n8n教程分享,从Github读取.md文档内容
从上一篇我们了解到了如何安装 n8n
那么这节课我们尝试从github的个人仓库获取某个文件的内容

目标如下
content/business/1.how-to-use-money.mdx
总流程图
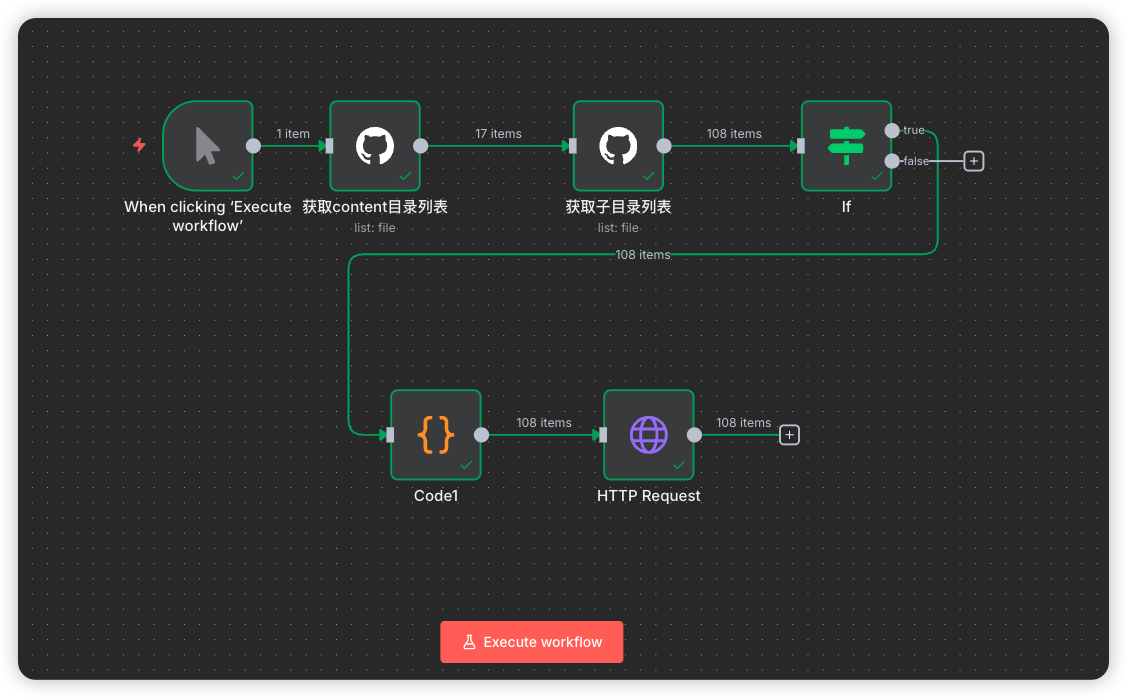
流程详解
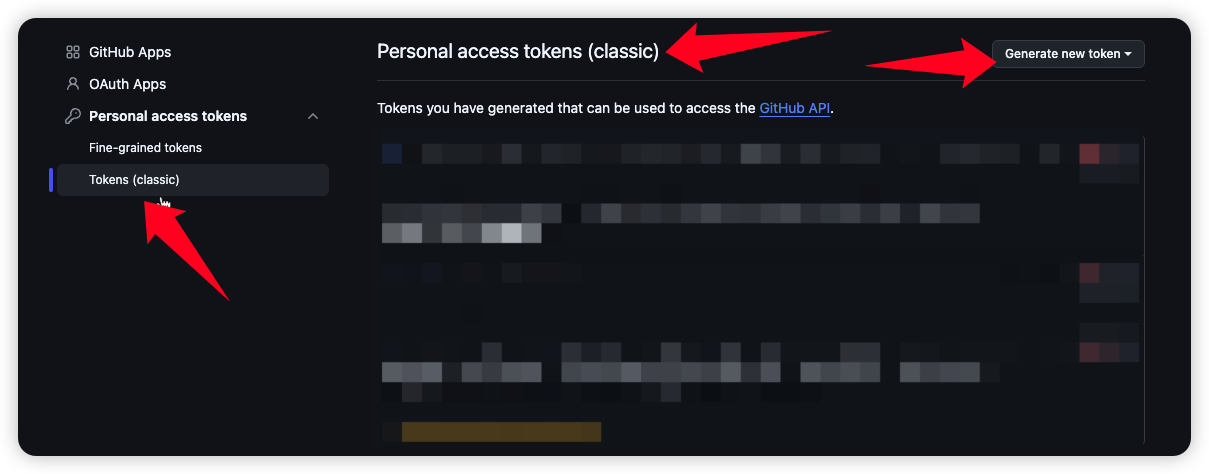
第1步:申请 GitHub Personal Access Token (Classic)
在gitrhub 个人 设置选项 申请 GitHub Personal Access Token (Classic)
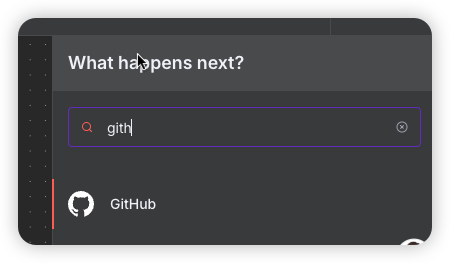
在第二步之前我们点击➕,会进行选择github节点,我们先获取文件列表所以选择 List files
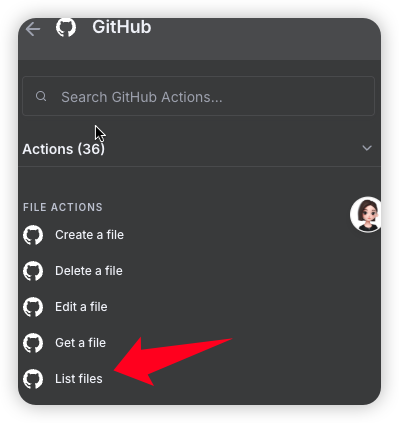
第2步:获取content目录列表 (第一个 GitHub 节点)
-
节点类型:GitHub
-
作用:流程启动后,首先会执行这个节点。它的任务是连接到您配置好的某个 GitHub 仓库,并获取根目录下名为
content的文件夹里面所有文件和子文件夹的列表。 -
输出:一个包含多个项目的列表,每个项目都代表
content目录下的一个文件或文件夹。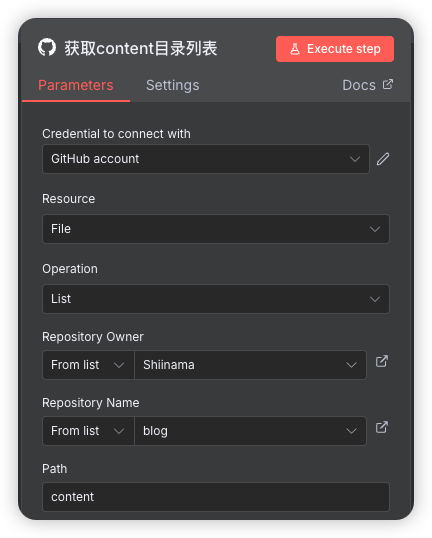
Credential to connect with (连接凭证): GitHub account 把我们刚申请的填入进去
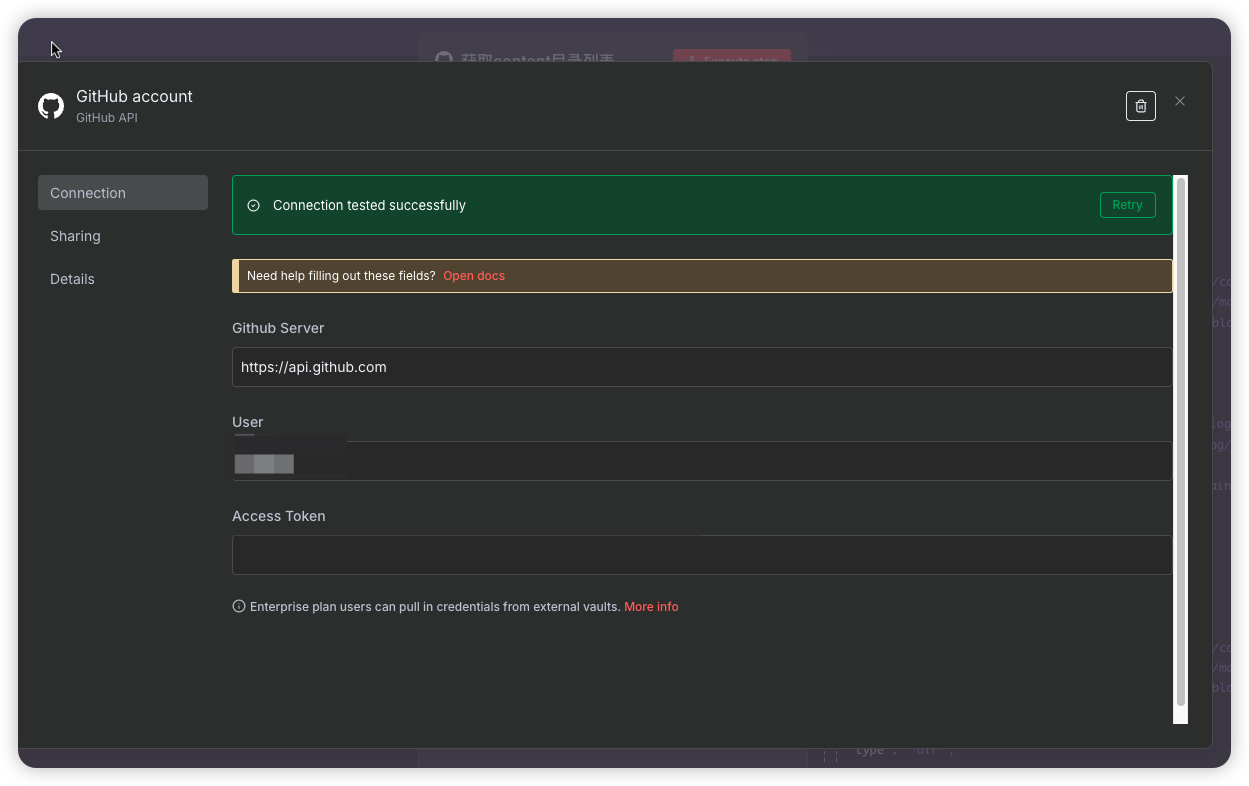
-
User 为你的github用户
-
Access Token填入申请的key
-
Resource (资源):
File- 操作的 GitHub 资源类型是“文件”。 -
Operation (操作):
List- 资源执行的操作是“列出”。结合起来就是“列出文件”。 -
Operation (操作)和Resource (资源) 有其他的选项可以尝试结合
-
Repository Owner (仓库所有者):
Shiinama- 指定了目标仓库是属于Shiinama这个用户或组织的。 -
Repository Name (仓库名称):
blog- 指定了仓库的名字是blog。 -
Path (路径):
content- 指定了要列出内容的具体路径是仓库根目录下的content文件夹。
这个仓库的名称结合起来就是我的项目地址 https://github.com/Shiinama/blog
我们来尝试执行一下就会看到
已经成功列出了仓库的文件目录
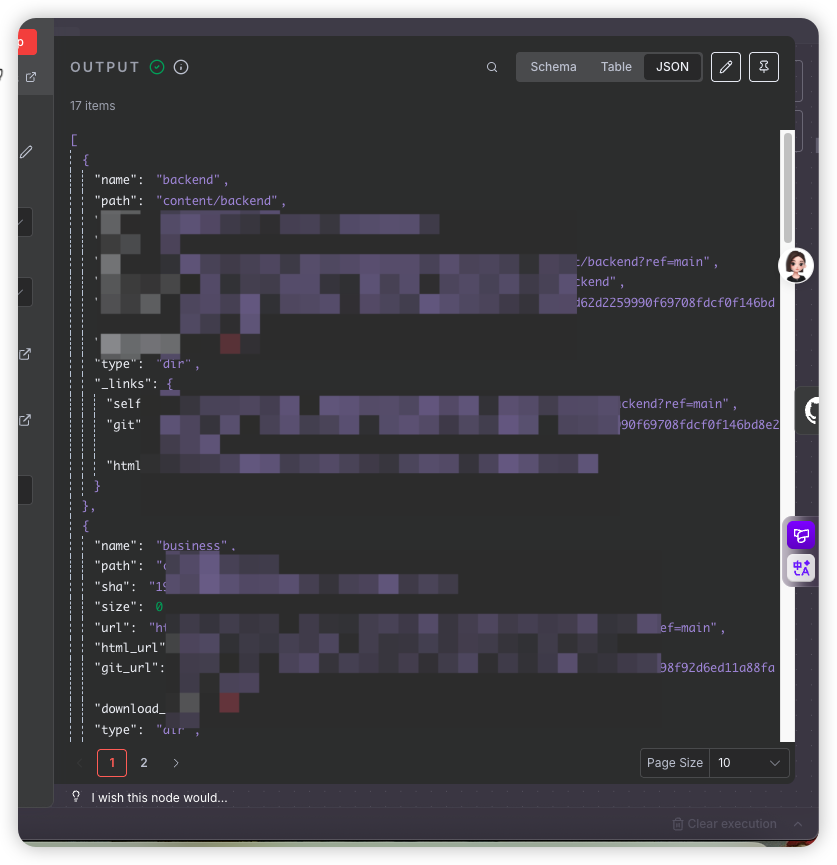
第3步:获取子目录列表文件 (第二个 GitHub 节点)
-
节点类型:GitHub
-
作用:这个节点接收上一步传来的列表。它很可能会遍历这个列表,如果发现某个项目是文件夹,它就会进入这个子文件夹,并获取该子文件夹内部所有文件的列表。
-
输出:一个更详细的文件列表,包含了各个子目录下的文件信息(提到的
d1-and-drizzle.mdx文件)。
同理在右上角添加github的 list files
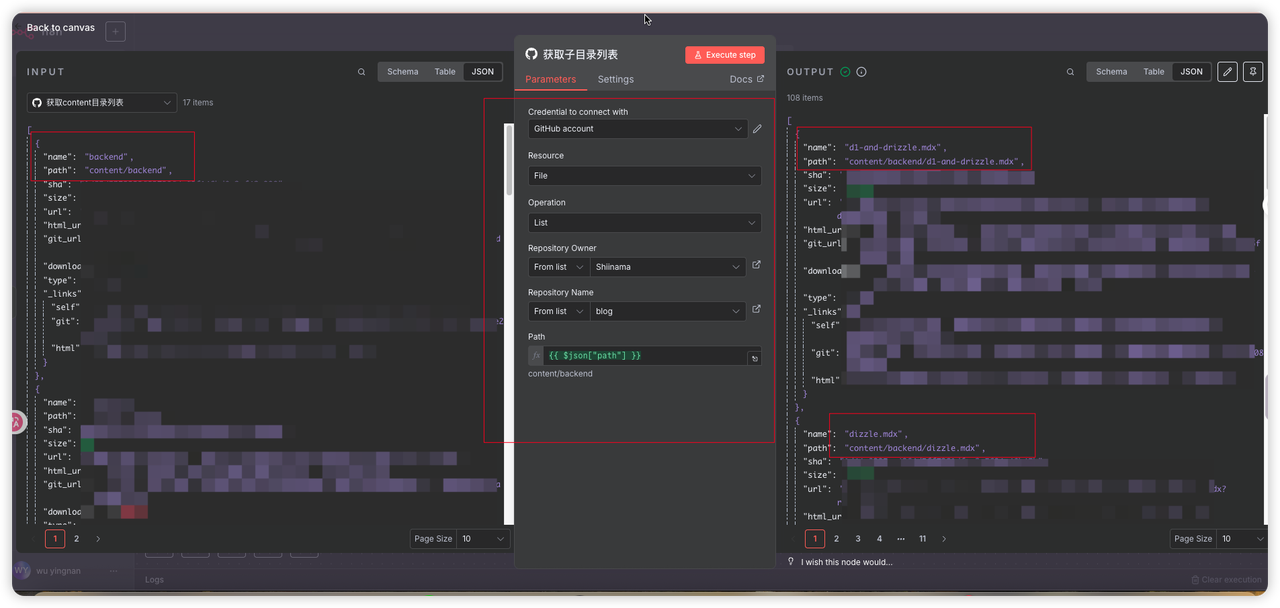
左侧的是我们上一个获取content目录列表请求到的结果
中间的参数填写完, 点击 Execute Step 会执行显示结果在右侧
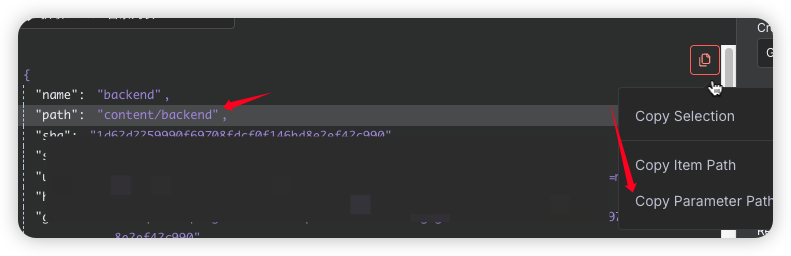
点击左侧path 选择复制
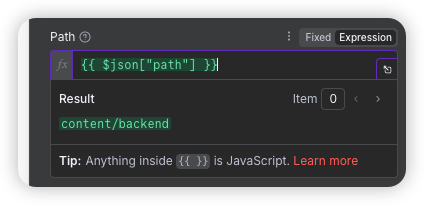
点击Execute step之后 我们可以在右侧得到显示的结果
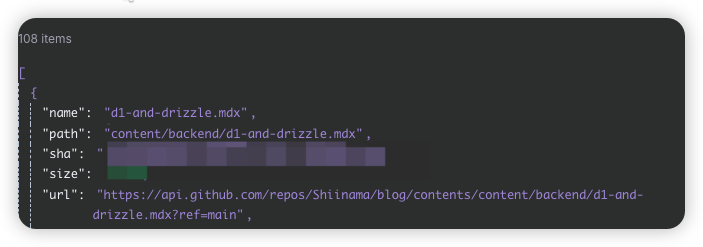
这一步之后,我们得到的就是目录下所有mdx文件格式的文章了之后我们需要进行IF过滤空值
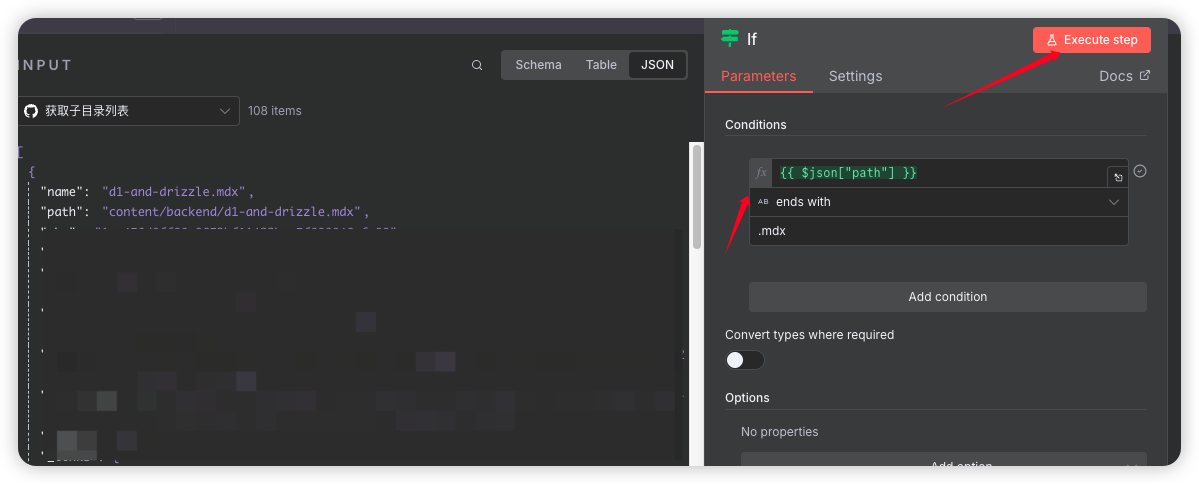
Path 为我们需要得到的内容, 对其进行IF判断 确保path的参数为 .mdx结尾 判空
第4步:IF 条件判断 (If)
-
节点类型:逻辑判断 (Logic)
-
作用:这是一个过滤器。它会检查从上一步获取到的每一个文件,并根据您设定的条件进行判断。条件是“文件名是否以
.mdx结尾?”或者“文件类型是否是file?”。 -
分支:
-
true (上):如果文件满足条件,就会从
true路径输出。从图上看,目前true路径没有连接任何节点。 -
false (下):如果文件不满足条件,就会从
false路径输出。在您的流程中,数据流从false路径继续向下走。 -
-
-
IF操作作为获取.mdx 防止.mdx内容为空的一层
IF的True节点进行连接下一个Code1节点
第5步:Code1 (第一个代码节点)
-
节点类型:Code
-
作用:这个节点接收从 IF 节点的
false路径传来的文件数据。处理和准备 URL。例如:-
从文件数据中提取
url或_links.self字段。 -
使用代码去掉 URL 中多余的
?ref=main部分,生成一个干净的、可用于请求原始文件内容的 URL。
-
-
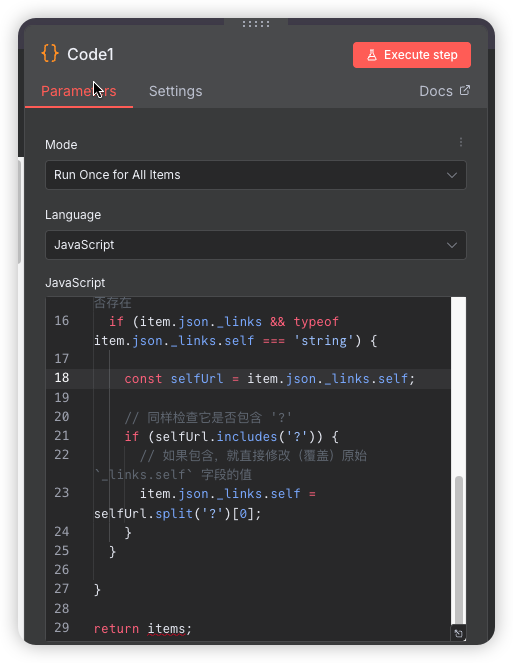
左侧是待处理,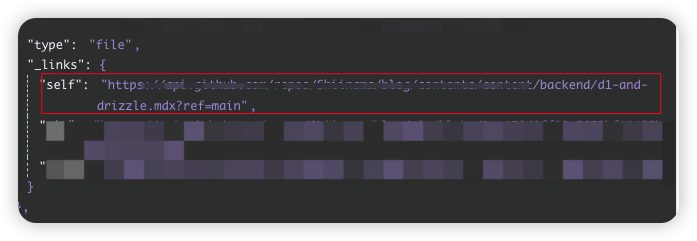
右侧是处理好的
代码如下
// n8n Code Node
for (const item of items) {// --- 第1部分:处理顶层的 'url' 字段 (和之前一样) ---const topLevelUrl = item.json.url;if (typeof topLevelUrl === 'string' && topLevelUrl.includes('?')) {// 创建一个新的 'cleanUrl' 字段item.json.cleanUrl = topLevelUrl.split('?')[0];} else {item.json.cleanUrl = topLevelUrl;}// --- 第2部分:【新增】处理嵌套的 '_links.self' 字段 ---// 先安全地检查 _links 对象和 _links.self 字段是否存在if (item.json._links && typeof item.json._links.self === 'string') {const selfUrl = item.json._links.self;// 同样检查它是否包含 '?'if (selfUrl.includes('?')) {// 如果包含,就直接修改(覆盖)原始 `_links.self` 字段的值item.json._links.self = selfUrl.split('?')[0];}}}return items;第6步:HTTP Request (HTTP请求节点)
-
节点类型:HTTP Request
-
作用:此节点会接收 Code1 处理好的干净 URL,然后向这个 URL 发起一个 HTTP GET 请求。它的目的就是获取文章的真正内容。您可能在这里设置了
Accept: application/vnd.github.raw的 Header,来直接获取 Markdown 的源文本。
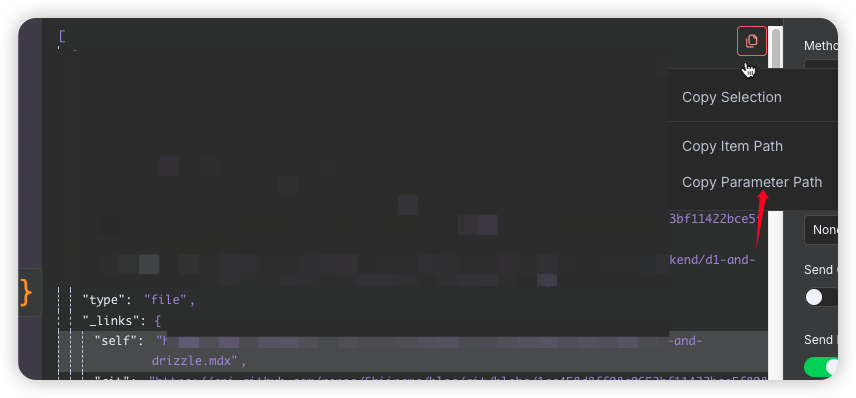
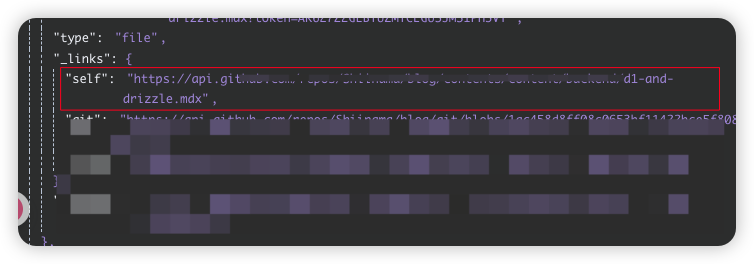
URL里面填写下面的self
我们需要添加请求头,让github了解到我们的请求的是私有仓库和响应格式
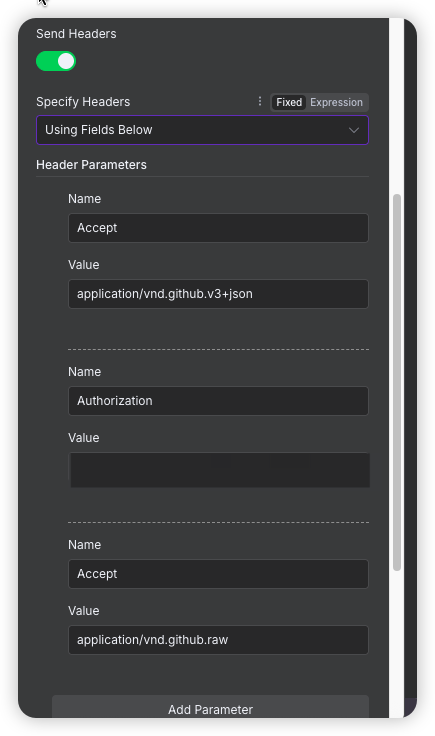
Value里面需要填写我们申请的Key
格式:
token key //记得中间有空格请求头名称 (Name): Accept 请求头
内容 (application/vnd.github.v3+json) 分解:
-
application/vnd.github:这是一个特定的媒体类型 (Media Type),表示这是针对 GitHub API 的请求。 -
v3:这部分指定了你希望使用 REST API 的 V3 版本。,可以确保你的应用不会因为未来 GitHub API 的版本更新而意外中断。 -
+json:这表示你希望服务器返回的数据是 JSON 格式。
请求头名称 (Name): Accept
请求头值 (Value): application/vnd.github.raw
核心目的:直接获取文件的原始(Raw)内容。
执行 Execute step 右侧可以读取到文件的内容了
原文用markdown写的,输出原格式内容了
关于我的一些介绍
