。使用kibana,可以通过各种图标进行高级数据分析及展示。kibana让海量数据更加容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示elasticsearch查询动态。设置kibana非常简单。无需编码或额外的基础架构。
下载后解压,双击启动kibana.bat
访问测试:
汉化:修改配置文件
elasticSearch是面向文档的,关系行数据库和elasticSearch客观对比:
| Relation DB | Elastic Search |
|---|---|
| 数据库 | 索引indices |
| 表 | types(被弃用) |
| 行 | documents |
| 字段 | fields |
elasticSearch在后台把每个索引划分成多个分片,每份分片可以在集群中的不同服务器间迁移。
倒排索引
有利于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
在elasticsearch中,索引这个词被频繁使用。在elasticsearch中,索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成的。
IK分词器插件
IK分词器插件提供了两种分词规则:ik_smart最小划分,ik_max_word最细粒度划分
下载后,在elasticSearch/plugins下新建ik文件夹,把插件解压缩放进来。
这里因为我的elasticesearch版本为8.2.2,而ik最新版本才8.2.0,所以在plugin-descriptor.properties修改elasticsearch.version=8.2.2
通过命令查看ik是否在plugin中被加载
elasticsearch-plugin list
查看不同分词规则的效果:
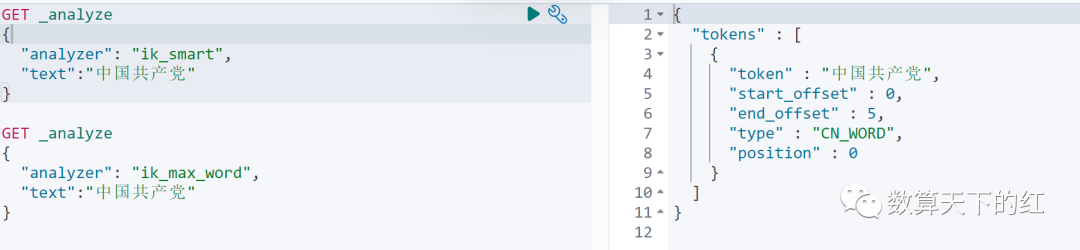
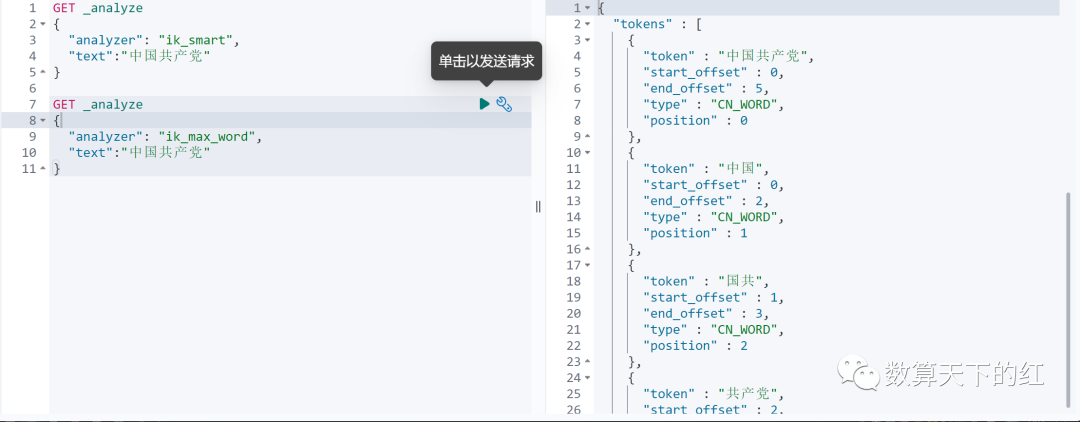
自己需要的特定的词,需要自己加入到分词器字典中。
ik分词器增加自己的目录
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">newadd.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>在ik/config中增加自己的字典文件newadd.dic,配置自己的需要的字段。
REST风格操作
PUT:创建文档(指定文档id)
url地址:localhost:9200/索引名称/类型名称/文档id
POST:创建文档(随机文档id)
url地址:localhost:9200/索引名称/类型名称
POST:修改文档
localhost:9200/索引名称/类型名称/文档id/_update
DELETE:删除文档
localhost:9200/索引名称/类型名称/文档id
GET:通过文档id查询文档
localhost:9200/索引名称/类型名称/文档id
POST:查询所有数据
localhost:9200/索引名称/类型名称/_search
基础测试
1.创建规则
PUT /test2
{"mappings": {"properties": {"name":{"type": "text"},"age":{"type": "long"},"birthday":{"type": "date"}}}
}2.获取信息
GET test2
3.创建索引,添加数据
PUT /test3/_doc/1
{"name":"joe","age":13,"birth":"1997-01-01"
}4.查看类型
GET test3
如果文档字段没有指定,那么es就会默认配置字段类型。
通过_cat命令,可以查看Es默认配置
GET _cat/health :查看健康度
修改,提交还是使用PUT即可。然后覆盖
第一种方法:1.直接修改内容
PUT /test3/_doc/1
{"name":"joe123","age":13,"birth":"1997-01-01"
}覆盖数据,版本加1
删除索引
DELETE test2
查找数据
GET _search
{"query":{"match":{"name":"joe123"}}
}查询讲解
1.控制返回参数
GET _search
{"query": {"match": {"name": "周杰伦"}},"_source": ["name","tag"]
}2.查询排序
GET _search
{"query": {"match": {"name": "周杰伦"}},"sort": [{"age": {"order": "desc"}}]
}3.指定返回数据长度
GET _search
{"query": {"match": {"name": "周杰伦"}},"sort": [{"age": {"order": "desc"}}],"from":0,"size": 2
}4.布尔值查询
GET _search
{"query": {"bool": {"must": [{"match": {"name": "周杰伦"}},{"match": {"tag": "牛"}}]}}
}must:所有条件都要符合。
GET _search
{"query": {"bool": {"should": [{"match": {"name": "周杰伦"}},{"match": {"tag": "牛"}}]}}
}should:只要符合一个就可以
GET _search
{"query": {"bool": {"must_not": [{"match": {"name": "周杰伦"}},{"match": {"tag": "牛"}}]}}
}取不满足条件的结果
5.查询范围
GET _search
{"query": {"bool": {"must": [{"match": {"name": "周杰伦"}}],"filter": [{"range": {"age": {"gte": 15}}}]}}
}gt:大于
gte:大于等于
lt:小于
lte:小于等于
6.多条件查询
GET _search
{"query": {"match": {"tag": "帅 猛"}}
}多个条件使用空格隔开,只要满足其中一个结果即可以被查出。这个时候可以通过分值进行比较。
7.精确查询
term查询是直接通过倒排索引指定的词条进程精确的查找的。
term:直接取精确的
match:会使用分词器解析。先分析文档,然后再通过分析的文档进行查询。
两个类型:text,keyword
keyword不会被分词器解析,text会被分词器解析
#分析方式采用keyword,结果不分词
GET _analyze
{"analyzer": "keyword","text": ["周杰伦 七里香"]
}
#分析方式采用standard,结果分词
GET _analyze
{"analyzer": "standard","text": ["周杰伦 七里香"]
}8.多个值匹配精确查询
GET testdb/_search
{"query": {"bool": {"should": [{"term": {"t1": {"value": "22"}}},{"term": {"t1": {"value": "33"}}}]}}
}9.高亮显示
GET testdb/_search
{"query": {"match": {"name": "周杰伦"}},"highlight": {"fields": {"name": {}}}
}自定义高亮
GET testdb/_search
{"query": {"match": {"name": "周杰伦"}},"highlight": {"pre_tags": "<p class='key' style='color:red'>", "post_tags": "</p>", "fields": {"name": {}}}
}注:elasticSearch7.15后,RestHighLevelClient被废弃,API有了较大改变,使用时请配合文档。原视频地址:
https://www.bilibili.com/video/BV17a4y1x7zq?p=20&share_source=copy_web
springboot集成
1.找到原生依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.17.4</version>
</dependency>2.初始化
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http"),new HttpHost("localhost", 9201, "http")));
client.close();3.分析这个类中的方法
配置基本的项目
一定要保证我们导入的依赖和es版本一致
索引的API操作
package com.sstx.esspringboot;import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.support.master.AcknowledgedRequest;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;@SpringBootTest
class EsSpringbootApplicationTests {@Autowired@Qualifier("restHighLevelClient")private RestHighLevelClient client;// 测试索引的创建@Testvoid createIndexTest() throws IOException {
// 创建索引请求CreateIndexRequest request= new CreateIndexRequest("sstx_index");
// 执行请求,获得相应CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);System.out.println("createIndexResponse:" + createIndexResponse);}// 获取索引@Testvoid testExistIndex() throws IOException {GetIndexRequest request = new GetIndexRequest("sstx_index");boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);System.out.println("exists:" + exists);}// 删除索引@Testvoid testDeleteIndex() throws IOException{DeleteIndexRequest request = new DeleteIndexRequest("sstx_index");AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);System.out.println(delete);}
}文档的API操作
// 测试添加文档@Testvoid testAddDocument() throws IOException {User user = new User("zhangsan", 21);
// 创建请求IndexRequest indexRequest = new IndexRequest("s_index");
// 设计规则indexRequest.id("1");indexRequest.timeout(TimeValue.timeValueSeconds(1));
//将数据放入请求IndexRequest source = indexRequest.source(JSON.toJSONString(user), XContentType.JSON);
// 客户端发送请求try {IndexResponse index = client.index(indexRequest, RequestOptions.DEFAULT);System.out.println("index:" + index.toString());System.out.println("index:" + index.status());}catch (Exception e){e.printStackTrace();}}// 测试文档是否存在@Testvoid testIsExists() throws IOException {GetRequest sstx_index = new GetRequest("s_index", "1");
//不获取返回的_source的上下文sstx_index.fetchSourceContext(new FetchSourceContext(false));sstx_index.storedFields("_none_");boolean exists = client.exists(sstx_index, RequestOptions.DEFAULT);System.out.println(exists);}// 测试文档是否存在@Testvoid testGetDocument() throws IOException {GetRequest sstx_index = new GetRequest("s_index", "1");GetResponse documentFields = client.get(sstx_index, RequestOptions.DEFAULT);
// 打印内容System.out.println(documentFields.getSourceAsString());}@Testvoid testUpdateDocument() throws IOException {UpdateRequest s_index = new UpdateRequest("s_index", "1");s_index.timeout("1s");User user = new User("张三", 13);s_index.doc(JSON.toJSONString(user), XContentType.JSON);UpdateResponse response = client.update(s_index, RequestOptions.DEFAULT);System.out.println(response);}// 删除文档@Testvoid testDeleteDocument() throws IOException {DeleteRequest deleteRequest = new DeleteRequest("s_index", "1");deleteRequest.timeout("1s");DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);System.out.println(deleteResponse.status());}// 批量插入文档@Testvoid testBulkDocument() throws IOException {BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");ArrayList<User> users = new ArrayList<>();users.add(new User("张三1", 12));users.add(new User("张三2", 13));users.add(new User("张三3", 14));users.add(new User("张三4", 15));users.add(new User("张三5", 16));users.add(new User("张三6", 17));for (int i = 0; i < users.size(); i++) {bulkRequest.add(new IndexRequest("bulk_index").id(""+(i+1)).source(JSON.toJSONString(users.get(i)), XContentType.JSON));}BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
// 是否失败System.out.println(bulkResponse.hasFailures());}// SearchRequest 搜索请求
// SearchSourceBuilder 条件构造
// HighlightBuilder 构建高亮
// TermQueryBuilder 精确查询
// xxxx QueryBuilder 对应查询命令@Testvoid testSearch() throws IOException {SearchRequest searchRequest = new SearchRequest(ESconst.ES_INDEX);
// 构建搜索条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 查询条件
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "张三4");searchSourceBuilder.query(termQueryBuilder);
// 超时searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 查询searchRequest.source(searchSourceBuilder);SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);System.out.println((JSON.toJSONString(search.getHits())));for(SearchHit documentFields: search.getHits().getHits()){System.out.println(documentFields.getSourceAsMap());}}京东搜索
项目搭建
搭建一个简单的springboot项目,前台使用狂神提供的文件。
爬取数据
爬取数据,获取请求返回的页面信息,筛选出需要的数据。
使用jsoup包
1.导入依赖
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.2</version>
</dependency>2.编写工具类HtmlParseUtil
package com.sstx.springbootesjd.utils;import com.sstx.springbootesjd.pojo.Content;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.stereotype.Component;import java.io.IOException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;@Component
public class HtmlParseUtil {public List<Content> parseJD(String keyword) throws IOException {
// 获取请求
// ajax不能获取到String requestStr = "https://search.jd.com/Search?keyword=" + keyword;
// 解析网页,就是Document对象Document document = Jsoup.parse(new URL(requestStr), 30000);
// 所有在js中能用的方法这里都可以使用Element element = document.getElementById("J_goodsList");Elements lis = element.getElementsByTag("li");List<Content> lists = new ArrayList<>();for(Element li : lis){String img = li.getElementsByClass("p-img").eq(0).attr("data-lazy-img");String price = li.getElementsByClass("p-price").eq(0).text();String title = li.getElementsByClass("p-name").eq(0).text();lists.add(new Content(title, img, price));System.out.println("img:" + img);}return lists;}
}业务编写
1.把前面编写的config放进来
package com.sstx.springbootesjd.config;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class ElasticSearchConfig {@Beanpublic RestHighLevelClient restHighLevelClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));return client;}
}2.编写service文件
package com.sstx.springbootesjd.service;import com.alibaba.fastjson.JSON;
import com.sstx.springbootesjd.pojo.Content;
import com.sstx.springbootesjd.utils.HtmlParseUtil;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.core.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.xcontent.XContentType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import javax.naming.directory.SearchResult;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;@Service
public class ContentService {@Autowiredprivate RestHighLevelClient restHighLevelClient;// 1.解析数据放入es索引中public Boolean parseContent(String keyword) throws Exception {
// 获取爬虫内容List<Content> contents = new HtmlParseUtil().parseJD(keyword);// 创建索引GetIndexRequest request = new GetIndexRequest("sstx_index");boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);if (!exists){CreateIndexRequest requestNew= new CreateIndexRequest("jd_goods");
// 执行请求,获得相应restHighLevelClient.indices().create(requestNew, RequestOptions.DEFAULT);}// 批量插入BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("2m");for(int i=0; i<contents.size();i++){bulkRequest.add(new IndexRequest("jd_goods").source(JSON.toJSONString(contents.get(i)), XContentType.JSON));}BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);return !bulk.hasFailures();}// 获取这些数据实现搜索功能public List<Map<String, Object>> searchPage(String keyword, int pageNo, int pageSize) throws IOException {if (pageNo<=1){pageNo = 1;}
// 条件搜索SearchRequest searchRequest = new SearchRequest("jd_goods");SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// 分页sourceBuilder.from((pageNo-1)*pageSize);sourceBuilder.size(pageSize);// 精准匹配TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);sourceBuilder.query(termQueryBuilder);sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));// 高亮HighlightBuilder highlighter = new HighlightBuilder();highlighter.field("title");
// 只高亮第一个,不全部高亮highlighter.requireFieldMatch(false);highlighter.preTags("<span style='color:red'>");highlighter.postTags("</span>");sourceBuilder.highlighter(highlighter);// 执行搜索searchRequest.source(sourceBuilder);SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 解析结果List<Map<String, Object>> result = new ArrayList<>();for(SearchHit documentFields: search.getHits().getHits()){// 解析高亮字段Map<String, HighlightField> highlightFields = documentFields.getHighlightFields();HighlightField title = highlightFields.get("title");
// 原来的结果Map<String, Object> sourceAsMap = documentFields.getSourceAsMap();
// 把高亮字段进行替换if (title!=null){Text[] fragments = title.fragments();String n_title = "";for (Text fragment: fragments){n_title += fragment;}sourceAsMap.put("title", n_title);}result.add(sourceAsMap);}return result;}
}3.编写controller文件
package com.sstx.springbootesjd.controller;import com.sstx.springbootesjd.service.ContentService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;import java.io.IOException;
import java.util.List;
import java.util.Map;@RestController
public class ContentController {@Autowiredprivate ContentService contentService;@GetMapping("/parse/{keyword}")public Boolean parse(@PathVariable("keyword") String keyword) throws Exception {return contentService.parseContent(keyword);}@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")public List<Map<String, Object>> search(@PathVariable("keyword") String keyword,@PathVariable("pageNo") int pageNo,@PathVariable("pageSize") int pageSize) throws IOException {return contentService.searchPage(keyword, pageNo, pageSize);}@GetMapping("/searchHighLightKeyword/{keyword}/{pageNo}/{pageSize}")public List<Map<String, Object>> searchHighLightKeyword(@PathVariable("keyword") String keyword,@PathVariable("pageNo") int pageNo,@PathVariable("pageSize") int pageSize) throws IOException {return contentService.searchPage(keyword, pageNo, pageSize);}
}