Datawhale AI夏令营 第三期 task2 稍微改进
在打造基于大语言模型(LLM)+文档检索的问答系统中,财经研报类文档是最具挑战的场景之一。它包含图文混排、精细定位需求(页码、文件名)、问题措辞高度多样化等一系列复杂性。
下面的内容是大模型辅助整理的:
本项目围绕一个目标:给定一个用户问题,从数百份PDF财经报告中找出相关信息并生成准确答案,并给出其出处(文件名和页码),通过逐步优化 chunk 策略、向量检索和 LLM 提示工程
在train数据集上的得分为0.663,测试集目前为0.29679(排名第三)
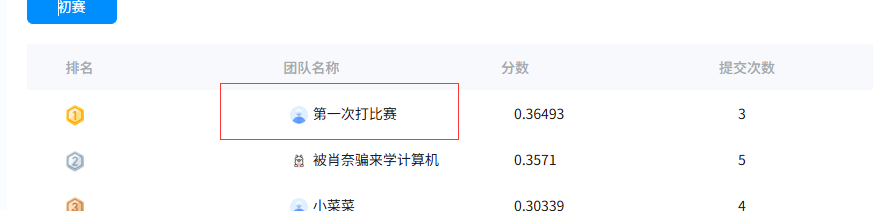
更新:加入了文档来源的大模型输出和元数据的比对,切换大模型为Qwen3-32B,目前分数:0.36493(排名第一)
评分标准分三部分,总分 1:
维度 权重 说明
文件名匹配度 0.25 答案中的文件名是否与参考答案一致
页码匹配度 0.25 答案中页码是否准确
答案内容相似度 0.5 使用字符级 Jaccard 相似度度量回答文本差异
🏁 初始方案:页面粒度chunk(Baseline)
做法:
每一页作为一个chunk
用FAISS构建向量索引
每次检索返回最相似的几页
问题:
粒度太大,LLM难以定位具体内容
过度信息干扰答案质量
无法定位到确切页码和文件名
📉 得分:0.002
🔧 改进一:递归Chunk + 直接向量检索
每页文本递归分块
每个chunk保留其来源元数据 {filename, page_number}
用文本嵌入直接构建向量索引
📈 得分显著提升
🧩 页码匹配精度优化
一个核心挑战是:如何让LLM生成答案时,引用准确的页码?
采取的策略:
从文档解析阶段开始,全程保留元数据:
每一段文本、每张图片都保留 {filename, page_number}
在提示中引导 LLM 输出来源信息
请用如下格式回答:
{“answer”: “…”, “filename”: “…”, “page”: …}
🔁 检索优化策略
多路召回:
双路召回:将检索向量划分为两种策略:全文语义 vs. 精准短句(如问句特征)
重排(Re-ranking)策略:
采用 RRF(Reciprocal Rank Fusion):
多路召回的结果融合排序
提高相关 chunk 的综合得分,提升命中率
🔍 LLM输出页码不准的问题
即使检索相关 chunk 的元数据正确,LLM有时也会:
忽略页码
捏造页码或文件名
输出格式错误(影响JSON解析)
解决:
构建严格提示模板,限制输出格式
增加后处理逻辑,验证输出格式合法性,出错回退使用 chunk 元数据
引入 _safe_parse() 工具,对返回结果进行强健解析
🧱 持续挑战
-
格式输出不稳定
LLM容易输出错 JSON,或 hallucinate 来源信息
强化提示模板
后处理校验修复 -
问题表达方式高度自由
用户问法与文档表达方式差距大
优化嵌入模型选择(支持中文财经语料)
其实分数还可以再高,因为现在的文件名是提取的大模型的回答,只用8B的大模型,会有很多错误,比如本来正确的名字输出为繁体,或者汉字输出为字母等,所以这个地方需要大模型+元数据同时判断,还没有用mineru或者其他的文档结构化转换工具,现在分块方法还是太朴素了,也还没用引入多模态(表格解析和图像解析)