【机器学习深度学习】AI大模型高并发挑战:用户负载部署策略
目录
前言
一、高并发下的“灾难”:超过10万用户会发生什么?
二、如何避免这些问题?
2.1 策略汇总
2.2 类比理解
三、场景模拟
四、大模型高并发架构
五、总结一句话

前言
在AI时代,大语言模型(LLM)如ChatGPT或Grok正成为众多公司产品的核心。想象一下,你的AI聊天机器人突然爆火,一夜之间吸引了数百万用户。但如果系统设计时只支持10万并发用户,超过这个阈值会怎样?服务器崩溃、用户投诉如潮水般涌来,机会瞬间变成危机。作为一名AI开发者或产品经理,理解高并发问题并提前布局至关重要。
本文将围绕这一话题展开讨论:当用户访问量超过系统极限时会发生什么,以及如何通过实用策略避免这些坑。我们会用通俗的类比(如一家忙碌的餐厅)来解释复杂概念,并结合模拟场景,帮助你轻松get到要点。无论你是初入AI领域的创业者,还是经验丰富的工程师,这篇文章都能提供实操启发。
一、高并发下的“灾难”:超过10万用户会发生什么?
部署AI大模型时,高并发意味着数以万计的用户同时发送请求,比如提问、生成文本或图像。模型推理过程计算密集型,依赖GPU等资源。如果系统最大承载10万并发用户,超出后会像一辆超载的卡车——摇摇欲坠,直至翻车。
系统不会立刻完全崩溃,而是会经历一个逐步恶化的过程,通常表现为以下几个层面:
1.性能急剧下降,响应时间飙升
现象:这是最直接的表现。API接口的响应时间(Latency)从几百毫秒变成几秒甚至几十秒。用户会感觉“卡死了”。
原因:服务器的CPU、GPU、内存等资源被挤占,每个请求都需要排队等待处理。推理队列变得非常长。
- 场景模拟:顾客点餐后,等了半天菜还没上桌。有的不耐烦,直接走人。
- 现实问题:服务器资源(如CPU、GPU、内存)被耗尽,现有请求处理延迟飙升。AI模型推理本就耗时(生成一个回复可能需几秒),高并发下延迟可能从1秒变成10秒,甚至超时。用户看到“加载中”卡住不动,弃用率直线上升。
- 为什么严重? 在AI应用中,用户期望即时响应;延迟过高等于流失客户。
2.错误率上升,大量请求失败
现象:用户开始频繁看到
5xx服务器错误码,最常见的是:
503 Service Unavailable:服务不可用,通常意味着上游服务器已过载,无法处理新请求。
504 Gateway Timeout:网关超时,请求在等待后端服务响应时超时。
429 Too Many Requests:请求过多,如果系统设置了速率限制(Rate Limiting),会主动返回此错误。
原因:服务器为了保护自身不彻底崩溃,会主动拒绝(Reject)或丢弃(Drop)新的连接请求。
- 场景模拟:餐厅门口张贴“客满,请明日再来”的告示,新顾客只能望门兴叹。
- 现实问题:系统连接池或队列满载,新请求被拒绝,返回错误码如“503 Service Unavailable”。用户可能看到“服务器忙碌”或直接连接失败。
- 影响:这不只影响新用户,还可能引发负面口碑传播,尤其在社交媒体时代。
3.级联故障(Cascading Failure)
现象:一个组件的故障引发连锁反应,导致整个系统瘫痪。
原因:
数据库/缓存过载:大模型服务通常也需要访问向量数据库、传统数据库或缓存(如Redis)来获取上下文(RAG)。前端服务的拥堵会导致对这些下游依赖的请求也积压,最终可能拖垮数据库。
依赖服务崩溃:如果依赖的计费、用户认证等服务被海量请求冲垮,即使大模型本身还能勉强运行,整体服务也已不可用。
- 场景模拟:厨房设备过热,厨师忙乱出错,整个餐厅被迫关门重启。
- 现实问题:资源耗尽导致服务器使用交换空间(swap),性能急剧下降,甚至崩溃重启。AI模型的“冷启动”(重新加载模型到内存)需几分钟,进一步加剧 downtime。
- 潜在风险:数据丢失、漏洞暴露,甚至引发连锁故障(如数据库崩溃)。
4.资源耗尽,服务完全不可用
现象:服务器内存被占满(OOM, Out Of Memory),进程被操作系统杀死,服务彻底宕机,所有用户都无法访问。
原因:每个大模型推理请求都会消耗大量内存来加载模型权重和存储中间激活结果。超量的请求会耗尽所有内存,导致系统崩溃。
- 场景模拟:餐厅临时雇佣额外厨师、采购食材,但因混乱导致大量浪费,账单暴涨。
- 现实问题:云服务自动扩容时费用激增,但如果没优化,资源利用率低(如GPU闲置部分计算),白白烧钱。高并发还可能触发无效请求(如机器人刷屏),放大成本。
这些问题在真实案例中屡见不鲜:想想早期ChatGPT,以及deepseek上线时的排队机制,或某些AI工具在热点事件(如选举或体育赛事)下的崩溃。忽略高并发,就等于在AI赛道上自设绊脚石
5.用户体验和商业损失
用户流失:用户无法获得服务,会对产品的可靠性和专业性产生严重怀疑,转而使用竞争对手的产品。
品牌形象受损:公开的服务中断(Outage)会上科技新闻,对公司声誉造成负面影响。
直接收入损失:如果服务是按次付费(API Call)的,服务中断意味着直接的经济损失。
二、如何避免这些问题?
好消息是,这些问题并非不可避免。通过现代云架构和AI优化工具,你可以让系统像弹性橡皮筋一样伸缩自如。继续用餐厅类比,我们来看看如何改造这家“餐厅”成高负载下的“五星级”服务。
2.1 策略汇总
| 策略 | 描述 | 实施建议 | 益处 |
|---|---|---|---|
| 自动缩放(Auto Scaling) | 根据负载动态增加/减少服务器实例或GPU资源。 | 使用AWS Auto Scaling、Kubernetes HPA(Horizontal Pod Autoscaler),监控CPU/GPU利用率和请求队列长度。针对AI模型,可结合BentoML或Ray Serve框架实现。 | 弹性应对峰值,避免手动干预,控制成本。 |
| 负载均衡(Load Balancing) | 将请求均匀分发到多个模型实例或服务器。 | 部署Nginx、HAProxy或云负载均衡器(如Azure Load Balancer)。对于AI,使用LiteLLM的路由策略,支持多模型部署。 | 防止单一节点过载,提高整体吞吐量。 |
| 限流和队列(Rate Limiting & Queuing) | 限制每秒/分钟请求数,超出部分排队或拒绝。 | 集成Redis或API Gateway实现限流;使用消息队列如Kafka处理排队请求。AI场景下,可设置并发阈值,防止过载。 | 保护系统稳定,提供友好错误反馈(如“请稍后重试”)。 |
| 模型优化和批处理 | 减少单次推理计算负载。 | 采用模型量化、蒸馏或连续批处理(Continuous Batching),如vLLM框架支持高并发推理。 | 提升每GPU的并发能力,降低资源需求。 |
| 监控和警报 | 实时追踪系统指标,提前干预。 | 使用Prometheus、Grafana监控并发数、延迟和错误率;设置警报阈值(如并发达80%时通知)。 | 及早发现问题,预防崩溃。 |
| 依赖隔离和容错 | 将服务模块隔离,防止连锁故障。 | 在Kubernetes中使用Network Policies隔离流量;实现熔断器(Circuit Breaker)模式。 | 限制故障影响范围,提高系统韧性。 |
2.2 类比理解
继续用餐厅的例子,我们来看看怎么让这家“餐厅”应对突然涌来的200位顾客,同时保持服务顺畅。以下是通俗的解决办法和类比:
1.自动加桌(自动缩放,Auto Scaling)
- 类比:餐厅发现人多时,自动把旁边的备用房间打开,增加桌子和临时工,忙完再把备用房间关掉省钱。
- 技术方案:用云计算的自动缩放功能(比如AWS Auto Scaling)。当用户访问量超过10万,系统自动增加服务器或GPU实例,忙完再减少。
- 场景:假设高峰期是晚上6点,系统检测到请求暴增,5分钟内加10台服务器,平滑处理多出来的用户。
- 好处:不浪费资源(闲时少开服务器),高峰期也能应对。
2 分流顾客(负载均衡,Load Balancing)
- 类比:餐厅有3个分店,门口有引导员把顾客平均分到每个分店,避免一个店挤爆。
- 技术方案:用负载均衡器(如Nginx或云服务)把用户的请求均匀分到多个服务器或模型实例上。对于AI大模型,可以用工具像LiteLLM来分配请求。
- 场景:10万用户同时提问AI,负载均衡器把请求分到10个模型实例,每台服务器只处理1万请求,压力均摊。
- 好处:防止某台服务器过载,整体服务更稳定。
3 控制人流(限流和队列,Rate Limiting & Queuing)
- 类比:餐厅门口设个排号机,每分钟只让50人进去,超出的顾客拿号排队,或者礼貌告诉他们“稍后再来”。
- 技术方案:用API网关或Redis设置每秒请求上限,超出的请求进入消息队列(如Kafka)等待处理,或者返回友好提示“系统繁忙,请稍后重试”。
- 场景:如果20万用户同时访问,系统只处理10万请求,剩余的排队或被提示稍后再试,避免系统直接崩。
- 好处:保护服务器不超载,用户体验更友好。
4 优化厨房效率(模型优化和批处理)
- 类比:餐厅把菜谱简化(比如用预制菜),或者一次做一大锅菜分给多人,而不是每人单独炒一份。
- 技术方案:对AI模型做优化,比如用模型量化(减少计算量)或连续批处理(Continuous Batching,像vLLM框架),让一台GPU同时处理更多用户请求。
- 场景:原本一台GPU一次只能处理10个用户请求,优化后能处理50个,相当于餐厅效率翻了5倍。
- 好处:用更少的资源服务更多用户,节省成本。
5 实时监控(监控和警报)
- 类比:餐厅装个监控屏,实时显示有多少顾客在等、厨房忙不忙,人多时提前通知经理加人手。
- 技术方案:用Prometheus或Grafana监控服务器的CPU/GPU使用率、请求延迟等,设置警报(比如并发超8万时发邮件)。
- 场景:系统发现并发接近10万,自动报警,技术团队提前加服务器或优化配置。
- 好处:防患于未然,避免问题升级。
6 隔离故障(依赖隔离和容错)
- 类比:餐厅把厨房分成几个区域,一个区域设备坏了,其他区域还能正常做菜,不至于全停。
- 技术方案:用Kubernetes隔离服务模块,设置熔断器(Circuit Breaker),某个模块过载时自动切断,保护其他部分。
- 场景:如果AI模型的一个实例崩溃,其他实例继续服务,用户不至于完全无法访问。
- 好处:防止小问题引发大崩溃,提高系统稳定性。
- 从小做起:先用1万并发测试(像用工具Locust模拟),看看系统瓶颈在哪,逐步优化。
- 平衡成本和性能:自动缩放和优化能省钱,但高峰期加服务器会增加费用,建议预估用户增长,提前规划。
- 用户沟通:如果限流,记得给用户友好提示,比如“服务器忙,请稍后再试”,别让他们觉得系统崩了。
三、场景模拟
假设你在运营一个AI聊天机器人,部署在云端,设计最大支持10万用户同时对话。某天因为热点事件(比如新产品发布),突然有20万用户涌入:
- 没准备的情况下:系统卡顿,10万用户能正常聊天,但剩下10万用户要么等半天,要么直接看到“服务不可用”。服务器可能因为过载直接宕机,重启后模型加载又花了10分钟,用户体验很差。
- 用了以上方案:
- 自动缩放:云端检测到用户激增,5分钟内加了5台服务器,处理额外用户。
- 负载均衡:20万请求被均匀分到15台服务器,每台只处理1.3万请求,压力可控。
- 限流:超过15万的请求被排队,提示用户“稍等片刻”,避免系统崩溃。
- 模型优化:每台GPU通过批处理支持更多请求,效率翻倍。
- 监控:技术团队收到警报,提前优化配置,避免了宕机。
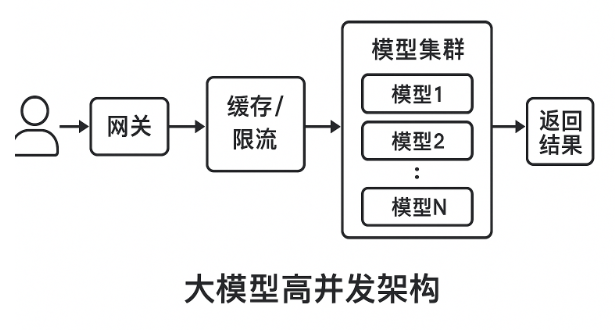
四、大模型高并发架构
五、总结一句话
超过最大并发时,要么排队,要么丢弃,要么崩溃。
解决办法就是:限流 + 负载均衡 + 缓存 + 异步队列 + 弹性扩展,并且用小模型/缓存削峰。