CVPR 2025|英伟达联合牛津大学提出面向3D医学成像的统一分割基础模型
在 2D 自然图像和视频的交互式分割领域,基础模型已引发广泛关注,这也促使人们开始构建用于医学成像的 3D 基础模型。然而,3D 医学成像存在的领域差异以及临床应用场景,要求开发一种有别于现有 2D 解决方案的专用模型。具体而言,这类基础模型应支持一套完整的工作流程,切实减少人工操作。
将 3D 医学图像视为 2D 切片序列,并复用交互式 2D 基础模型,看似简单直接,但在 3D 任务中,2D 标注过于耗时。此外,对于大规模队列分析,高精度的自动分割模型才能最大程度减少人工工作量。然而,这些模型缺乏对交互式修正的支持,也不具备对新型结构的零样本处理能力 —— 而这正是 “基础模型” 的关键特性。尽管在 3D 模型中复用预训练的 2D 骨干网络能增强零样本潜力,但它们在处理复杂 3D 结构时的性能仍落后于顶尖的 3D 模型。
2025年6月,英伟达公司联合牛津大学在CVPR 2025 在线发表题为“VISTA3D: A Unified Segmentation Foundation Model For 3D Medical Imaging”的研究论文。该研究提出了 VISTA3D(多功能成像分割与标注模型),旨在通过一个统一的基础模型应对所有这些挑战和需求。
VISTA3D 基于成熟的 3D 分割流程构建,是首个在 3D 自动分割(支持 127 个类别)和 3D 交互式分割两方面均达到最先进性能的模型,即便在大型多样化基准测试中与顶尖的 3D 专业模型相比也是如此。此外,VISTA3D 的 3D 交互式设计支持高效的人工修正,而其创新的 3D 超体素方法(通过提炼 2D 预训练骨干网络构建)则赋予了 VISTA3D 顶尖的 3D 零样本性能。作者认为,该模型、其构建方法以及相关见解,代表着在迈向具有临床实用性的 3D 基础模型道路上迈出了充满希望的一步。
由于促炎巨噬细胞向抗炎巨噬细胞的复极化受损,传统的骨组织工程材料难以在糖尿病期间恢复生理性骨重塑。
三维医学成像技术,如计算机断层扫描(CT),被广泛用于生成人体各部位的横截面体素图像。作为一种主要的解剖成像方式,它能够清晰呈现人体结构和异常组织的详细形态信息。在临床实践中,手动分割既耗时又繁琐,因此开发更优的自动分割模型一直是研究的热点领域之一。其中一个典型方向是改进网络架构,并为特定任务定制训练方案。针对每个任务,通常需要精心准备特定的训练数据集并训练专业模型,这对工程技术能力提出了较高要求。因此,一种能够 “开箱即用” 解决多种任务的模型更具应用价值。
与自然图像中存在无限多目标类别不同,CT 或 MRI 所呈现的临床相关人体正常解剖结构是有限的(如肝脏、胰腺等),因此从技术层面而言,训练一个能够支持大多数标准人体解剖结构的自动分割模型是可行的。然而在实际应用中,临床医生可能更关注罕见病变或动物数据,而由于数据稀缺,这些通常不在现有模型的支持范围内。缺乏处理这类场景的零样本能力,成为了模型的一大局限性。同时,对于手术规划等流程,模型还需支持人工介入进行修正,这一点也至关重要。
近年来,大型语言模型在各类任务中展现出强大的泛化能力,被视为基础模型。“可提示” 系统的理念随之提出,旨在实现一种能够 “开箱即用” 解决不同任务的灵活模型。在图像分割领域,“万物分割”(Segment Anything,SAM)引发了广泛关注,并取得了令人瞩目的零样本性能。在医学领域,近期研究通过模型微调,将 SAM 适配到医学成像模态中。这些基于 SAM 的方法在 2D 场景中借助交互式用户输入,取得了颇具前景的成果。但对于 3D 医学图像,此类提示(如点提示)需要绑定到每个类别、每个切片和每个扫描图像,这往往需要大量人工操作,难以应用于大规模队列数据分析。
近期的 “视频万物分割”(Segment Anything in Video,SAM2)引发了更大关注,因为 3D 扫描图像可表示为 2D 横截面图像(切片)的堆叠,而视频也是 2D 图像(帧)的堆叠。然而,实验表明,即使在 3D 医学数据集上进行了充分微调,SAM2 框架仍无法与 VISTA3D 相比,尤其是在处理复杂 3D 结构时(详见补充材料)。SAM2 主要用于追踪随时间变化的目标,但医学成像需要对体素输入进行空间一致性处理。例如,不同时间帧中的汽车仍是同一辆,但其实时 2D 横截面图像可能对应完全不同的物体,如座椅和发动机。这体现了 2D 自然图像或视频与横截面医学图像之间的巨大差异。类似地,SAM3D 通过 2D SAM 编码器逐切片提取 3D 体素特征,并结合 3D 解码器,但结果远逊于专业 3D 模型。简单地将自然图像领域的方法应用于 3D 医学图像,显然是不够的。
近期探索医学图像分割上下文学习的研究,能够在示例图像或文本的引导下分割任意类别。这看似是一种理想方案,因为它无需模型微调或耗时的人工输入。但这类方法的性能远落后于特定数据集的有监督模型(如 nnU-Net)。
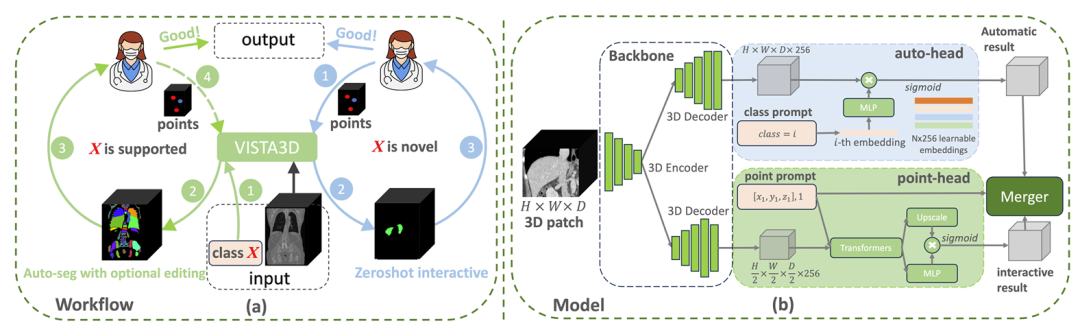
图 1. 图 (a) 展示了 VISTA3D 支持的完整人机协同工作流程。如果分割任务 X 属于 127 个支持类别(左侧绿色圆圈),VISTA3D 会执行高精度自动分割。医生可对结果进行检查,必要时借助 VISTA3D 高效编辑。如果 X 是新型类别(右侧蓝色圆圈),VISTA3D 会执行 3D 交互式零样本分割。图 (b) 展示了 VISTA3D 的架构,它包含两个分支,共享同一个图像编码器。若用户提供的类别提示属于 127 个支持类别,顶部的自动分支会启动 “开箱即用” 的自动分割功能;若用户提供 3D 点选提示,底部的交互分支会启动交互式分割功能。若两个分支同时启动,基于算法 1 的合并模块会利用交互结果对自动分割结果进行编辑。
作者认为,3D 医学图像分割基础模型应支持一套完整的工作流程(图 1 (a)),以减少人工操作,其核心能力包括:1)对常见器官或结构进行高精度自动分割;2)支持与专家的交互,以便对现有分割结果进行有效优化;3)具备零样本能力,既允许用户交互式标注未见过的类别,也能通过文本或示例引导进行上下文学习。模型应在 3D 空间中运行,因为 2D 逐切片方法不仅耗时,还可能无法充分利用 3D 视觉上下文;4)具备少样本 / 迁移学习能力,允许用户在新类别上快速微调模型,以实现精确的自动分割 —— 鉴于现有上下文学习或开放词汇分割在精度上仍落后于专业 3D 模型。
为支持这一工作流程并达到与顶尖专业模型相当的性能,模型应基于成熟的 3D 流程构建,依赖 3D 骨干网络和滑动窗口推理。但这一方向未能充分利用现有具备强大零样本能力的 2D 预训练权重(如 SAM)。复用 SAM 权重并添加轻量级 3D 适配模块看似可行,但由于冻结了大部分权重,其在多类别上的自动分割性能(与 TotalSegmentator 相比)受到限制。因此,面临的挑战是:如何构建一个既具备成熟 3D 流程优势,又能利用 2D 自然图像领域的见解和检查点来解决 3D 问题的模型。基于此目标,提出了 VISTA3D,主要贡献如下:
1.首个支持完整标注工作流程的统一基础模型,在 14 个具有挑战性的数据集(含 127 个类别)上进行基准测试,与成熟基线模型相比,在 3D 可提示自动分割和交互式编辑方面均达到最先进性能。
2.提出一种新颖的超体素方法,用于提炼 2D 基础模型以适配 3D 医学成像,将 VISTA3D 的零样本性能提升 50%,在大幅减少标注工作量的情况下,实现了最先进的 3D 零样本性能。
3.构建了一个包含 11454 次扫描的大型 CT 数据集,结合部分手动标签、伪标签和超体素,提出一种新颖的四阶段训练方案,以应对挑战,实现最先进的性能和编辑体验。
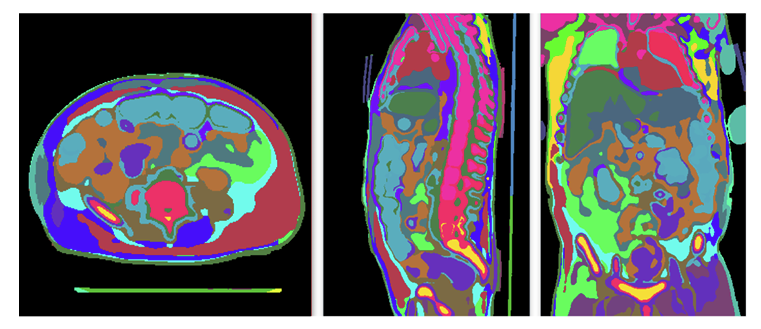
图 2. 由算法 2 生成的超体素,展示了轴位、矢状位和冠状位视图的示例。不同颜色代表不同的超体素。
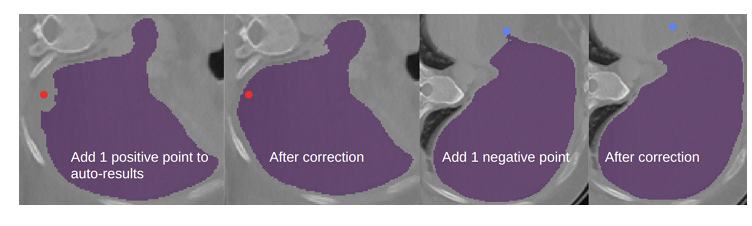
图 3. 用点修正自动分割结果。左图为肝脏自动分割结果,存在一个假阴性区域。在添加一个正点后,该假阴性区域得到了修正。第三幅图显示了另一个切片,其中存在一个假阳性区域,在添加一个负点后,该区域在最后一幅图中被移除。
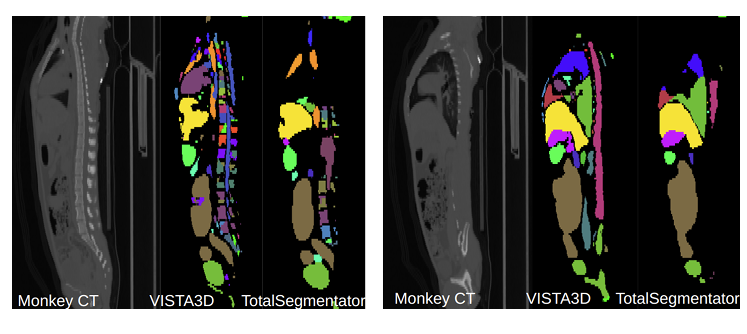
图 4. 猴类 CT 扫描的一个示例(2 个矢状位切片)。可以看出,VISTA3D 实现了更稳健的分割。
卓越性能
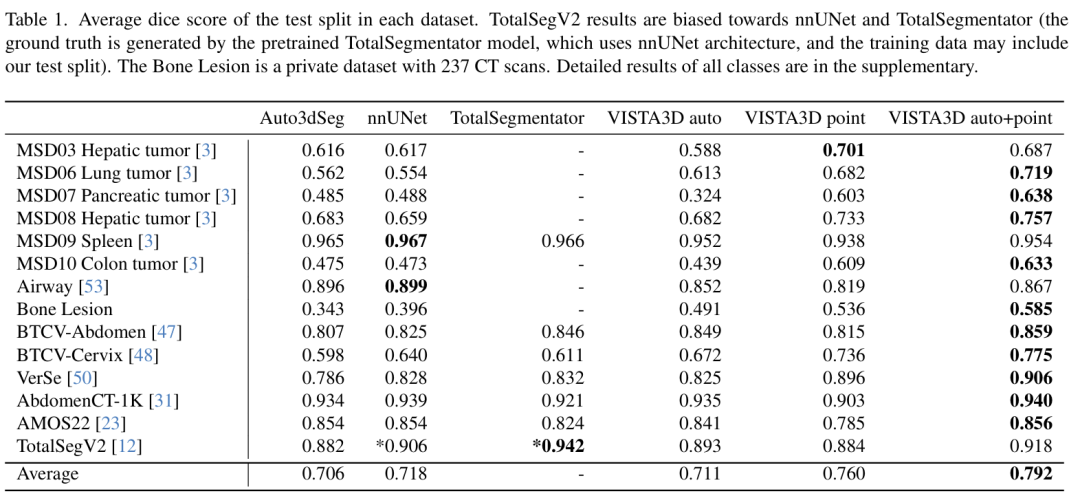
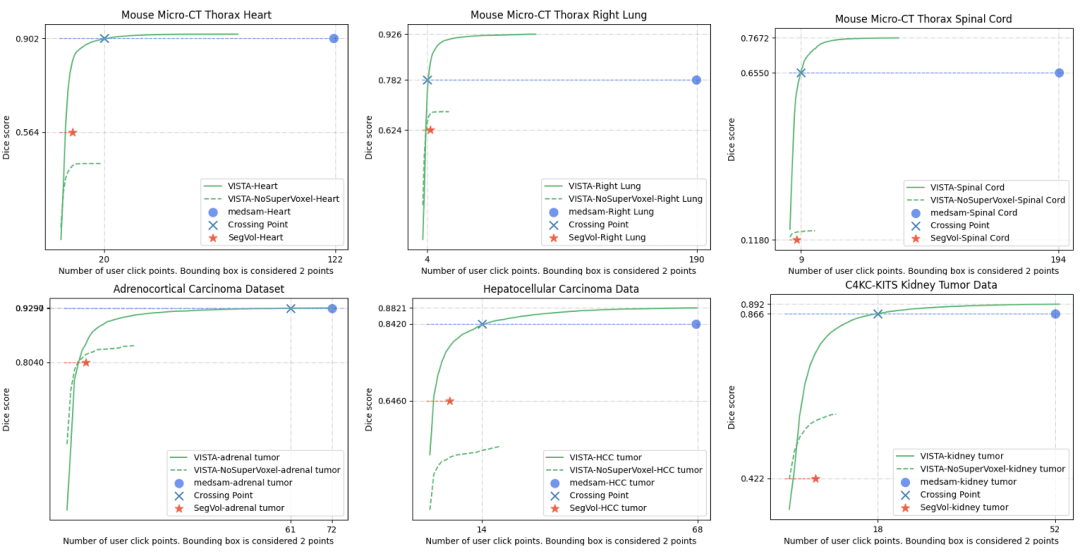
图 5. 零样本 Dice 评分。X 轴为点击点数,Y 轴为整个数据集的平均 Dice 评分。

图 6. 肾脏肿瘤的细粒度零样本交互式分割。第一幅图显示了肿瘤区域。步骤 1:在肿瘤上点击一个正点(红色)并得到结果。步骤 2:点击更多点以细化细节。此时结果存在过分割,步骤 3:添加一个负点(蓝色),得到最终结果。
参考:
https://arxiv.org/pdf/2406.05285
https://github.com/Project-MONAI/VISTA