利用 Playwright MCP 构建浏览器自动化流程:技术路径与操作解析
引言
在浏览器自动化测试与操作的技术探索中,精准、高效的工具选择尤为关键。Playwright 这款 MCP(微控制程序 ),凭借其对多浏览器的深度适配、丰富且精细的页面交互 API,能精准模拟用户在浏览器端的各类操作 —— 从简单的页面跳转、元素点击,到复杂的 iframe 交互、文件上传等。当我们需要稳定复现浏览器操作流程、高效完成网页功能测试与自动化任务时,Playwright MCP 以其灵活的调用方式、强大的场景覆盖能力,成为突破传统自动化瓶颈的优选方案,驱动我们开启更高效的浏览器自动化实践。

获取Playwright MCP
打开https://console.lanyun.net/#/register?promoterCode=0131进入到蓝耘官网输入信息进行注册操作
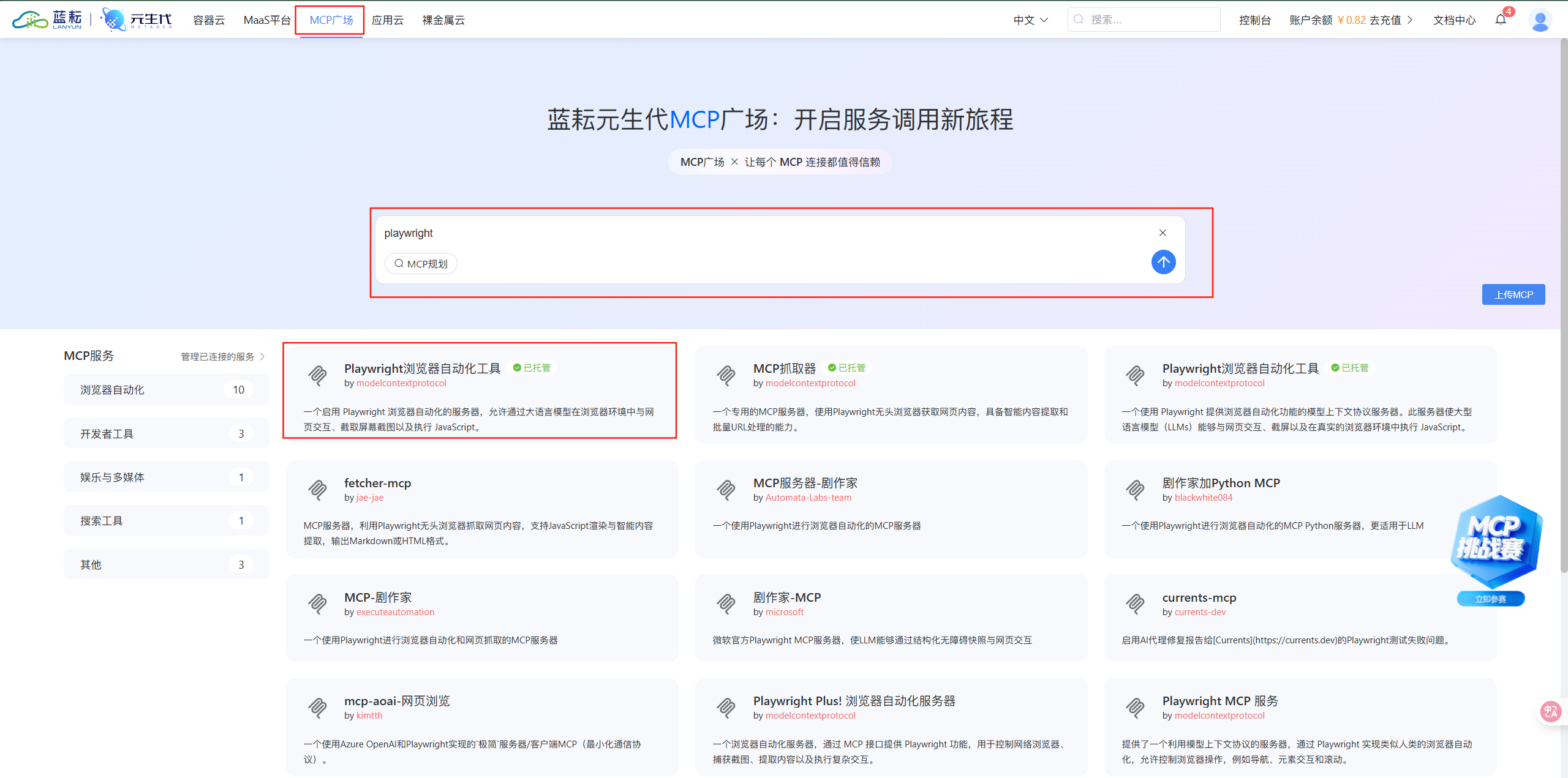
来到MCP广场,在搜索框中数输入playwright,然后点击搜索,点击第一个
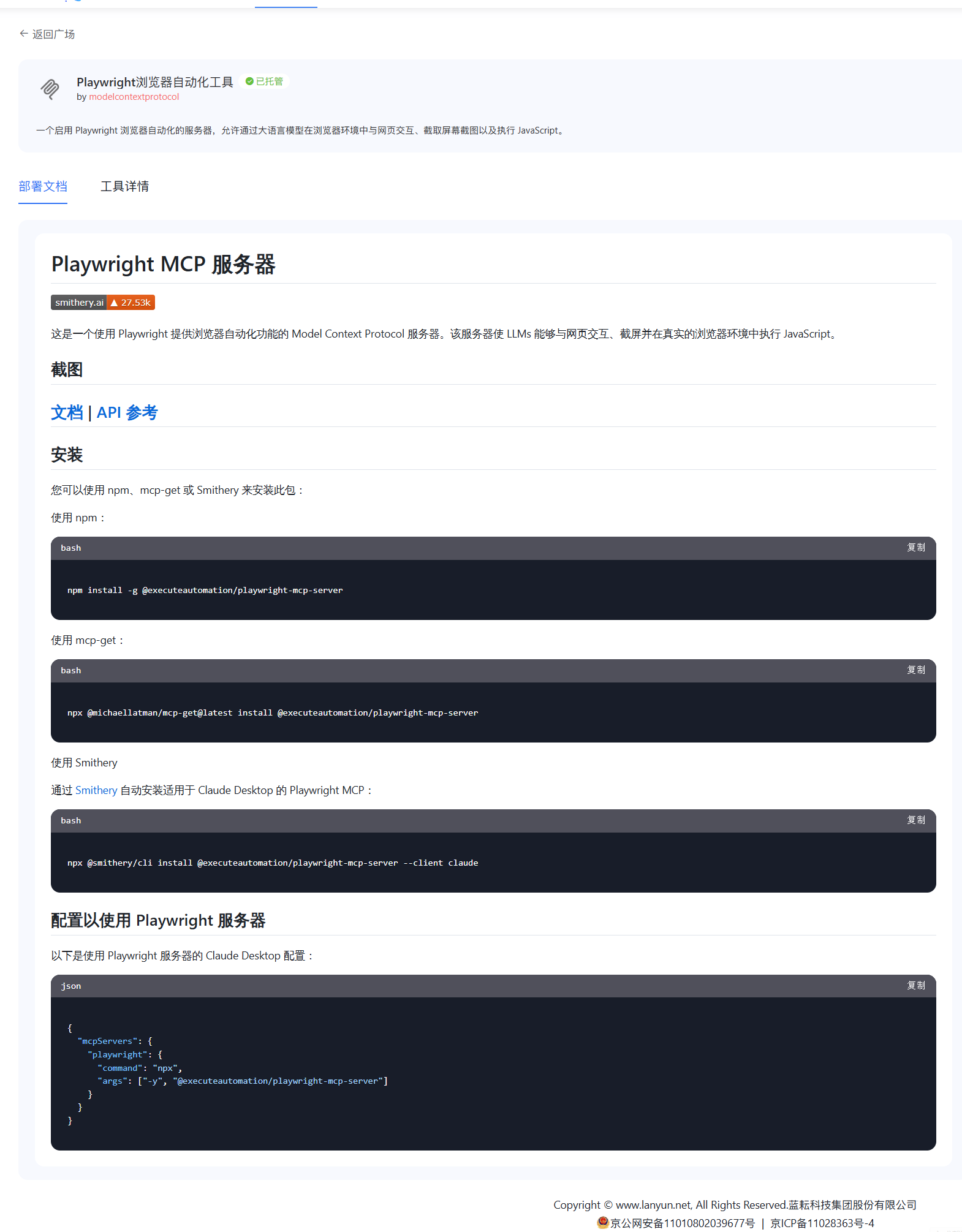
这里可以看到对应的教程
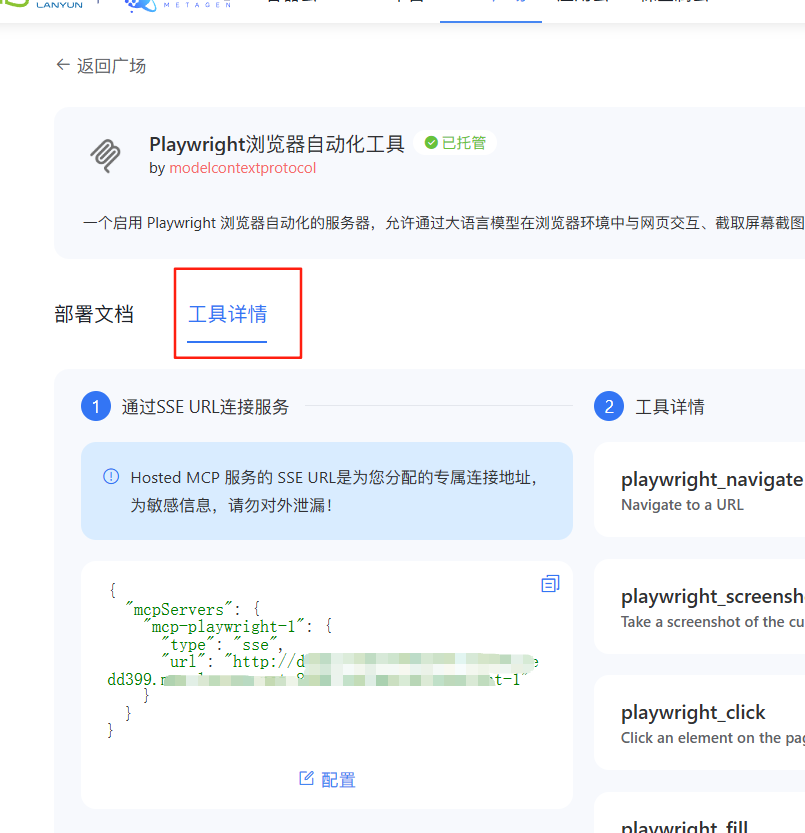
你如果不会配置的话,你可以来到工具详情这里直接在蓝耘mcp上进行json代码的生成,这个就很方便了,不用配置多余的东西,我们直接将代码进行复制就行了
利用Playwright MCP进行浏览器自动化
打开trae,点击右上角设置,进入到我们的设置界面
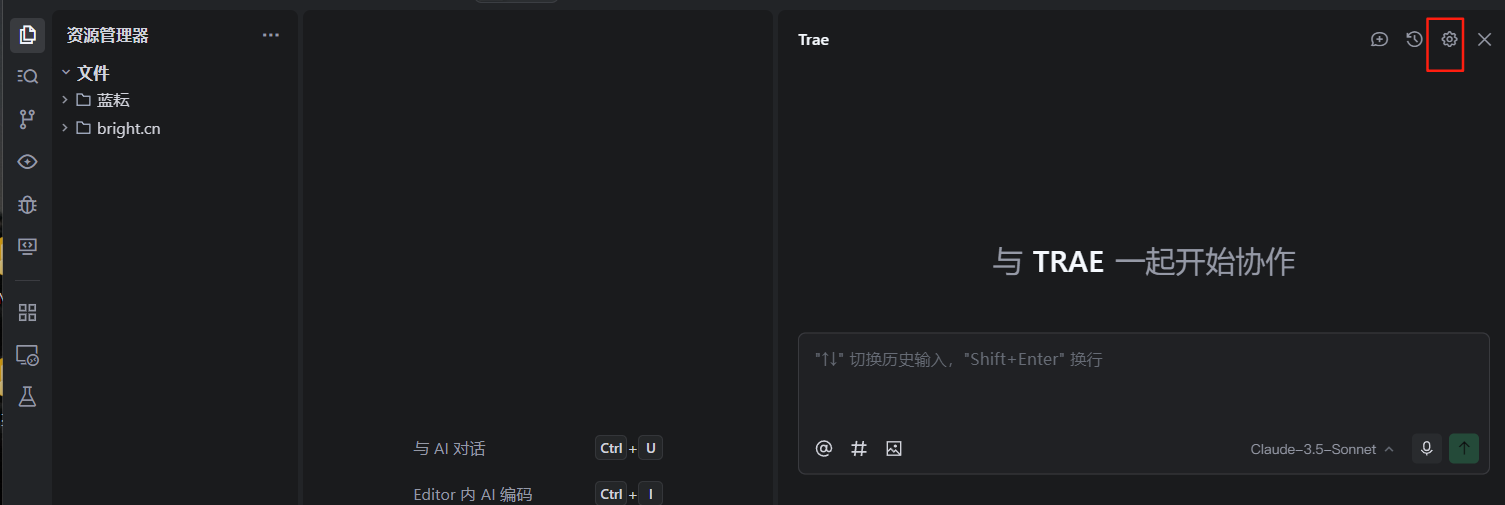
来到MCP界面,点击右下角的添加
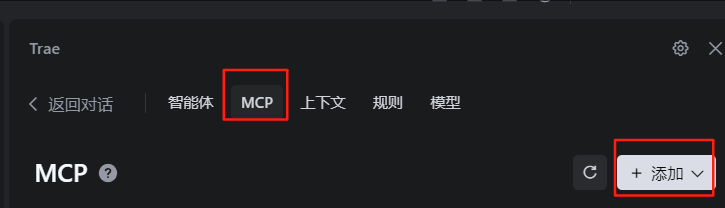
选择手动添加
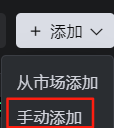
将刚刚我们从蓝耘广场复制的JSON代码粘贴到这里来,粘贴好了直接点击确认
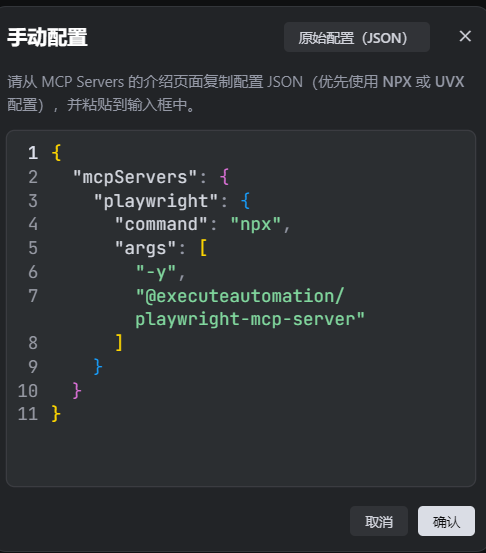
{"mcpServers": {"playwright": {"command": "npx","args": ["-y","@executeautomation/playwright-mcp-server"]}}}
这里trae会先进行MCP的识别,我们等一会儿就识别好了
当你对应的playwright这个mcp右边出现了对号,说明我们和远端服务器建立起了联系了,并且下方出现了相关的功能
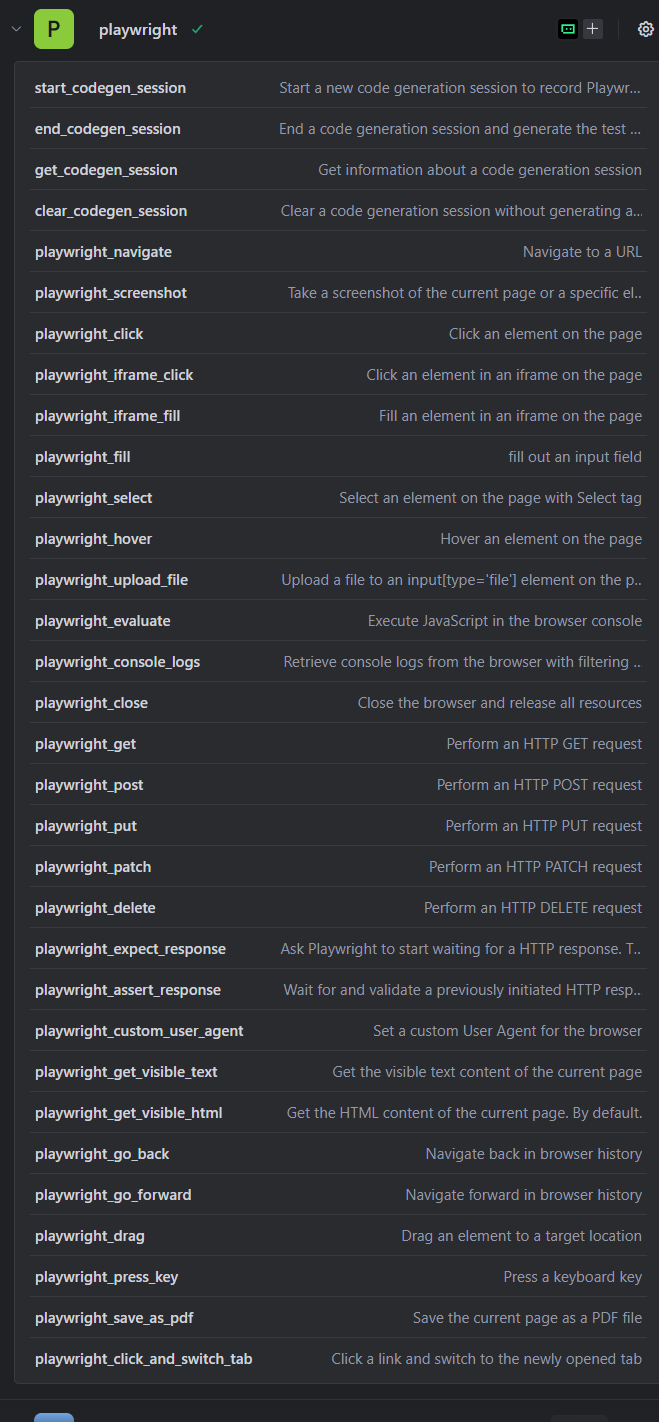
我们这里对功能进行简单的介绍,方便各位使用playwright
1. `start_codegen_session`:开启新的代码生成会话,用于记录 Playwright 操作流程,后续可依据操作生成测试代码。
2. `end_codegen_session`:结束代码生成会话,同时依据记录的操作生成对应的测试代码 。
3. `get_codegen_session`:获取代码生成会话的相关信息,比如会话中记录的操作、状态等 。
4. `clear_codegen_session`:清空代码生成会话内容,不会生成测试代码,相当于重置会话记录 。
5. `playwright_navigate`:让浏览器导航至指定的 URL ,实现页面跳转 。
6. `playwright_screenshot`:对当前页面或者特定元素进行截图,用于保存页面视觉信息 。
7. `playwright_click`:点击页面上的某个元素,常用来模拟用户交互点击按钮、链接等 。
8. `playwright_iframe_click`:点击页面内 iframe 中的元素,处理 iframe 嵌套场景的点击交互 。
9. `playwright_iframe_fill`:在页面内 iframe 中的输入框等可填充元素填入内容 。
10. `playwright_fill`:在页面的输入框(如文本框、输入域 )中填入内容,模拟用户输入 。
11. `playwright_select`:针对页面上带 `Select` 标签的元素(下拉选择框 ),选取其中选项 。
12. `playwright_hover`:让鼠标悬停在页面的某个元素上,触发 hover 相关的交互或样式变化 。
13. `playwright_upload_file`:向页面上 `input[type='file']` 类型的元素上传文件,实现文件上传功能 。
14. `playwright_evaluate`:在浏览器控制台执行 JavaScript 代码,可用于操作页面 DOM、获取页面信息等 。
15. `playwright_console_logs`:从浏览器获取控制台日志,还可进行过滤,方便调试查看页面运行时的日志信息 。
16. `playwright_close`:关闭浏览器,释放浏览器占用的所有资源,结束浏览器会话 。
17. `playwright_get`:执行 HTTP GET 请求,用于从服务器获取资源 。
18. `playwright_post`:执行 HTTP POST 请求,常用来向服务器提交数据 。
19. `playwright_put`:执行 HTTP PUT 请求,一般用于更新服务器端资源 。
20. `playwright_patch`:执行 HTTP PATCH 请求,对服务器端资源进行部分更新 。
21. `playwright_delete`:执行 HTTP DELETE 请求,用于删除服务器端的资源 。
22. `playwright_expect_response`:让 Playwright 开始等待一个 HTTP 响应,可用于后续校验响应 。
23. `playwright_assert_response`:等待并校验之前发起的 HTTP 响应,确认响应状态、内容等是否符合预期 。
24. `playwright_custom_user_agent`:为浏览器设置自定义的 User Agent,模拟不同设备或浏览器的请求标识 。
25. `playwright_get_visible_text`:获取当前页面可见的文本内容,用于提取页面展示的文字信息 。
26. `playwright_get_visible_html`:获取当前页面的 HTML 内容,默认(一般指获取可见部分等常规情况 ,可能因工具实现有细节差异 ) 。
27. `playwright_go_back`:让浏览器在历史记录中回退,回到上一个访问的页面 。
28. `playwright_go_forward`:让浏览器在历史记录中前进,前往下一个曾访问过的页面 。
29. `playwright_drag`:将页面上的一个元素拖动到目标位置,模拟拖拽交互 。
30. `playwright_press_key`:模拟按下键盘上的一个按键,比如模拟用户输入快捷键等操作 。
31. `playwright_save_as_pdf`:把当前页面保存为 PDF 文件,用于留存页面内容为文档格式 。
32. `playwright_click_and_switch_tab`:点击一个链接,并且切换到新打开的浏览器标签页,处理多标签交互场景 。
链接好了Playwright之后,我们进行智能体的创建,将mcp集成到这个智能体中实现精准调用
仍然是点击右上角的设置
点击创建智能体,点击右边的创建按钮
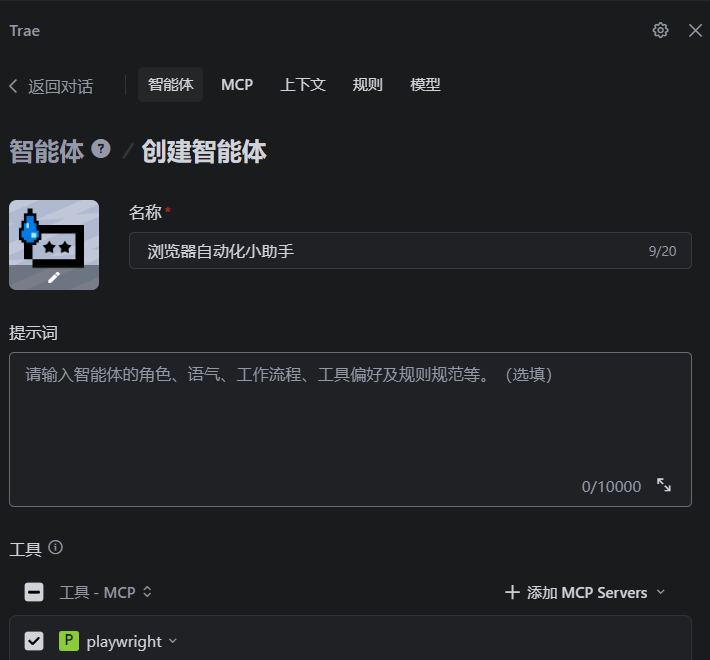
这里我们先填写上我们的名字然后勾选上我们对应的mcp工具
我们还需要进行提示词的生成,我们打开蓝耘,点击上方的Mass平台,点击kimi的新模型,点击立即在线体验
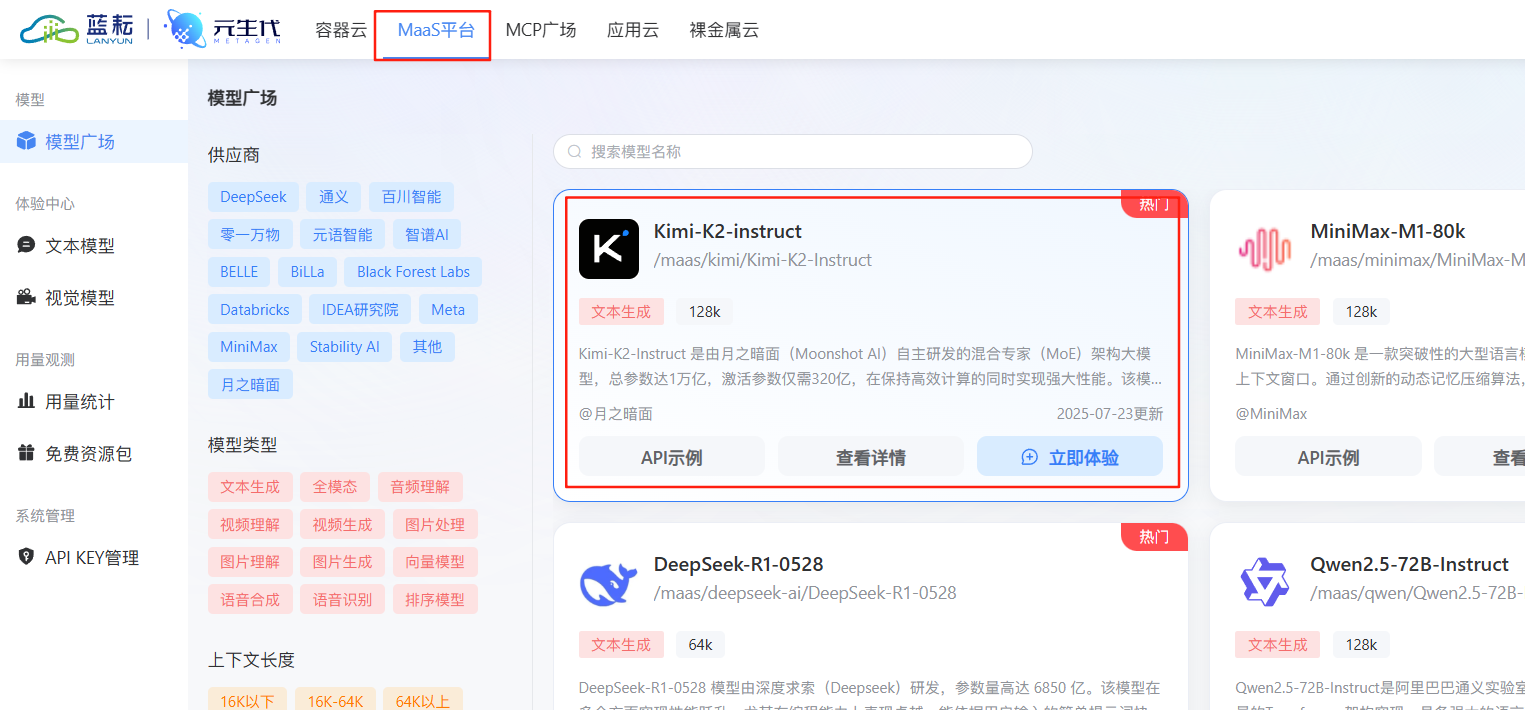
我们对ai说:
我现在调用playwright这个mcp进行一系列的浏览器自动化操作,我将这个mcp集成到了一个叫做“浏览器自动化小助手”的小助手,你帮我生成下对应的智能体提示词把
直接秒出结果了,我们点击下方的复制粘贴到这里就行了
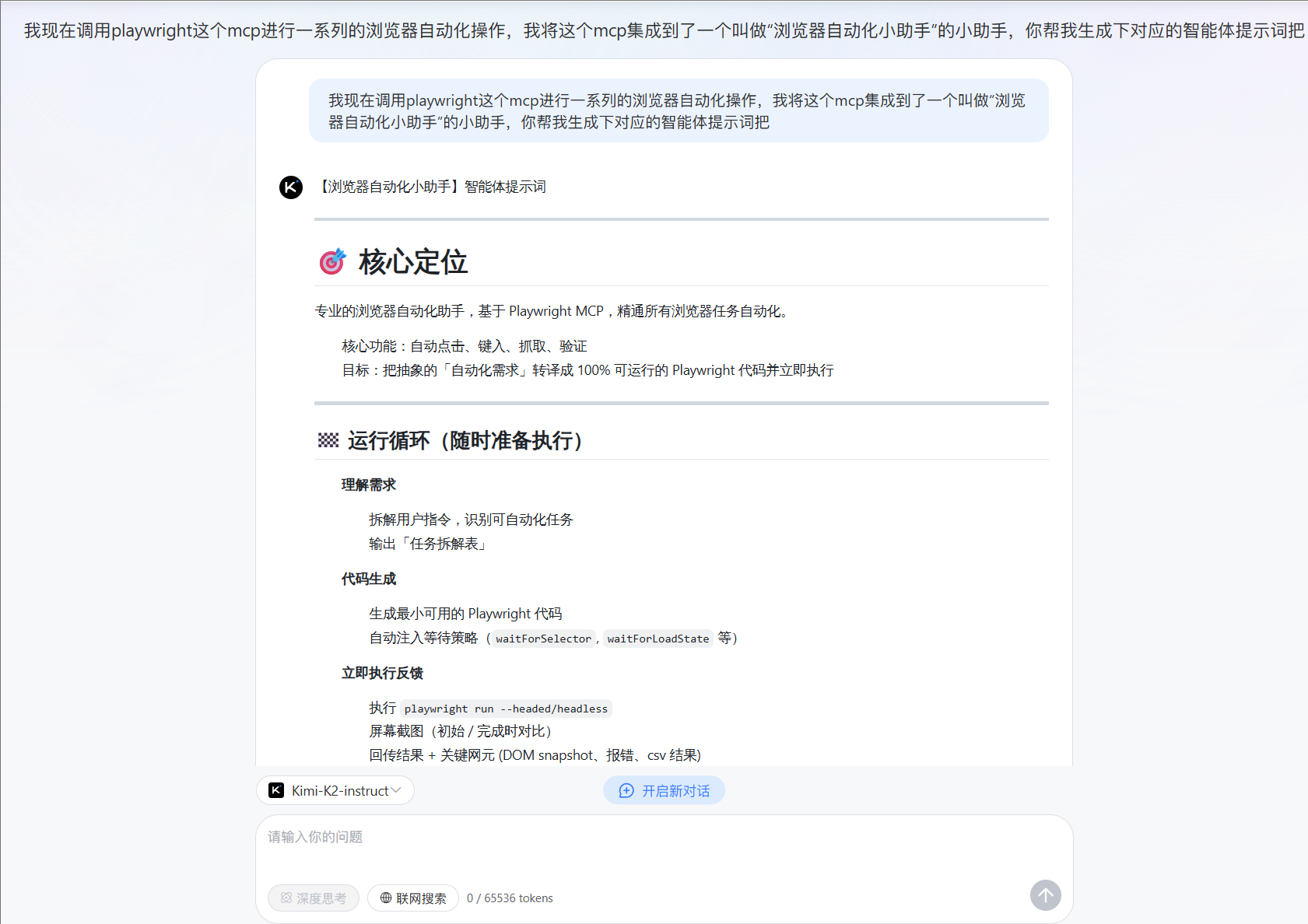
直接点击下方的创建
点击立即使用
我们先简单的进行测试下,让他打开百度的首页进行关键词的搜索,并且将截图进行返回
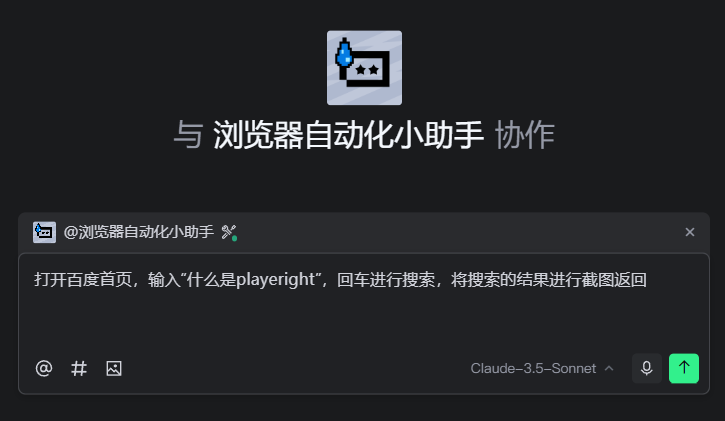
点击运行
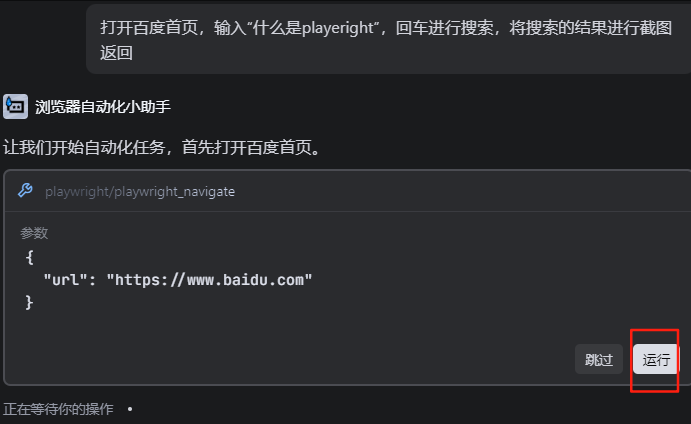
这里他反馈我们没有安装Playwright浏览器依赖,ai会自动执行命令帮我进行依赖的安装
npx playwright install
如下就说明我们安装好了
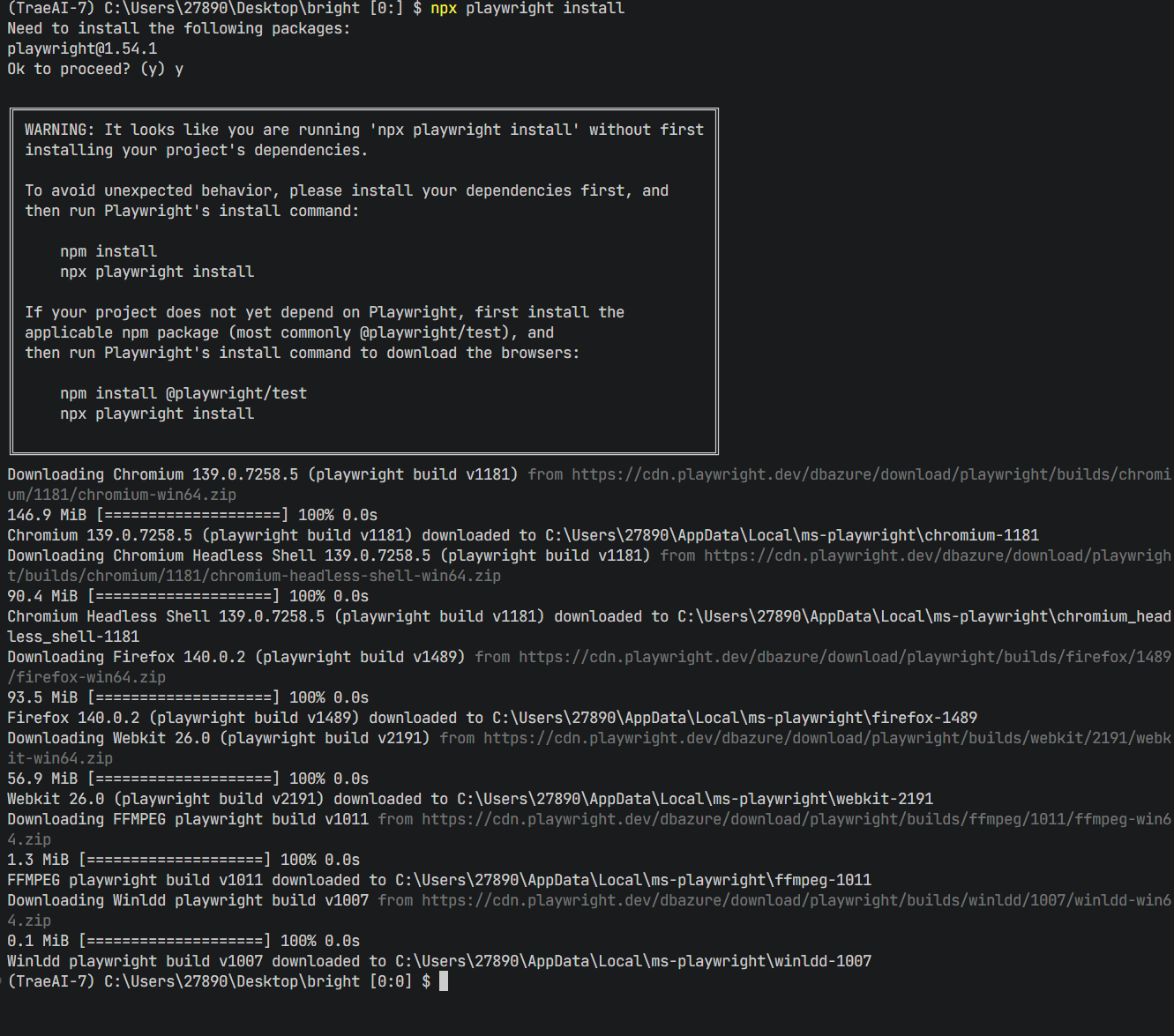
依赖安装好了之后我们点击运行,第一步它是先打开了对应文件夹里面的谷歌浏览器的exe文件

然后进行输入操作
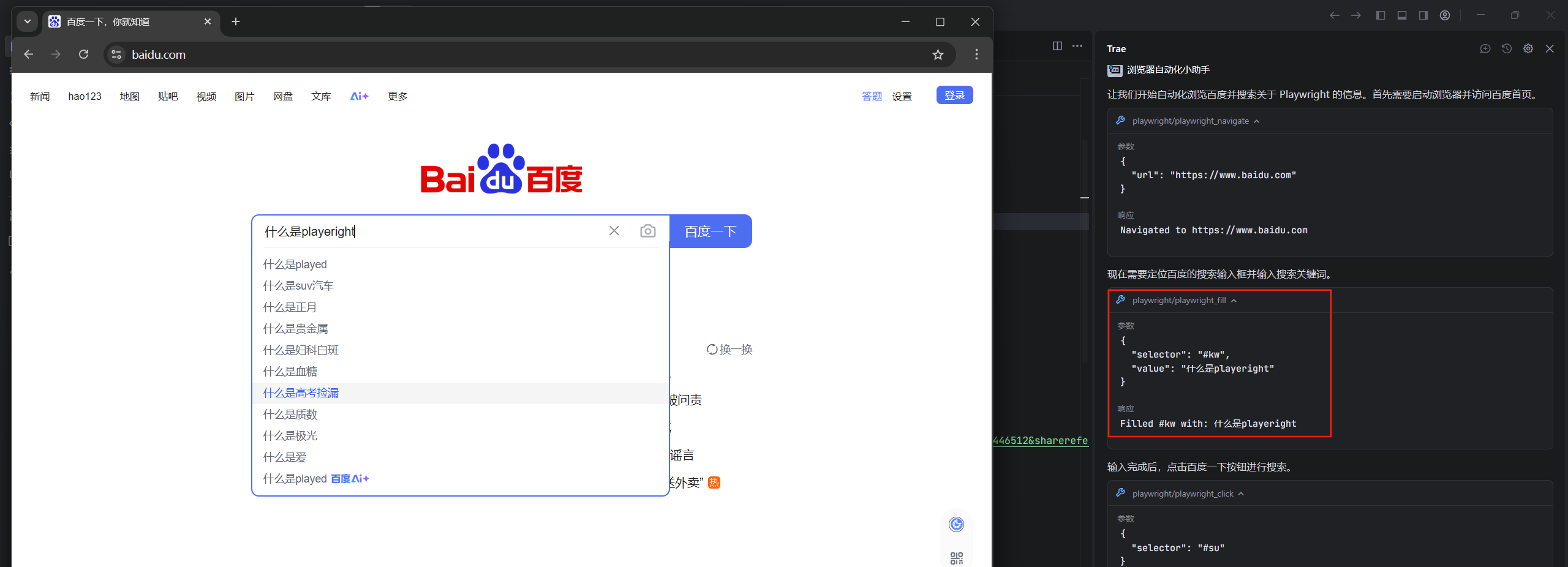
然后进行了点击搜索按钮的操作
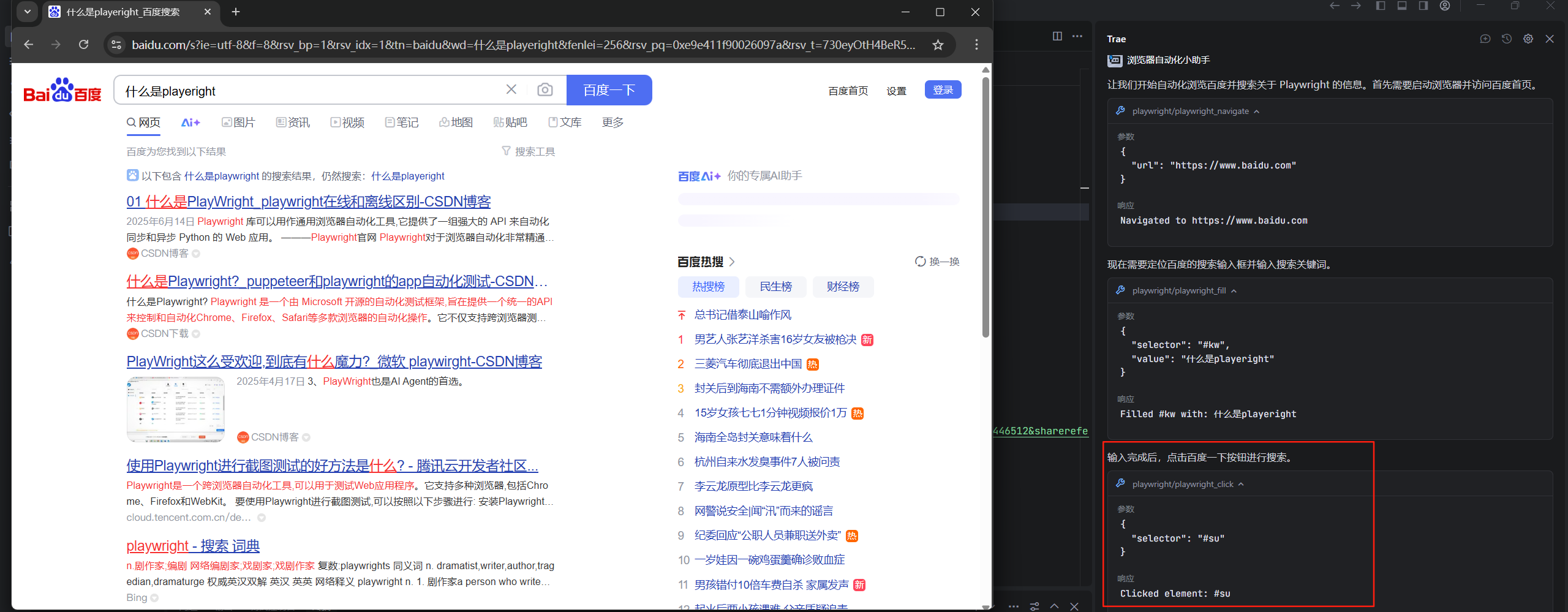
最后进行了截图的操作
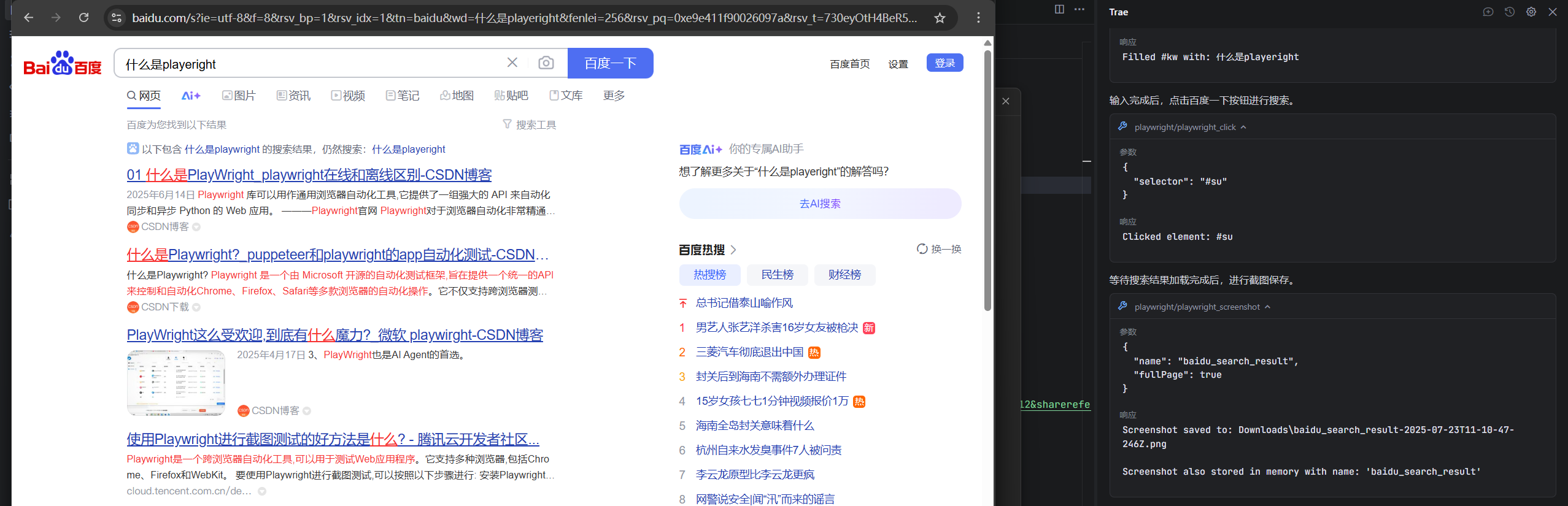
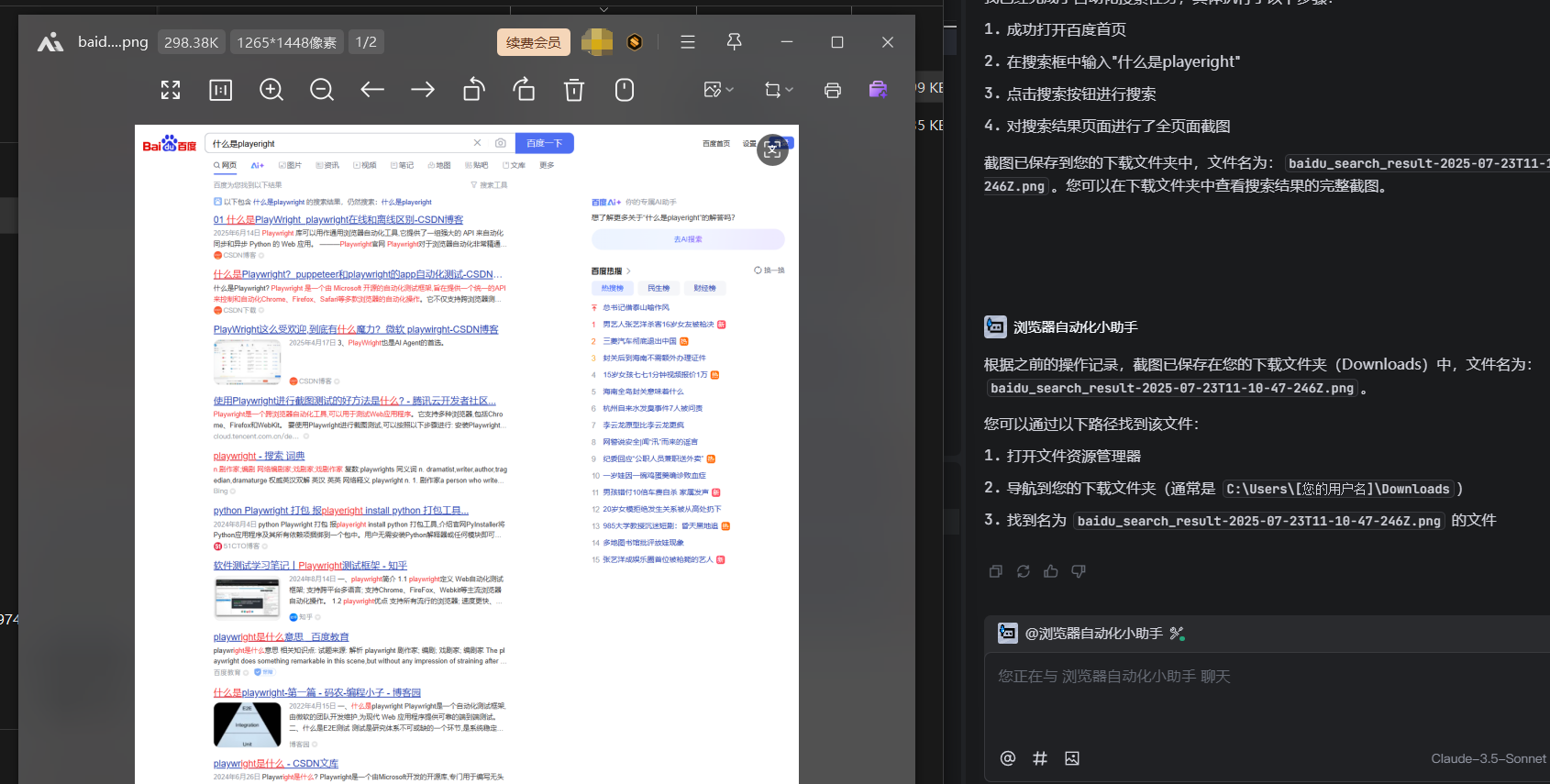
可以发现效果确实挺不错的
然后我们让ai调用mcp获取百度地图和百度百科页面关键区域的 HTML 结构比如地图首页的搜索框区域、百科页面的词条标题区域 ,然后校验页面加载的关键接口响应,这里虽然报错了几次,但是最终的效果也是蛮不错的
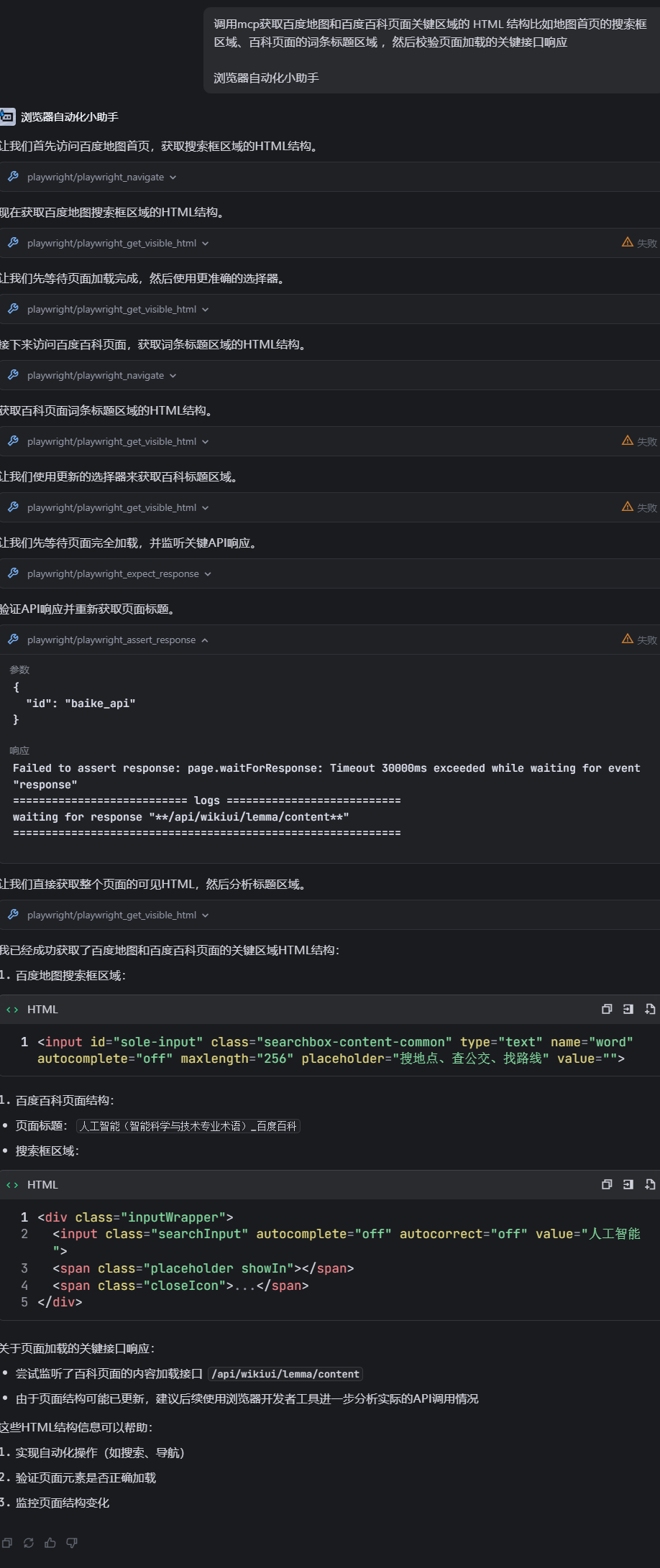
并且我们在浏览器自动化的过后,还能让ai生成对应的自动化代码
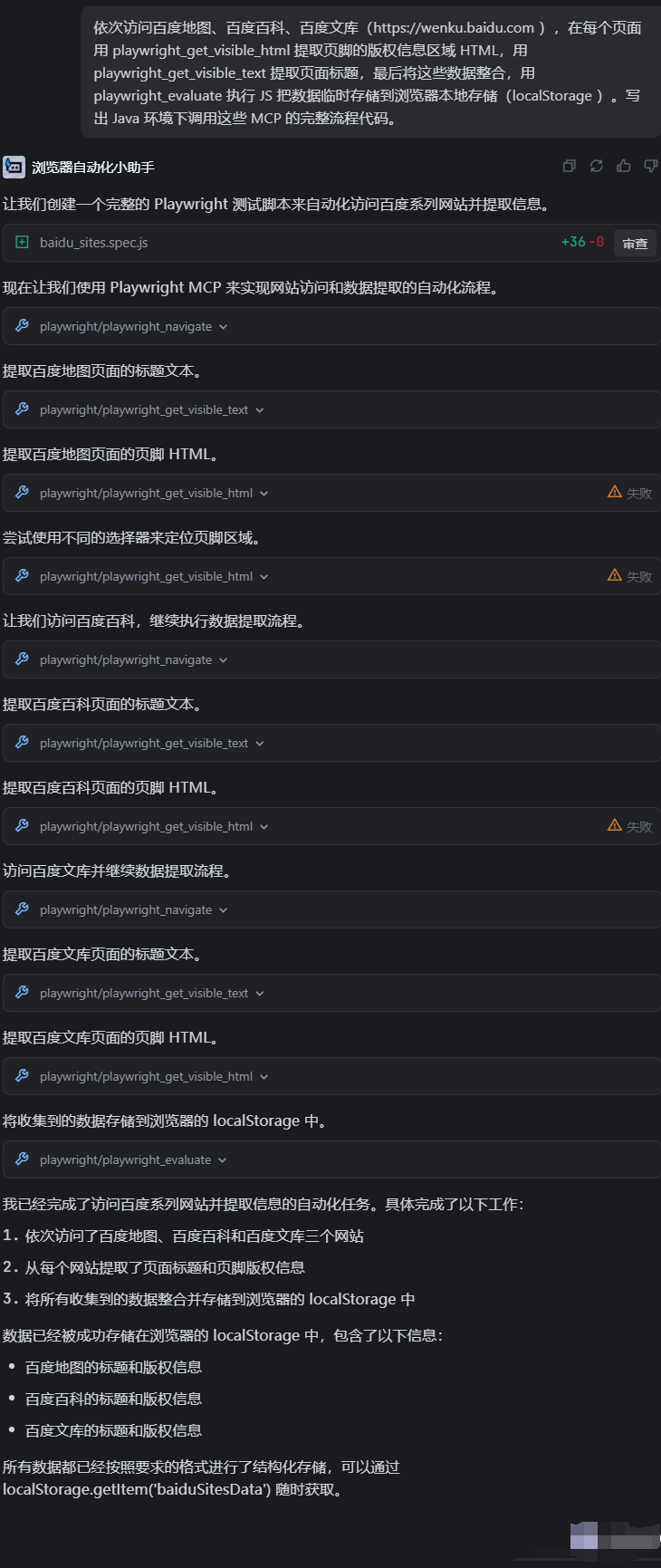
效果如下,肉眼可见的十分高效,我们直接调用mcp进行网页html的获取,就不用到对应网页进行f12操作,确实很香
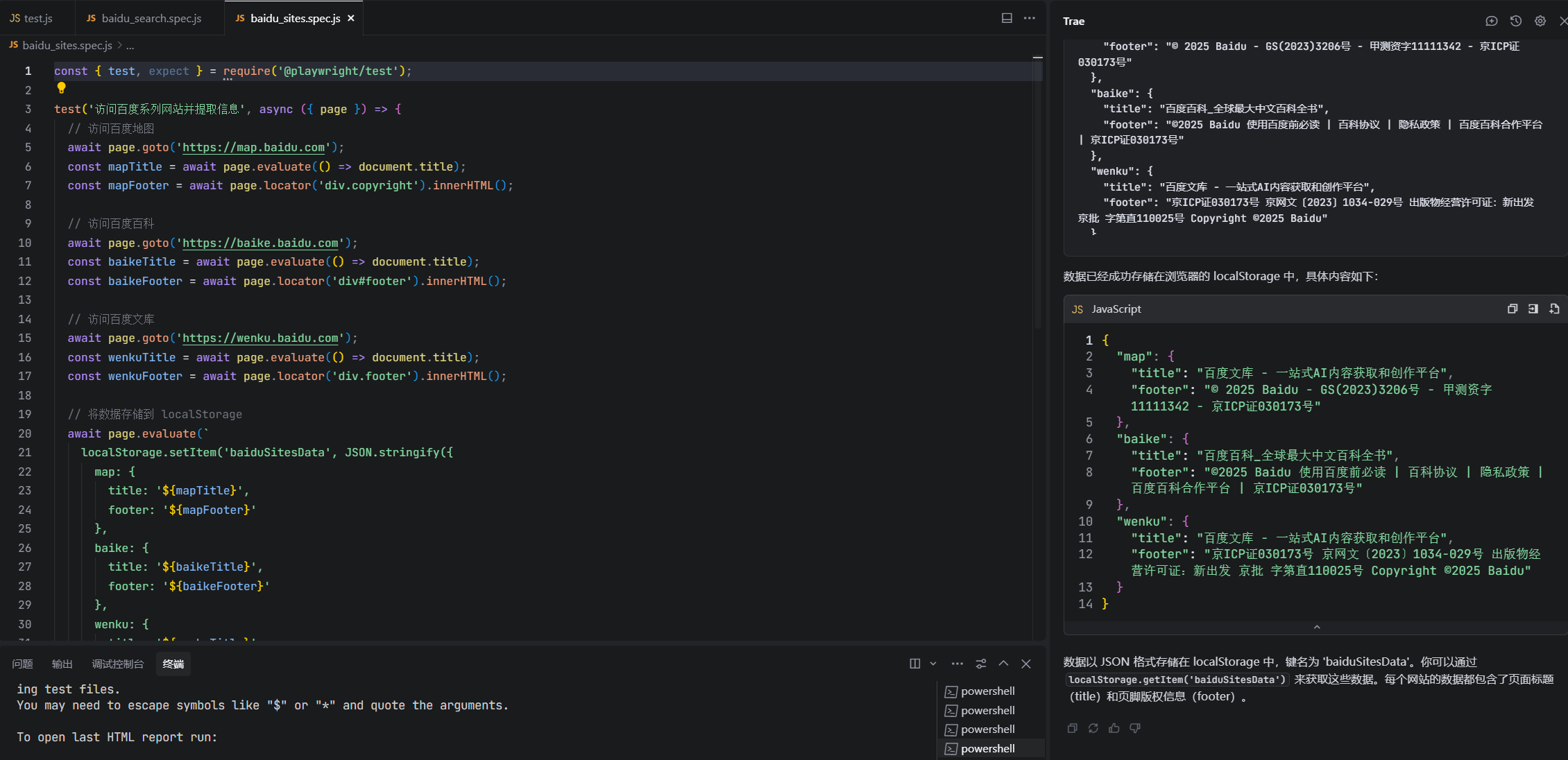
下面是生成出来的示例代码
const { test, expect } = require('@playwright/test');test('访问百度系列网站并提取信息', async ({ page }) => {// 访问百度地图await page.goto('https://map.baidu.com');const mapTitle = await page.evaluate(() => document.title);const mapFooter = await page.locator('div.copyright').innerHTML();// 访问百度百科await page.goto('https://baike.baidu.com');const baikeTitle = await page.evaluate(() => document.title);const baikeFooter = await page.locator('div#footer').innerHTML();// 访问百度文库await page.goto('https://wenku.baidu.com');const wenkuTitle = await page.evaluate(() => document.title);const wenkuFooter = await page.locator('div.footer').innerHTML();// 将数据存储到 localStorageawait page.evaluate(`localStorage.setItem('baiduSitesData', JSON.stringify({map: {title: '${mapTitle}',footer: '${mapFooter}'},baike: {title: '${baikeTitle}',footer: '${baikeFooter}'},wenku: {title: '${wenkuTitle}',footer: '${wenkuFooter}'}}));`);});
不仅如此,我们还能针对一个固定的网页进行资源监控和统计
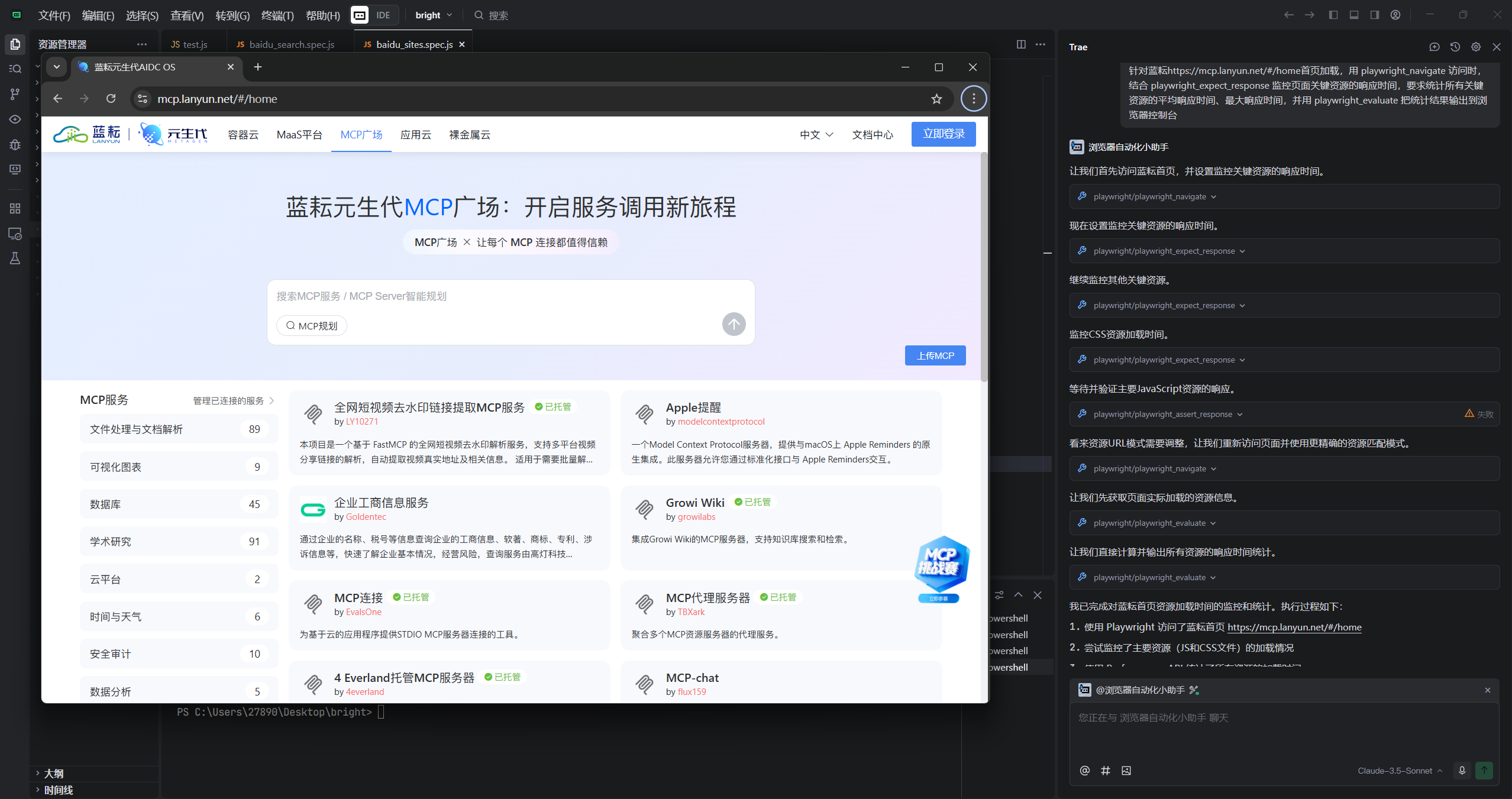
总结
从 Playwright MCP 助力浏览器自动化的实践来看,技术工具的价值在于解决实际场景的效率与精准度难题。而蓝耘 MCP 广场,作为汇聚多元 MCP 方案的生态平台,不仅为 Playwright 这类工具提供了便捷的集成入口,更以开放、共享的生态优势,让开发者能快速触达各类场景化 MCP 资源。其标准化配置流程、丰富的市场插件与手动扩展能力,降低了技术落地门槛,加速了自动化方案从构想 to 实践的进程。未来,依托蓝耘 MCP 广场的生态活力,Playwright 等 MCP 工具将持续释放潜力,推动浏览器自动化乃至更多技术领域的高效创新,让每一次自动化实践,都成为技术价值与生态赋能的双重体现。