CVPR 2025 | 华科精测:无需人工标注也能精准识别缺陷类别,AnomalyNCD 实现多类别缺陷自主分类
导读

论文地址:https://arxiv.org/abs/2410.14379
项目地址:https://github.com/HUST-SLOW/AnomalyNCD
华中科技大学慢工团队长期从事高自主化工业质检技术研究及产业化应用工作,2024年提出了国际首个无需训练、无需提示的零样本工业缺陷检测方法MuSc,该技术自提出以来,长期稳居Paper with Code零样本异常检测排行榜国际第一,获得业界的广泛关注。MuSc结合AnomalyNCD,在国际范围内首次实现了“缺陷自主检”、“类别自主分”的高迁移性工业质检新体系。
MuSc论文:https://arxiv.org/abs/2401.16753
MuSc代码:https://github.com/xrli-U/MuSc
点击阅读原文,获取更多咨询
工业质检从检出缺陷到理解缺陷的必经之路 —— 多分类任务的迫切性与挑战
在工业质检领域中,对工业缺陷类别进行识别,即缺陷多类分类,具有广泛的应用,从产品等级划分,到缺陷成因溯源和产线工艺优化,都需要具备识别缺陷类别的能力,多类别缺陷分类正成为产线智能化的核心刚需,新的挑战也随之浮出水面:
-
柔性生产已成为业界主流,产线生产的产品变化快,随时会出现新型缺陷,缺陷样本搜集难,人工标注成本高,使用监督式的参数化分类器进行分类,难以适应产线的快速迭代需求。
-
从成因来看,工业缺陷具有一定的随机性,因此缺陷类内差异极大,同类缺陷在特征空间中聚合度不足,采用非参数化聚类对缺陷类别进行划分,精度尚无法达到产业应用水平。
破局之道——三大技术革新实现缺陷分类自主化
针对上述业界迫切需求及当前技术瓶颈,华中科技大学慢工团队联合精测电子,创新性的提出了AnomalyNCD,该方法采用自监督训练的方式对缺陷表征和参数化分类器进行学习,摆脱了训练过程对标注样本的依赖,实现了高精度工业缺陷自主类别划分,该方法兼具全监督学习和聚类方法的优势,同时规避了他们面向工业缺陷数据时的局限性,应用潜力巨大。
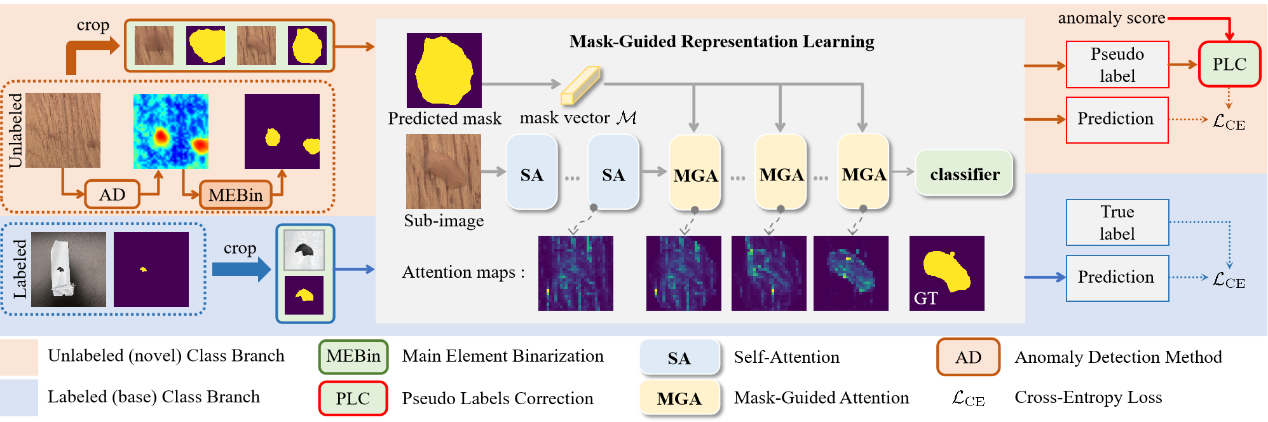
该方法主要包含三项革新技术:
-
主元素二值化(MEBin):给缺陷画重点
-
创新性的提出了自适应二值化方法,通过动态搜索阈值,提取跨阈值稳定的缺陷主体,解决了当前产业需要人工设定二值化阈值的瓶颈。
-
效果:能够为每个待测图片都分配一个最优的二值化阈值,相比固定阈值以及传统 Otsu 二值化,同时实现了较低的误检率与漏检率。
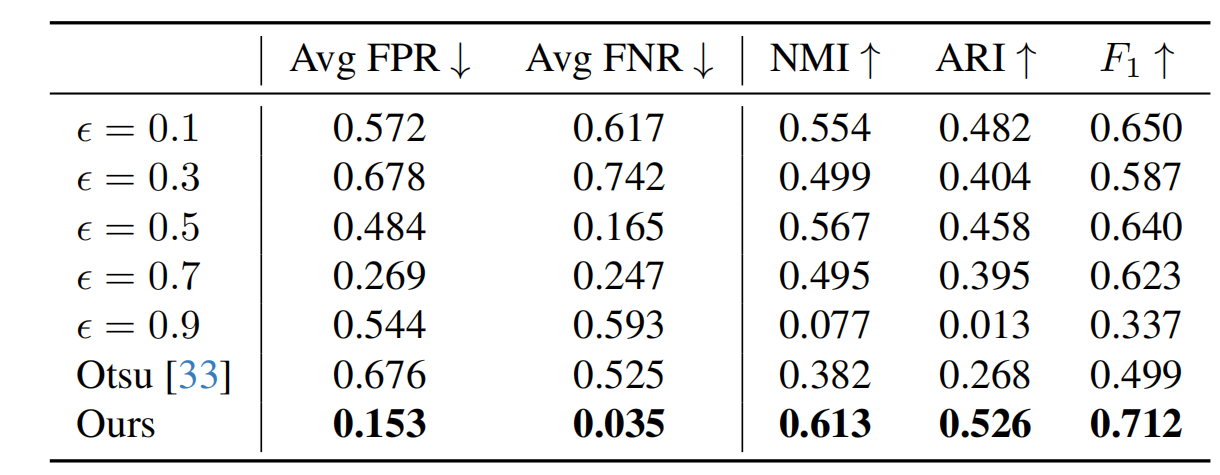
表格描述已自动生成
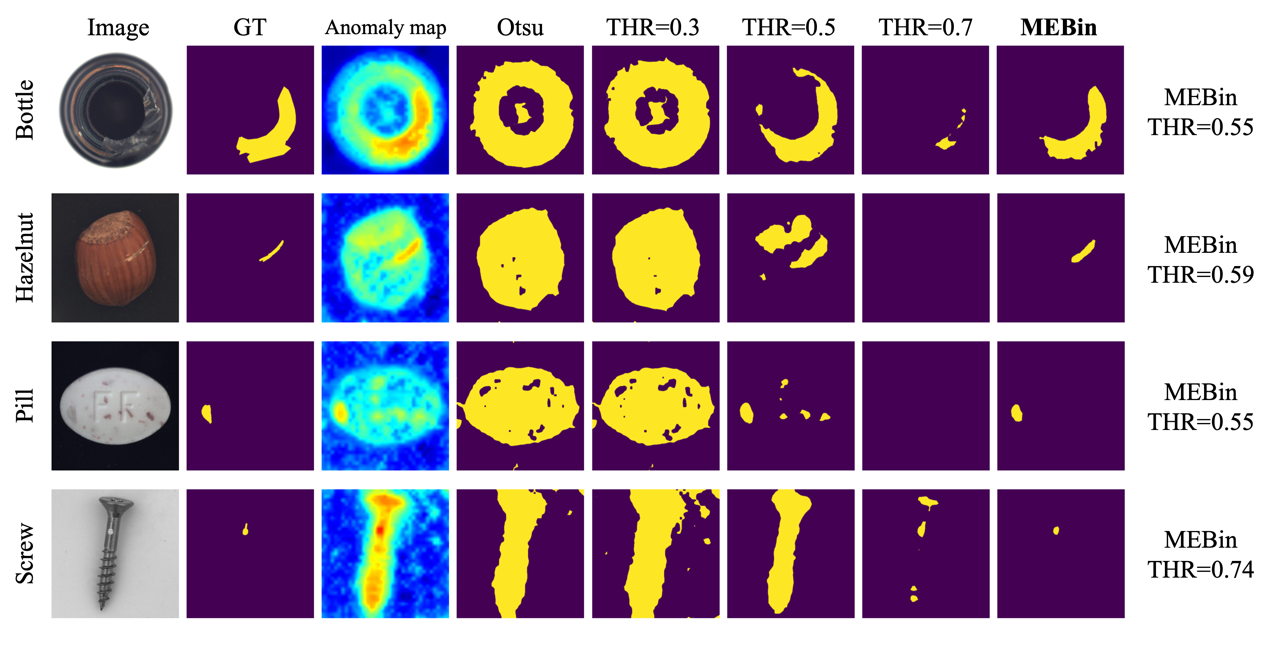
图片包含日历描述已自动生成
-
掩膜引导(Mask-Guided)表征学习:让模型看应该看的地方
-
利用 MEBin 生成的缺陷掩膜,约束Vision Transformer 聚焦真实缺陷区域,并结合伪标签技术,替代人工标注标签完成表征学习。
-
突破:工业缺陷弱语义、易混淆,模型常因背景干扰难以聚焦,掩膜引导显著提升了缺陷特征的提取能力,实现无人工标注下的细粒度缺陷的表征学习。
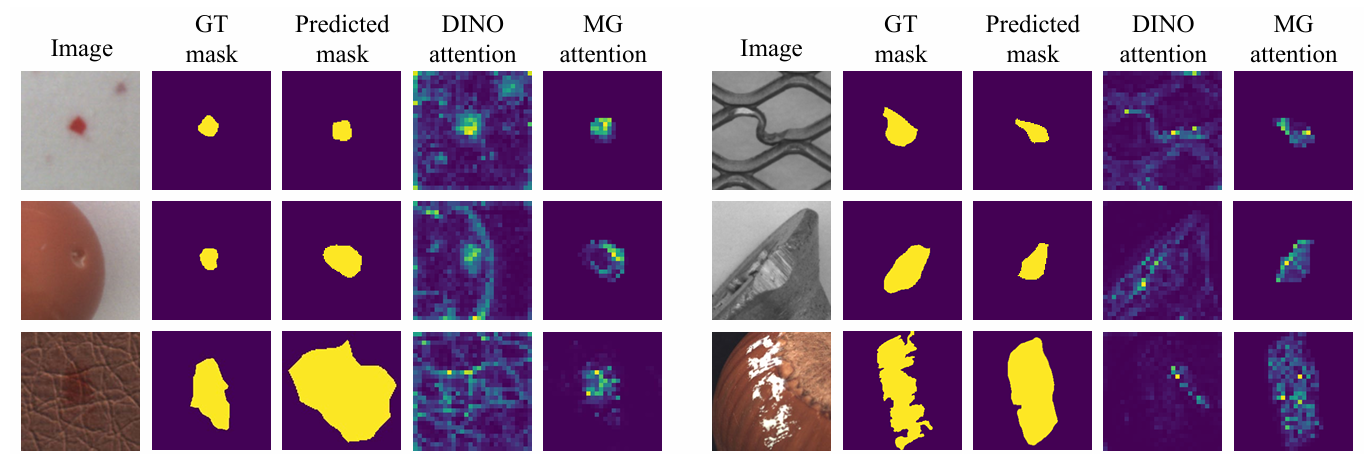
图片包含公司名称描述已自动生成
-
区域面积加权合并:从局部判断到全局决策
-
提出基于缺陷区域面积的加权融合策略:大尺寸的真实缺陷拥有更高决策权重,小尺寸误检区域的影响被大幅削弱。
-
价值:整合图像中各区域的分类结果,实现区域级与图像级的灵活分类输出。
价值体现——数据说话的工业级鲁棒性
-
性能表现惊艳: MVTecAD:F1提升(10.8%),NMI提升(8.8%),ARI提升(9.5%) MTD:F1提升(12.8%),NMI提升(5.7%),ARI提升(10.8%)

-
灵活集成: 可以与任意异常检测方法进行无缝结合使用,结合PatchCore、MuSc、CPR等主流异常检测模型的结果都十分优异。
关注下方《AI前沿速递》🚀🚀🚀
各种重磅干货,第一时间送达
码字不易,欢迎大家点赞评论收藏