OpenCV 官翻8 - 其他算法
文章目录
- 高动态范围成像
- 引言
- 曝光序列
- 源代码
- 示例图像
- 说明
- 结果
- 色调映射图像
- 曝光融合
- 附加资源
- 高级图像拼接 API(Stitcher 类)
- 目标
- 代码
- 说明
- 相机模型
- 试用指南
- 图像拼接详解 (Python OpenCV >4.0.1)
- stitching_detailed
- 如何使用背景减除方法
- 目标
- 代码
- 代码解析
- 结果
- 参考文献
- Meanshift 与 Camshift 算法
- 目标
- Meanshift算法
- OpenCV 中的 Meanshift 算法
- Camshift
- OpenCV 中的 Camshift 算法
- 其他资源
- 练习
- 光流
- 目标
- Lucas-Kanade 方法
- OpenCV中的Lucas-Kanade光流法
- OpenCV中的稠密光流
- 级联分类器
- 目标
- 理论
- OpenCV 中的 Haar 级联检测
- 运行结果
- 附加资源
- 级联分类器训练
- 简介
- 重要说明
- 训练数据准备
- 负样本
- 正样本
- 额外说明
- 使用 OpenCV 的集成标注工具
- 级联训练
- 可视化级联分类器
- 条形码识别
- 目标
- 基础概念
- 代码示例
- 主类
- 初始化
- 检测
- 解码
- 检测与解码
- 结果
- 支持向量机简介
- 目标
- 什么是支持向量机?
- 最优超平面是如何计算的?
- 源代码
- 说明
- **设置训练数据**
- **设置SVM参数**
- **SVM分类的区域**
- 支持向量
- 实验结果
- 支持向量机处理非线性可分数据
- 目标
- 动机
- 优化问题的扩展
- 源代码
- 说明
- 设置训练数据
- 设置支持向量机参数
- 显示决策区域
- 支持向量
- 结果
- 主成分分析(PCA)简介
- 目标
- 什么是PCA?
- 如何计算特征向量和特征值?
- 源代码
- 说明
- 读取图像并转换为二值图像
- 提取目标对象
- 提取方向
- 结果
高动态范围成像
https://docs.opencv.org/4.x/d3/db7/tutorial_hdr_imaging.html
下一篇教程: 高级图像拼接API (Stitcher类)
| 原作者 | Fedor Morozov |
| 兼容性 | OpenCV >= 3.0 |
引言
如今大多数数字图像和成像设备每个通道使用8位,因此将设备的动态范围限制在两个数量级(实际为256级),而人眼能适应跨越十个数量级的光照条件变化。当我们拍摄真实场景时,亮部区域可能过曝,暗部区域可能欠曝,因此无法通过单次曝光捕捉所有细节。高动态范围(HDR)成像使用每个通道超过8位(通常为32位浮点值)的图像,从而支持更广的动态范围。
获取HDR图像有多种方法,最常见的是对同一场景拍摄不同曝光值的照片。要合成这些曝光图像,了解相机的响应函数很有帮助,现有算法可对其进行估算。HDR图像合成后需转换回8位才能在普通显示器上查看,这一过程称为色调映射。当场景中的物体或相机在拍摄间移动时会产生额外复杂性,因为不同曝光的图像需要配准和对齐。
本教程展示如何通过曝光序列生成并显示HDR图像。本案例中图像已预先对齐且无移动物体。我们还将演示一种称为曝光融合的替代方法,该方法能生成低动态范围图像。HDR流程的每个步骤可采用不同算法实现,具体可查阅参考手册了解全部选项。
曝光序列

源代码
以下展示本教程的代码行。你也可以从C++下载。
Python
以下展示本教程的代码行。你也可以从这里下载。
from __future__ import print_function
from __future__ import division
import cv2 as cv
import numpy as np
import argparse
import osdef loadExposureSeq(path):images = []times = []with open(os.path.join(path, 'list.txt')) as f:content = f.readlines()for line in content:tokens = line.split()images.append(cv.imread(os.path.join(path, tokens[0])))times.append(1 / float(tokens[1]))return images, np.asarray(times, dtype=np.float32)parser = argparse.ArgumentParser(description='Code for High Dynamic Range Imaging tutorial.')
parser.add_argument('--input', type=str, help='Path to the directory that contains images and exposure times.')
args = parser.parse_args()if not args.input:parser.print_help()exit(0)images, times = loadExposureSeq(args.input)calibrate = cv.createCalibrateDebevec()
response = calibrate.process(images, times)merge_debevec = cv.createMergeDebevec()
hdr = merge_debevec.process(images, times, response)tonemap = cv.createTonemapDrago(2.2)
ldr = tonemap.process(hdr)merge_mertens = cv.createMergeMertens()
fusion = merge_mertens.process(images)cv.imwrite('fusion.png', fusion * 255)
cv.imwrite('ldr.png', ldr * 255)
cv.imwrite('hdr.hdr', hdr)
示例图像
包含图像、曝光时间和list.txt文件的数据目录可从此处下载。
说明
- 加载图像和曝光时间
images, times = loadExposureSeq(args.input)
首先我们从用户定义的文件夹加载输入图像和曝光时间。该文件夹应包含图像和list.txt文件,其中记录了文件名及对应的逆曝光时间。
针对我们的图像序列,列表内容如下:
memorial00.png 0.03125memorial01.png 0.0625...memorial15.png 1024
- 估计相机响应
calibrate = [cv.createCalibrateDebevec`](https://docs.opencv.org/4.x/d6/df5/group__photo__hdr.html#ga670bbeecf0aac14abf386083a57b7958)() response = calibrate.process(images, times)
许多HDR构建算法都需要了解相机响应函数(CRF)。我们采用一种校准算法来估算所有256个像素值的逆CRF。
- 生成HDR图像
merge_debevec = [cv.createMergeDebevec`](https://docs.opencv.org/4.x/d6/df5/group__photo__hdr.html#gab2c9fc25252aee0915733ff8ea987190)()hdr = merge_debevec.process(images, times, response)
我们使用Debevec的权重方案,利用前一项计算出的响应来构建HDR图像。
- 对HDR图像进行色调映射
tonemap = cv.createTonemapDrago(2.2)ldr = tonemap.process(hdr)
由于我们需要在普通LDR显示器上查看结果,因此必须将HDR图像映射到8位范围,同时保留大部分细节。这正是色调映射方法的主要目标。我们采用了带双边滤波的色调映射器,并将伽马校正值设为2.2。
- 执行曝光融合
merge_mertens = cv.createMergeMertens()fusion = merge_mertens.process(images)
当不需要HDR图像时,还有一种替代方法可以合并我们的曝光。这个过程称为曝光融合,生成的LDR图像不需要进行伽马校正。它也不使用照片的曝光值。
- 写入结果
cv.imwrite('fusion.png', fusion * 255)cv.imwrite('ldr.png', ldr * 255)cv.imwrite('hdr.hdr', hdr)
现在来看看结果。需要注意的是,HDR图像无法以常见图像格式存储,因此我们将其保存为Radiance图像(.hdr)。此外,所有HDR成像函数的返回结果范围都在[0,1]之间,因此我们需要将结果乘以255。
你可以尝试其他色调映射算法:cv::TonemapDrago、cv::TonemapMantiuk和cv::TonemapReinhard。你也可以根据自己照片的需求,调整HDR校准和色调映射方法中的参数。
结果
色调映射图像

曝光融合

附加资源
1、Paul E Debevec 和 Jitendra Malik。从照片中恢复高动态范围辐射图。收录于 ACM SIGGRAPH 2008 课程,第 31 页。ACM,2008 年。[68]](https://docs.opencv.org/4.x/d0/de3/citelist.html#CITEREF_dm97) 2、Mark A Robertson、Sean Borman 和 Robert L Stevenson。通过多重曝光改善动态范围。收录于《图像处理,1999 年国际会议论文集》,第 3 卷,第 159–163 页。IEEE,1999 年。[[228]
3、Tom Mertens、Jan Kautz 和 Frank Van Reeth。曝光融合。收录于《计算机图形学与应用,2007 年太平洋会议论文集》,第 382–390 页。IEEE,2007 年。[189]`
4、维基百科-HDR
5、从照片中恢复高动态范围辐射图(网页)
生成于 2025 年 4 月 30 日星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 创建
高级图像拼接 API(Stitcher 类)
https://docs.opencv.org/4.x/d8/d19/tutorial_stitcher.html
上一教程: 高动态范围成像
下一教程: 如何使用背景减除方法
| 原作者 | Jiri Horner |
| 兼容性 | OpenCV >= 3.2 |
目标
在本教程中,您将学习如何:
- 使用由
cv::Stitcher提供的高级图像拼接 API - 学习如何使用预配置的 Stitcher 配置,通过不同的相机模型进行图像拼接
代码
C++ 本教程的代码展示在下方。你可以从这里下载。
注意:C++版本包含一些额外功能选项,如图像分割(–d3)和更详细的错误处理机制,这些在Python示例中并未提供。
#!/usr/bin/env python'''
Stitching sample
================Show how to use Stitcher API from python in a simple way to stitch panoramas
or scans.
'''# Python 2/3 compatibility
from __future__ import print_functionimport numpy as np
import cv2 as cvimport argparse
import sysmodes = (cv.Stitcher_PANORAMA, cv.Stitcher_SCANS)parser = argparse.ArgumentParser(prog='stitching.py', description='Stitching sample.')
parser.add_argument('--mode',type = int, choices = modes, default = cv.Stitcher_PANORAMA,help = 'Determines configuration of stitcher. The default is `PANORAMA` (%d), ''mode suitable for creating photo panoramas. Option `SCANS` (%d) is suitable ''for stitching materials under affine transformation, such as scans.' % modes)
parser.add_argument('--output', default = 'result.jpg',help = 'Resulting image. The default is `result.jpg`.')
parser.add_argument('img', nargs='+', help = 'input images')__doc__ += '\n' + parser.format_help()def main():args = parser.parse_args()# read input imagesimgs = []for img_name in args.img:img = cv.imread(cv.samples.findFile(img_name))if img is None:print("can't read image " + img_name)sys.exit(-1)imgs.append(img)#![stitching]stitcher = cv.Stitcher.create(args.mode)status, pano = stitcher.stitch(imgs)if status != cv.Stitcher_OK:print("Can't stitch images, error code = %d" % status)sys.exit(-1)#![stitching]cv.imwrite(args.output, pano)print("stitching completed successfully. %s saved!" % args.output)print('Done')if __name__ == '__main__':print(__doc__)main()cv.destroyAllWindows()
说明
最重要的代码部分是:
stitcher = cv.Stitcher.create(args.mode)status, pano = stitcher.stitch(imgs)if status != cv.Stitcher_OK:print("Can't stitch images, error code = %d" % status)sys.exit(-1)
创建了一个新的stitcher实例,cv::Stitcher::stitch 将完成所有繁重的工作。
cv::Stitcher::create 可以用预定义的配置模式(参数 mode)创建stitcher。详情请参阅 cv::Stitcher::Mode。这些配置会设置多个stitcher属性,使其在预定义的场景下运行。在以预定义配置创建stitcher后,您可以通过设置任意stitcher属性来调整拼接效果。
如果拥有CUDA设备,可以配置 cv::Stitcher 将某些操作卸载到GPU上执行。若需此配置,请将 try_use_gpu 设为true。无论此标志如何设置,OpenCL加速都会基于OpenCV的全局设置透明地启用。
拼接可能因多种原因失败,您应始终检查是否一切正常,并确认生成的全景图已存入 pano。可能的错误代码请参阅 cv::Stitcher::Status 文档。
相机模型
目前拼接流水线中实现了两种相机模型:
-
单应性模型:适用于图像间存在透视变换的场景,相关实现类包括
cv::detail::BestOf2NearestMatcher、cv::detail::HomographyBasedEstimator、cv::detail::BundleAdjusterReproj和cv::detail::BundleAdjusterRay -
仿射模型:支持6自由度或4自由度的仿射变换,相关实现类包括
cv::detail::AffineBestOf2NearestMatcher、cv::detail::AffineBasedEstimator、cv::detail::BundleAdjusterAffine、cv::detail::BundleAdjusterAffinePartial以及cv::AffineWarper
单应性模型适用于创建普通相机拍摄的照片全景图,而基于仿射的模型可用于拼接专业设备获取的扫描件和物体图像。
注意:cv::Stitcher 的某些详细设置可能不适用。特别要注意不应混用实现仿射模型的类和实现单应性模型的类,因为它们处理的是不同类型的变换。
试用指南
如果启用了示例构建,你可以在 build/bin/cpp-example-stitching 目录下找到可执行文件。该示例是一个控制台应用程序,不带参数运行即可查看帮助信息。opencv_extra 提供了一些测试所有可用配置的样本数据。
要尝试全景模式,请运行:
./cpp-example-stitching --mode panorama <path to opencv_extra>/testdata/stitching/boat*

或者(来自专业书籍扫描仪的数据集):
./cpp-example-stitching --mode scans <path to opencv_extra>/testdata/stitching/budapest*

注意:上述示例基于POSIX平台,在Windows系统中需显式提供所有文件名(如boat1.jpg boat2.jpg…),因为Windows命令行不支持*通配符扩展。
图像拼接详解 (Python OpenCV >4.0.1)
如果你想研究拼接流程的内部实现,或者希望进行详细配置的实验,可以使用C++或Python版本的stitching_detailed源代码。
stitching_detailed
C++ stitching_detailed.cpp
Python stitching_detailed.py
stitching_detailed 程序通过命令行获取图像拼接参数。该程序支持众多参数配置,上述示例展示了部分可用的命令行参数:
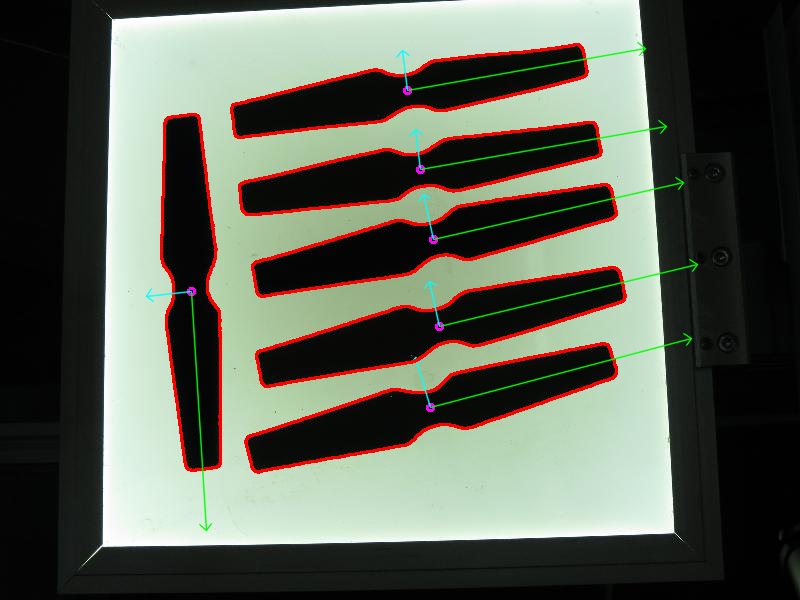
boat5.jpg boat2.jpg boat3.jpg boat4.jpg boat1.jpg boat6.jpg –work_megapix 0.6 –features orb –matcher homography –estimator homography –match_conf 0.3 –conf_thresh 0.3 –ba ray –ba_refine_mask xxxxx –save_graph test.txt –wave_correct no –warp fisheye –blend multiband –expos_comp no –seam gc_colorgrad

配对图像通过单应性矩阵进行匹配:
- 使用单应性匹配器
–matcher homography - 变换估计也采用单应性估计器
–estimator homography
特征匹配步骤的置信度阈值为 0.3:–match_conf 0.3。若图像匹配困难,可适当降低该值
判断两图是否属于同一全景图的置信度阈值为 0.3:–conf_thresh 0.3。若匹配困难,可降低此值
光束法平差(Bundle Adjustment)采用射线成本函数:–ba ray
光束法平差的优化掩码格式为 xxxxx(–ba_refine_mask xxxxx):
- ‘x’ 表示优化对应参数
- ‘_’ 表示不优化
格式说明:fx(焦距x), skew(倾斜系数), ppx(主点x), aspect(纵横比), ppy(主点y)
将匹配关系图以DOT语言格式保存至test.txt(–save_graph test.txt):
- 标签说明:Nm表示匹配数,Ni表示内点数,C表示置信度
波形校正功能关闭(–wave_correct no)
曲面变形类型为鱼眼(–warp fisheye)
融合方法采用多频段混合(–blend multiband)
曝光补偿功能未启用(–expos_comp no)
接缝估计算法基于最小图割色彩梯度(–seam gc_colorgrad)
这些参数也可直接在命令行中使用:
boat5.jpg boat2.jpg boat3.jpg boat4.jpg boat1.jpg boat6.jpg –work_megapix 0.6 –features orb –matcher homography –estimator homography –match_conf 0.3 –conf_thresh 0.3 –ba ray –ba_refine_mask xxxxx –wave_correct horiz –warp compressedPlaneA2B1 –blend multiband –expos_comp channels_blocks –seam gc_colorgrad
您将获得:

对于使用扫描仪或无人机(仿射运动)捕获的图像,您可以在命令行中使用以下参数:
newspaper1.jpg newspaper2.jpg –work_megapix 0.6 –features surf –matcher affine –estimator affine –match_conf 0.3 –conf_thresh 0.3 –ba affine –ba_refine_mask xxxxx –wave_correct no –warp affine

你可以在 https://github.com/opencv/opencv_extra/tree/4.x/testdata/stitching 找到所有图像
生成于 2025年4月30日 星期三 23:08:42 为 OpenCV 由 doxygen 1.12.0 创建
如何使用背景减除方法
https://docs.opencv.org/4.x/d1/dc5/tutorial_background_subtraction.html
上一教程: 高级图像拼接API(Stitcher类)
下一教程: 均值漂移与连续自适应均值漂移
| 原作者 | Domenico Daniele Bloisi |
| 兼容性 | OpenCV >= 3.0 |
- 背景减除(BS)是一种通过静态摄像头生成前景掩模(即包含场景中运动物体像素的二值图像)的常用技术。
- 顾名思义,BS通过计算当前帧与背景模型之间的差值来获取前景掩模,背景模型包含场景的静态部分,或者更广义地说,包含根据观察场景特性可被视为背景的所有内容。

- 背景建模包含两个主要步骤:
- 背景初始化;
- 背景更新。第一步计算背景的初始模型,第二步则更新该模型以适应场景中可能发生的变化。
- 本教程将学习如何使用OpenCV执行背景减除。
目标
在本教程中,您将学习如何:
1、使用 cv::VideoCapture 从视频或图像序列中读取数据;
2、通过 cv::BackgroundSubtractor 类创建并更新背景模型;
3、利用 cv::imshow 获取并显示前景掩膜;
代码
以下提供源代码示例。我们将允许用户选择处理视频文件或图像序列。
本示例将使用 cv::BackgroundSubtractorMOG2 来生成前景掩模。
处理结果和输入数据都会实时显示在屏幕上。
可下载代码:C++ | Java | Python
代码概览:
from __future__ import print_function
import cv2 as cv
import argparseparser = argparse.ArgumentParser(description='This program shows how to use background subtraction methods provided by \OpenCV. You can process both videos and images.')
parser.add_argument('--input', type=str, help='Path to a video or a sequence of image.', default='vtest.avi')
parser.add_argument('--algo', type=str, help='Background subtraction method (KNN, MOG2).', default='MOG2')
args = parser.parse_args()if args.algo == 'MOG2':backSub = cv.createBackgroundSubtractorMOG2()
else:backSub = cv.createBackgroundSubtractorKNN()capture = cv.VideoCapture(cv.samples.findFileOrKeep(args.input))
if not capture.isOpened():print('Unable to open: ' + args.input)exit(0)while True:ret, frame = capture.read()if frame is None:breakfgMask = backSub.apply(frame)cv.rectangle(frame, (10, 2), (100,20), (255,255,255), -1)cv.putText(frame, str(capture.get(cv.CAP_PROP_POS_FRAMES)), (15, 15),cv.FONT_HERSHEY_SIMPLEX, 0.5 , (0,0,0))cv.imshow('Frame', frame)cv.imshow('FG Mask', fgMask)keyboard = cv.waitKey(30)if keyboard == 'q' or keyboard == 27:break
代码解析
我们将讨论上述代码的主要部分:
- 使用
cv::BackgroundSubtractor对象来生成前景掩膜。本示例中使用的是默认参数,但也可以通过 create 函数声明特定参数。
if args.algo == 'MOG2':backSub = cv.createBackgroundSubtractorMOG2()
else:backSub = cv.createBackgroundSubtractorKNN()
- 使用
cv::VideoCapture对象来读取输入视频或输入图像序列。
capture = cv.VideoCapture(cv.samples.findFileOrKeep(args.input))
if not capture.isOpened():print('Unable to open: ' + args.input)exit(0)
- 每一帧都同时用于计算前景掩膜和更新背景模型。若需调整更新背景模型时的学习率,可通过向
apply方法传递参数来设定特定学习率。
fgMask = backSub.apply(frame)
- 可以从
cv::VideoCapture对象中提取当前帧号,并将其标记在当前帧的左上角。使用白色矩形框突出显示黑色的帧号。
cv.rectangle(frame, (10, 2), (100,20), (255,255,255), -1)cv.putText(frame, str(capture.get(cv.CAP_PROP_POS_FRAMES)), (15, 15),cv.FONT_HERSHEY_SIMPLEX, 0.5 , (0,0,0))
- 我们准备展示当前输入帧及处理结果。
cv.imshow('Frame', frame)cv.imshow('FG Mask', fgMask)
结果
对于 vtest.avi 视频中的以下帧:

程序使用 MOG2 方法输出的结果如下(灰色区域为检测到的阴影):

程序使用 KNN 方法输出的结果如下(灰色区域为检测到的阴影):

参考文献
- 背景模型挑战赛(BMC)官网
- 前景/背景提取基准数据集 [281]`
本文档由 doxygen 1.12.0 生成于 2025年4月30日 星期三 23:08:42,针对 OpenCV 项目
Meanshift 与 Camshift 算法
https://docs.opencv.org/4.x/d7/d00/tutorial_meanshift.html
上一教程: 如何使用背景减除方法
下一教程: 光流法
目标
在本章节中,
- 我们将学习用于视频中目标追踪的Meanshift和Camshift算法。
Meanshift算法
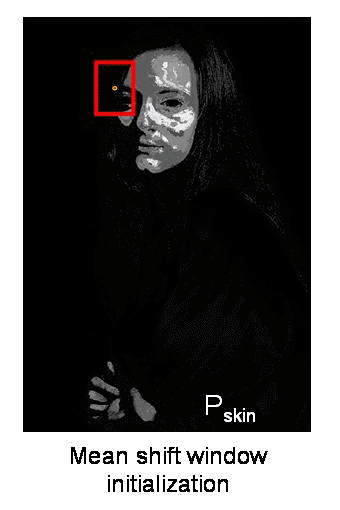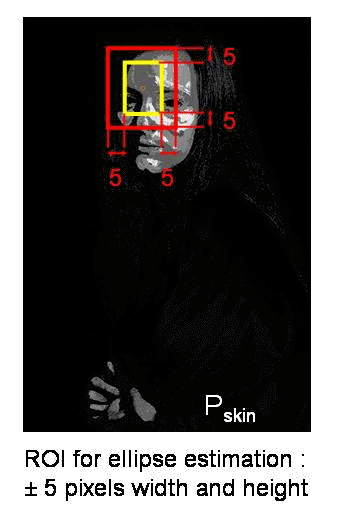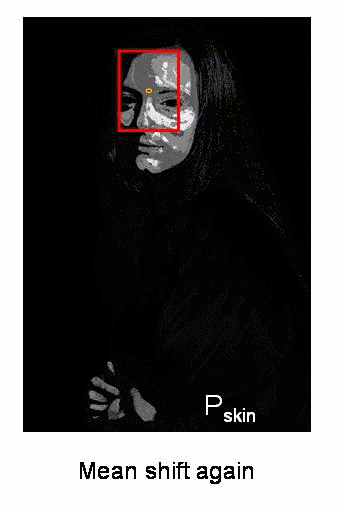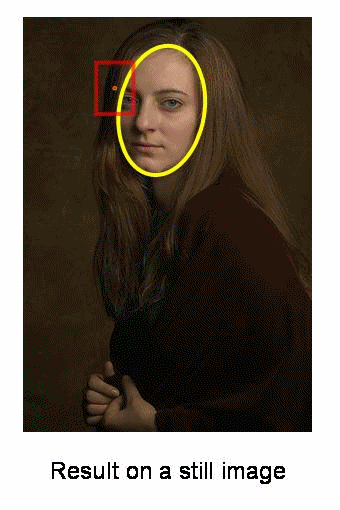
Meanshift背后的原理很简单。假设你有一组点集(可以是像直方图反向投影这样的像素分布)。给你一个小窗口(可能是个圆形),你需要将这个窗口移动到像素密度最大(或点数最多)的区域。下面这张简单的示意图说明了这个过程:
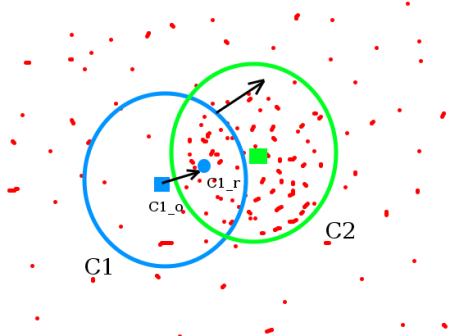
初始窗口显示为蓝色圆圈,标注为"C1"。其原始中心用蓝色矩形标记为"C1_o"。但如果计算窗口内所有点的质心,你会得到标记为"C1_r"的点(用小蓝圈表示),这才是窗口的真实质心。显然两者不重合。因此移动窗口,使新窗口的圆形与之前的质心重合。再次计算新质心,很可能还是不匹配。于是继续移动窗口,如此迭代直到窗口中心与其质心落在同一位置(或误差足够小)。最终得到的就是像素分布最密集的窗口,图中用绿色圆圈标注为"C2"。可以看到,这个区域包含了最多的点。整个过程在下方的静态图像演示中更为直观:

通常我们会传入直方图反向投影图像和初始目标位置。当物体移动时,这种运动会在反向投影图像中体现出来。Meanshift算法因此会将窗口移动到新的密度最大区域。
OpenCV 中的 Meanshift 算法
要在 OpenCV 中使用 meanshift 算法,首先需要设置目标区域并计算其直方图,这样我们才能在每一帧上通过反向投影目标区域来计算 meanshift。同时还需要提供窗口的初始位置。对于直方图,这里仅考虑色调(Hue)分量。此外,为了避免低光照导致的错误值,可以使用 cv.inRange() 函数来剔除低光值。
可下载代码: C++ | Java | Python
代码概览:
import numpy as np
import cv2 as cv
import argparseparser = argparse.ArgumentParser(description='This sample demonstrates the meanshift algorithm. \The example file can be downloaded from: \https://www.bogotobogo.com/python/OpenCV_Python/images/mean_shift_tracking/slow_traffic_small.mp4')
parser.add_argument('image', type=str, help='path to image file')
args = parser.parse_args()cap = cv.VideoCapture(args.image)# take first frame of the video
ret,frame = cap.read()# setup initial location of window
x, y, w, h = 300, 200, 100, 50 # simply hardcoded the values
track_window = (x, y, w, h)# set up the ROI for tracking
roi = frame[y:y+h, x:x+w]
hsv_roi = cv.cvtColor(roi, cv.COLOR_BGR2HSV)
mask = cv.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv.normalize(roi_hist,roi_hist,0,255,cv.NORM_MINMAX)# Setup the termination criteria, either 10 iteration or move by at least 1 pt
term_crit = ( cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 1 )while(1):ret, frame = cap.read()if ret == True:hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)dst = cv.calcBackProject([hsv],[0],roi_hist,[0,180],1)# apply meanshift to get the new locationret, track_window = cv.meanShift(dst, track_window, term_crit)# Draw it on imagex,y,w,h = track_windowimg2 = cv.rectangle(frame, (x,y), (x+w,y+h), 255,2)cv.imshow('img2',img2)k = cv.waitKey(30) & 0xffif k == 27:breakelse:break
以下是我使用的视频中的三帧画面:

图片
Camshift
你仔细观察过上一个结果吗?这里有个问题。无论汽车离摄像头很远还是很近,我们的窗口始终保持相同大小。这显然不够理想。我们需要根据目标物体的大小和旋转来自适应调整窗口尺寸。这个解决方案再次来自"OpenCV实验室",由Gary Bradsky在其1998年发表的论文《用于感知用户界面的计算机视觉人脸追踪》中提出,称为CAMshift(持续自适应均值漂移)算法[40]。
该算法首先应用均值漂移。当均值漂移收敛后,它会按照公式更新窗口尺寸,同时计算最佳拟合椭圆的方向。接着,算法会使用新的缩放搜索窗口和先前窗口位置再次应用均值漂移。这个过程会持续循环,直到达到所需的精度要求。
OpenCV 中的 Camshift 算法
- 可下载代码:C++ | Java | Python
import numpy as np
import cv2 as cv
import argparseparser = argparse.ArgumentParser(description='This sample demonstrates the camshift algorithm. \The example file can be downloaded from: \https://www.bogotobogo.com/python/OpenCV_Python/images/mean_shift_tracking/slow_traffic_small.mp4')
parser.add_argument('image', type=str, help='path to image file')
args = parser.parse_args()cap = cv.VideoCapture(args.image)# take first frame of the video
ret,frame = cap.read()# setup initial location of window
x, y, w, h = 300, 200, 100, 50 # simply hardcoded the values
track_window = (x, y, w, h)# set up the ROI for tracking
roi = frame[y:y+h, x:x+w]
hsv_roi = cv.cvtColor(roi, cv.COLOR_BGR2HSV)
mask = cv.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv.normalize(roi_hist,roi_hist,0,255,cv.NORM_MINMAX)# Setup the termination criteria, either 10 iteration or move by at least 1 pt
term_crit = ( cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 1 )while(1):ret, frame = cap.read()if ret == True:hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)dst = cv.calcBackProject([hsv],[0],roi_hist,[0,180],1)# apply camshift to get the new locationret, track_window = cv.CamShift(dst, track_window, term_crit)# Draw it on imagepts = cv.boxPoints(ret)pts = np.int0(pts)img2 = cv.polylines(frame,[pts],True, 255,2)cv.imshow('img2',img2)k = cv.waitKey(30) & 0xffif k == 27:breakelse:break
结果显示的三帧如下:

其他资源
- 法语维基百科关于Camshift的页面(其中的两个动画取自该页面)
- Bradski, G.R. 发表的论文《实时人脸与物体跟踪作为感知用户界面的组成部分》,收录于1998年10月19-21日第四届IEEE应用计算机视觉研讨会(WACV '98)论文集,第214-219页
练习
- OpenCV 附带了一个 Python 示例,用于演示 camshift 的交互式功能。请使用它、修改它并理解它。
光流
https://docs.opencv.org/4.x/d4/dee/tutorial_optical_flow.html
上一教程: Meanshift 和 Camshift
下一教程: 级联分类器
目标
在本章中,
- 我们将理解光流的概念及其使用Lucas-Kanade方法的估计原理。
- 我们将使用
cv.calcOpticalFlowPyrLK()等函数来追踪视频中的特征点。 - 我们将通过
cv.calcOpticalFlowFarneback()方法创建稠密光流场。
光流是指由于物体或相机运动导致图像对象在连续两帧之间产生的表观运动模式。它是一个二维向量场,每个向量表示点从第一帧到第二帧的位移向量。请看下图(图片来源:维基百科光流条目):
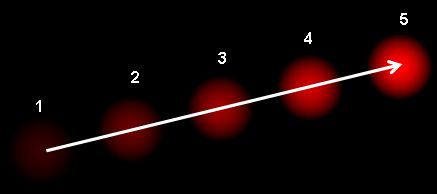
图中展示了一个球在连续5帧中的运动轨迹,箭头表示其位移向量。光流在以下领域有广泛应用:
- 运动恢复结构
- 视频压缩
- 视频稳定…
光流计算基于以下假设:
- 物体的像素强度在连续帧之间不会改变
- 相邻像素具有相似的运动
假设第一帧中某像素为 \(I(x,y,t)\)(注意这里新增了时间维度,之前我们只处理静态图像,所以不需要时间参数)。该像素在 \(dt\) 时间后的下一帧中移动了 \((dx,dy)\) 距离。由于像素相同且强度不变,可以得到:
\[I(x,y,t) = I(x+dx, y+dy, t+dt)\]
对右边进行泰勒级数展开,消去相同项后除以 \(dt\),得到光流方程:
\[f_x u + f_y v + f_t = 0 \;\]
其中:
\[f_x = \frac{\partial f}{\partial x} \; ; \; f_y = \frac{\partial f}{\partial y}\]
\[u = \frac{dx}{dt} \; ; \; v = \frac{dy}{dt}\]
该方程中,\(f_x\) 和 \(f_y\) 是图像梯度,\(f_t\) 是时间梯度。但 \((u,v)\) 未知,一个方程无法求解两个未知数,因此发展出多种解决方法,Lucas-Kanade 就是其中之一。
Lucas-Kanade 方法
我们之前提到过一个假设:相邻像素具有相似的运动。Lucas-Kanade 方法会在目标点周围取一个 3x3 的像素块,因此这 9 个点具有相同的运动。我们可以求出这 9 个点的 \((f_x, f_y, f_t)\)。于是问题转化为用 9 个方程求解两个未知数的超定方程组。通过最小二乘法可以获得更好的解。以下是最终解的形式——这是一个二元方程组,求解后即可得到结果:
\[\begin{bmatrix} u \\ v \end{bmatrix} =
\begin{bmatrix}
\sum_{i}{f_{x_i}}^2 & \sum_{i}{f_{x_i} f_{y_i} } \\
\sum_{i}{f_{x_i} f_{y_i}} & \sum_{i}{f_{y_i}}^2
\end{bmatrix}^{-1}
\begin{bmatrix}
- \sum_{i}{f_{x_i} f_{t_i}} \\
- \sum_{i}{f_{y_i} f_{t_i}}
\end{bmatrix}\]
(注意逆矩阵与 Harris 角点检测器的相似性。这说明角点更适合被追踪。)
从用户的角度来看,原理很简单:我们提供一些待追踪的点,就能获得这些点的光流向量。但这种方法仍存在一些问题。目前我们处理的都是小幅度运动,当运动幅度较大时就会失效。为了解决这个问题,我们使用图像金字塔结构。当我们在金字塔上层处理时,小幅运动被忽略,而大幅运动转化为小幅运动。因此在金字塔上应用 Lucas-Kanade 方法,我们就能获得带有尺度信息的光流。
OpenCV中的Lucas-Kanade光流法
OpenCV通过单一函数 cv.calcOpticalFlowPyrLK() 提供了完整实现。我们将创建一个简单的视频点追踪应用,首先使用 cv.goodFeaturesToTrack() 在第一帧中识别Shi-Tomasi角点,然后通过Lucas-Kanade光流法迭代追踪这些点。
调用 cv.calcOpticalFlowPyrLK() 时需要传入前一帧、前一帧的特征点以及当前帧。函数会返回当前帧的特征点坐标和状态码(找到点时状态为1,否则为0)。在迭代过程中,我们将当前帧的特征点作为下一帧的"前一帧特征点"输入。具体实现如下:
示例代码下载:C++ | Java | Python
核心代码概览:
import numpy as np
import cv2 as cv
import argparseparser = argparse.ArgumentParser(description='This sample demonstrates Lucas-Kanade Optical Flow calculation. \The example file can be downloaded from: \https://www.bogotobogo.com/python/OpenCV_Python/images/mean_shift_tracking/slow_traffic_small.mp4')
parser.add_argument('image', type=str, help='path to image file')
args = parser.parse_args()cap = cv.VideoCapture(args.image)# params for ShiTomasi corner detection
feature_params = dict( maxCorners = 100,qualityLevel = 0.3,minDistance = 7,blockSize = 7 )# Parameters for lucas kanade optical flow
lk_params = dict( winSize = (15, 15),maxLevel = 2,criteria = (cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 0.03))# Create some random colors
color = np.random.randint(0, 255, (100, 3))# Take first frame and find corners in it
ret, old_frame = cap.read()
old_gray = cv.cvtColor(old_frame, cv.COLOR_BGR2GRAY)
p0 = cv.goodFeaturesToTrack(old_gray, mask = None, **feature_params)# Create a mask image for drawing purposes
mask = np.zeros_like(old_frame)while(1):ret, frame = cap.read()if not ret:print('No frames grabbed!')breakframe_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)# calculate optical flowp1, st, err = cv.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)# Select good pointsif p1 is not None:good_new = p1[st==1]good_old = p0[st==1]# draw the tracksfor i, (new, old) in enumerate(zip(good_new, good_old)):a, b = new.ravel()c, d = old.ravel()mask = cv.line(mask, (int(a), int(b)), (int(c), int(d)), color[i].tolist(), 2)frame = cv.circle(frame, (int(a), int(b)), 5, color[i].tolist(), -1)img = cv.add(frame, mask)cv.imshow('frame', img)k = cv.waitKey(30) & 0xffif k == 27:break# Now update the previous frame and previous pointsold_gray = frame_gray.copy()p0 = good_new.reshape(-1, 1, 2)cv.destroyAllWindows()
这段代码不会检查下一个关键点的准确性。因此,即使某个特征点在图像中消失,光流仍有可能找到一个看起来接近它的新点。为了实现更稳健的跟踪,应该定期重新检测角点。OpenCV示例中提供了一个相关样例,它会每5帧检测一次特征点,并对获得的光流点进行反向检查以筛选优质点。具体请查看 samples/python/lk_track.py。
以下是运行结果:

OpenCV中的稠密光流
Lucas-Kanade方法计算的是稀疏特征集的光流(在我们的例子中,是使用Shi-Tomasi算法检测到的角点)。OpenCV提供了另一种算法来寻找稠密光流,它会计算帧中所有点的光流。该算法基于Gunnar Farneback在2003年发表的论文《基于多项式展开的双帧运动估计》中提出的方法。
以下示例展示了如何使用上述算法查找稠密光流。我们会得到一个包含光流向量的2通道数组,然后计算它们的幅度和方向。为了更直观地展示结果,我们对结果进行了颜色编码:方向对应图像的色调(Hue)值,幅度对应明度(Value)平面。具体代码如下:
可下载代码:C++ | Java | Python
import numpy as np
import cv2 as cv
cap = cv.VideoCapture(cv.samples.findFile("vtest.avi"))
ret, frame1 = cap.read()
prvs = cv.cvtColor(frame1, cv.COLOR_BGR2GRAY)
hsv = np.zeros_like(frame1)
hsv[..., 1] = 255
while(1):ret, frame2 = cap.read()if not ret:print('No frames grabbed!')breaknext = cv.cvtColor(frame2, cv.COLOR_BGR2GRAY)flow = cv.calcOpticalFlowFarneback(prvs, next, None, 0.5, 3, 15, 3, 5, 1.2, 0)mag, ang = cv.cartToPolar(flow[..., 0], flow[..., 1])hsv[..., 0] = ang*180/np.pi/2hsv[..., 2] = cv.normalize(mag, None, 0, 255, cv.NORM_MINMAX)bgr = cv.cvtColor(hsv, cv.COLOR_HSV2BGR)cv.imshow('frame2', bgr)k = cv.waitKey(30) & 0xffif k == 27:breakelif k == ord('s'):cv.imwrite('opticalfb.png', frame2)cv.imwrite('opticalhsv.png', bgr)prvs = nextcv.destroyAllWindows()
查看下方结果:

级联分类器
https://docs.opencv.org/4.x/db/d28/tutorial_cascade_classifier.html
上一教程: 光流
下一教程: 级联分类器训练
| 原作者 | Ana Huamán |
| 兼容性 | OpenCV >= 3.0 |
目标
在本教程中:
- 我们将学习 Haar 级联对象检测的工作原理。
- 了解基于 Haar 特征级联分类器进行人脸检测和眼睛检测的基础知识。
- 使用
cv::CascadeClassifier类来检测视频流中的对象。具体将使用以下函数:cv::CascadeClassifier::load加载 .xml 分类器文件(支持 Haar 或 LBP 分类器)cv::CascadeClassifier::detectMultiScale执行检测任务。
理论
基于Haar特征的级联分类器进行目标检测是由Paul Viola和Michael Jones在2001年发表的论文《使用简单特征增强级联的快速目标检测》中提出的一种有效方法。这是一种基于机器学习的方法,通过大量正样本(包含人脸的图像)和负样本(不包含人脸的图像)训练级联函数,进而用于检测其他图像中的目标。
我们将以人脸检测为例进行说明。算法首先需要大量正样本(人脸图像)和负样本(非人脸图像)来训练分类器。接着需要从中提取特征,这里使用下图展示的Haar特征。这些特征类似于卷积核,每个特征值是通过计算黑色矩形区域像素和与白色矩形区域像素和的差值得到的。
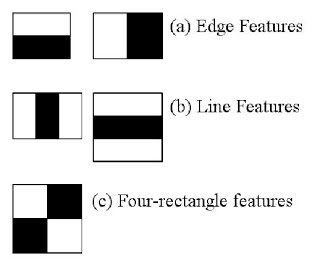
算法会使用所有可能的核尺寸和位置来计算大量特征(想象一下计算量有多大?即使24x24的窗口也会产生超过16万个特征)。为了高效计算每个特征中矩形区域的像素和,研究者引入了积分图技术。无论图像多大,积分图都能将任意矩形区域的像素和计算简化为仅涉及四个像素的操作,这极大地提升了计算效率。
但计算得到的特征中大部分是无关的。例如下图所示,第一行展示的两个有效特征:第一个特征捕捉到眼睛区域通常比鼻梁和脸颊区域更暗的特性,第二个特征利用了眼睛比鼻梁更暗的特性。而相同的检测窗口应用于脸颊等其他区域则无效。那么如何从16万+特征中筛选最优特征呢?这通过Adaboost算法实现。

具体实现时,所有特征会在训练图像上进行测试。每个特征会找到一个最佳阈值来区分人脸和非人脸。显然会出现误分类情况,我们选择错误率最低的特征(即最能准确区分人脸与非人脸的特征)。这个过程并非简单的一次筛选:初始时所有图像权重相同,每次分类后增加误分类图像的权重,迭代进行直到达到预定精度或特征数量(最终分类器是这些弱分类器的加权组合,单个弱分类器效果有限,但组合后形成强分类器)。论文指出,仅200个特征就能达到95%的检测准确率,最终系统使用了约6000个特征(从16万+到6000,这是巨大的优化)。
现在检测流程是:对图像的每个24x24窗口应用6000个特征判断是否为人脸。这显然效率低下,为此研究者提出了创新方案——由于图像中大部分区域是非人脸区域,他们设计了级联分类器:将特征分组到不同阶段逐级应用(前几阶段特征数很少),若窗口未通过某阶段则立即丢弃,仅对可能包含人脸的窗口进行后续检测。例如作者的检测器包含38个阶段共6000+特征,前五个阶段分别有1、10、25、25和50个特征,平均每个子窗口只需评估10个特征。
这就是Viola-Jones人脸检测算法的工作原理简介。如需更多细节请参阅原论文或查看附加资源中的参考文献。
OpenCV 中的 Haar 级联检测
OpenCV 提供了训练方法(参见 Cascade Classifier Training)或预训练模型,这些模型可以通过 cv::CascadeClassifier::load 方法读取。预训练模型位于 OpenCV 安装目录的 data 文件夹中,也可以从这里获取。
以下代码示例将使用预训练的 Haar 级联模型来检测图像中的面部和眼睛。首先,创建一个 cv::CascadeClassifier,并通过 cv::CascadeClassifier::load 方法加载所需的 XML 文件。随后,使用 cv::CascadeClassifier::detectMultiScale 方法进行检测,该方法会返回检测到的面部或眼睛的边界矩形。
本教程的代码如下所示。你也可以从以下链接下载:C++ | Java | Python。
from __future__ import print_function
import cv2 as cv
import argparsedef detectAndDisplay(frame):frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)frame_gray = cv.equalizeHist(frame_gray)#-- Detect facesfaces = face_cascade.detectMultiScale(frame_gray)for (x,y,w,h) in faces:center = (x + w//2, y + h//2)frame = cv.ellipse(frame, center, (w//2, h//2), 0, 0, 360, (255, 0, 255), 4)faceROI = frame_gray[y:y+h,x:x+w]#-- In each face, detect eyeseyes = eyes_cascade.detectMultiScale(faceROI)for (x2,y2,w2,h2) in eyes:eye_center = (x + x2 + w2//2, y + y2 + h2//2)radius = int(round((w2 + h2)*0.25))frame = cv.circle(frame, eye_center, radius, (255, 0, 0 ), 4)cv.imshow('Capture - Face detection', frame)parser = argparse.ArgumentParser(description='Code for Cascade Classifier tutorial.')
parser.add_argument('--face_cascade', help='Path to face cascade.', default='data/haarcascades/haarcascade_frontalface_alt.xml')
parser.add_argument('--eyes_cascade', help='Path to eyes cascade.', default='data/haarcascades/haarcascade_eye_tree_eyeglasses.xml')
parser.add_argument('--camera', help='Camera divide number.', type=int, default=0)
args = parser.parse_args()face_cascade_name = args.face_cascade
eyes_cascade_name = args.eyes_cascadeface_cascade = cv.CascadeClassifier()
eyes_cascade = cv.CascadeClassifier()#-- 1. Load the cascades
if not face_cascade.load(cv.samples.findFile(face_cascade_name)):print('--(!)Error loading face cascade')exit(0)
if not eyes_cascade.load(cv.samples.findFile(eyes_cascade_name)):print('--(!)Error loading eyes cascade')exit(0)camera_device = args.camera
#-- 2. Read the video stream
cap = cv.VideoCapture(camera_device)
if not cap.isOpened:print('--(!)Error opening video capture')exit(0)while True:ret, frame = cap.read()if frame is None:print('--(!) No captured frame -- Break!')breakdetectAndDisplay(frame)if cv.waitKey(10) == 27:break
运行结果
1、以下是运行上述代码并使用内置摄像头视频流作为输入的检测效果:
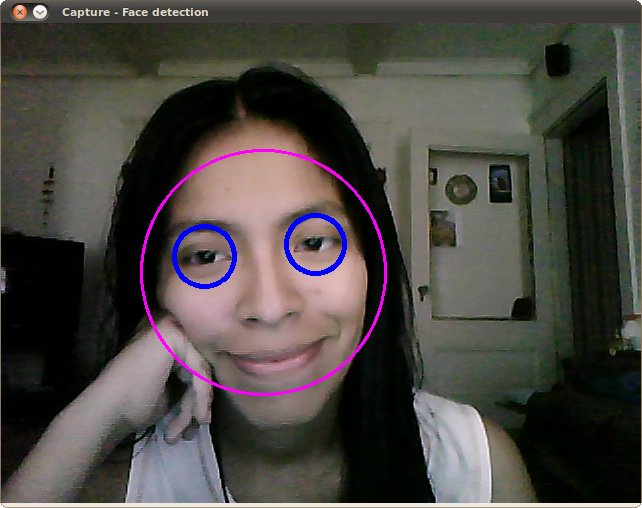
请确保程序能正确找到以下文件的路径:
haarcascade_frontalface_alt.xmlhaarcascade_eye_tree_eyeglasses.xml
这些文件位于opencv/data/haarcascades目录下
2、这是使用LBP训练文件lbpcascade_frontalface.xml进行人脸检测的效果(眼部检测仍沿用教程中的原文件):
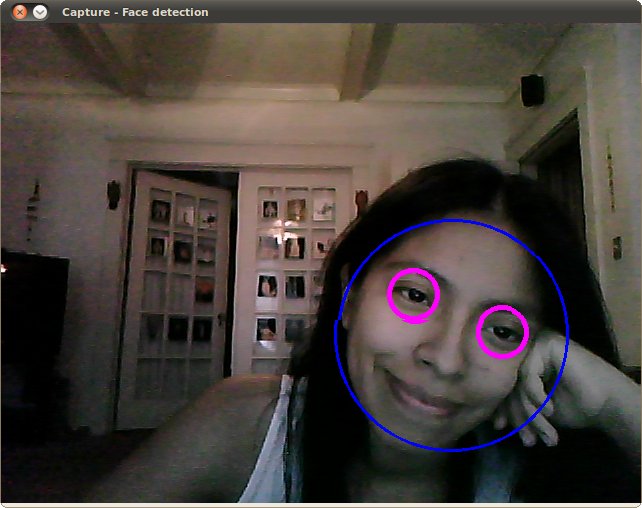
附加资源
1、Paul Viola 和 Michael J. Jones。《鲁棒的实时人脸检测》。国际计算机视觉杂志,57(2):137–154,2004年。[287]`
2、Rainer Lienhart 和 Jochen Maydt。《用于快速目标检测的扩展Haar-like特征集》。收录于《图像处理。2002年国际会议论文集》,第1卷,I–900页。IEEE,2002年。[168]`
3、视频讲座:人脸检测与追踪
4、关于人脸检测的趣味访谈,受访者:Adam Harvey
5、Adam Harvey在Vimeo上的作品:OpenCV人脸检测:可视化解析
生成于2025年4月30日星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 生成
级联分类器训练
https://docs.opencv.org/4.x/dc/d88/tutorial_traincascade.html
上一篇教程: 级联分类器
下一篇教程: 条形码识别
简介
使用弱分类器级联增强模型主要包含两个阶段:训练阶段和检测阶段。基于HAAR或LBP模型的检测阶段已在目标检测教程中详细说明。本文档将重点介绍如何训练自定义弱分类器级联模型的功能概述。本指南将逐步讲解所有不同阶段:收集训练数据、准备训练数据以及执行实际的模型训练。
为配合本教程,我们将使用以下官方OpenCV应用程序:opencv_createsamples、opencv_annotation、opencv_traincascade和opencv_visualisation。
注意:自OpenCV 4.0起,Createsamples和traincascade功能已被禁用。如需训练级联分类器,建议使用3.4分支中的这些应用程序。3.4版本与4.x版本间的模型格式保持一致。
重要说明
-
如果你遇到任何提到旧版 opencv_haartraining 工具的教程(该工具已弃用且仍使用 OpenCV1.x 接口),请忽略该教程并坚持使用 opencv_traincascade 工具。此工具是新版本,采用 C++ 编写,符合 OpenCV 2.x 和 OpenCV 3.x API。opencv_traincascade 同时支持类似 HAAR 的小波特征 [
286]和 LBP(局部二值模式)[165] 特征。与 HAAR 特征的浮点精度相比,LBP 特征提供整数精度,因此 LBP 的训练和检测速度比 HAAR 快数倍。关于 LBP 和 HAAR 的检测质量,主要取决于使用的训练数据和选择的训练参数。有可能训练出一个基于 LBP 的分类器,其质量几乎与基于 HAAR 的分类器相当,而训练时间仅需后者的几分之一。 -
OpenCV 2.x 和 OpenCV 3.x 中较新的级联分类器检测接口 (
cv::CascadeClassifier) 支持新旧模型格式。如果出于某些原因你仍需使用旧接口,opencv_traincascade 甚至可以以旧格式保存(导出)训练好的级联分类器。至少模型的训练可以在最稳定的接口中完成。 -
opencv_traincascade 应用程序可以使用 TBB 进行多线程处理。要在多核模式下使用此功能,必须启用 TBB 支持来构建 OpenCV。
训练数据准备
为了训练一个弱分类器的增强级联模型,我们需要准备两组样本数据:
- 正样本集(包含您想要检测的实际目标对象)
- 负样本集(包含所有不希望检测的内容)
负样本集需要手动准备,而正样本集可通过 opencv_createsamples 应用程序生成。
负样本
负样本取自任意图像,这些图像不包含你想要检测的目标物体。生成负样本的原始背景图像需要列在一个专门的负样本图像文件中,每行包含一个图像路径(可以是绝对路径或相对路径)。需要注意的是,负样本和样本图像也被称为背景样本或背景图像,本文档中这些术语可互换使用。
所描述的图像尺寸可以各不相同。但每张图像的尺寸应等于或大于预期的训练窗口尺寸(通常对应模型维度,即目标物体的平均大小),因为这些图像会被进一步分割成多个具有该训练窗口尺寸的图像样本。
以下是一个负样本描述文件的示例:
目录结构:
/imgimg1.jpgimg2.jpg
bg.txt
文件 bg.txt:
img/img1.jpg
img/img2.jpg
你的负窗口样本集将用于告诉机器学习步骤(这里指boosting算法),在寻找目标对象时应该忽略哪些内容。
正样本
正样本由 opencv_createsamples 应用程序创建。它们被用于 boosting 过程,以定义模型在寻找目标对象时应该关注的特征。该应用程序支持两种生成正样本数据集的方式:
- 可以从单个正样本图像生成大量正样本。
- 可以自行提供所有正样本,仅使用该工具进行裁剪、调整大小并将其转换为 OpenCV 所需的二进制格式。
虽然第一种方法对于固定对象(如非常刚性的标志)效果尚可,但对于不太刚性的对象,它往往会很快失效。在这种情况下,我们建议使用第二种方法。许多网络教程甚至指出,使用 opencv_createsamples 应用程序时,100 张真实对象图像生成的模型可能比 1000 张人工生成的正样本效果更好。但如果决定采用第一种方法,请注意以下几点:
- 请注意,在将样本提供给该应用程序之前,需要准备多个正样本,因为它仅应用透视变换。
- 如果需要构建一个鲁棒的模型,应确保样本覆盖对象类别中可能出现的各种变化。例如,在人脸检测的情况下,应考虑不同种族、年龄组、情绪以及可能的胡须样式。这一点在采用第二种方法时同样适用。
第一种方法以一个对象图像(例如公司标志)为输入,通过随机旋转对象、改变图像强度以及在任意背景上放置图像,从给定的对象图像生成大量正样本。随机性的程度和范围可以通过 opencv_createsamples 应用程序的命令行参数控制。
命令行参数:
-vec <vec_file_name>:包含训练正样本的输出文件名。-img <image_file_name>:源对象图像(例如公司标志)。-bg <background_file_name>:背景描述文件;包含用作对象随机变形版本背景的图像列表。-num <number_of_samples>:要生成的正样本数量。-bgcolor <background_color>:背景颜色(当前假设为灰度图像);背景颜色表示透明色。由于可能存在压缩伪影,可以通过-bgthresh指定颜色容差范围。所有在bgcolor-bgthresh和bgcolor+bgthresh范围内的像素均被视为透明。-bgthresh <background_color_threshold>-inv:如果指定,颜色将被反转。-randinv:如果指定,颜色将随机反转。-maxidev <max_intensity_deviation>:前景样本中像素的最大强度偏差。-maxxangle <max_x_rotation_angle>:绕 x 轴的最大旋转角度(以弧度为单位)。-maxyangle <max_y_rotation_angle>:绕 y 轴的最大旋转角度(以弧度为单位)。-maxzangle <max_z_rotation_angle>:绕 z 轴的最大旋转角度(以弧度为单位)。-show:有用的调试选项。如果指定,将显示每个样本。按 Esc 键将继续样本创建过程而不显示每个样本。-w <sample_width>:输出样本的宽度(以像素为单位)。-h <sample_height>:输出样本的高度(以像素为单位)。
当以这种方式运行 opencv_createsamples 时,创建样本对象实例的过程如下:给定的源图像会绕所有三个轴随机旋转,旋转角度受 -maxxangle、-maxyangle 和 -maxzangle 限制。然后,强度在 [bg_color-bg_color_threshold; bg_color+bg_color_threshold] 范围内的像素被视为透明。前景的强度会添加白噪声。如果指定了 -inv 参数,则前景像素强度会被反转。如果指定了 -randinv 参数,则算法会随机决定是否对该样本应用反转。最后,生成的图像会被放置在背景描述文件中的任意背景上,调整为由 -w 和 -h 指定的目标大小,并存储到由 -vec 命令行选项指定的 vec 文件中。
正样本也可以从一组预先标记的图像中获取,这是构建鲁棒对象模型时的理想方式。该集合由一个类似于背景描述文件的文本文件描述。文件的每一行对应一个图像,行的第一个元素是文件名,后跟对象标注的数量,然后是描述对象边界矩形坐标的数字(x、y、宽度、高度)。
描述文件示例:
目录结构:
/imgimg1.jpgimg2.jpg
info.dat
文件 info.dat:
img/img1.jpg 1 140 100 45 45
img/img2.jpg 2 100 200 50 50 50 30 25 25
图片 img1.jpg 包含单个物体实例,其边界矩形坐标为 (140, 100, 45, 45)。图片 img2.jpg 包含两个物体实例。
要从这类集合中创建正样本,应使用 -info 参数替代 -img:
-info <collection_file_name>: 标注图像集合的描述文件。
注意:此时诸如 -bg, -bgcolor, -bgthreshold, -inv, -randinv, -maxxangle, -maxyangle, -maxzangle 等参数将被忽略且不再使用。此情况下的样本创建流程如下:从给定图像中提取提供的边界框区域作为物体实例,随后将其缩放至目标样本尺寸(由 -w 和 -h 定义),并存储到 -vec 参数指定的输出 vec 文件中。不应用任何形变处理,因此仅受影响的参数为 -w、-h、-show 和 -num。
创建 -info 文件的手动过程也可通过 opencv_annotation 工具完成。该开源工具可直观地在任意图像中选取物体实例的感兴趣区域。下一小节将详细讨论如何使用此应用程序。
额外说明
- 可以使用 opencv_createsamples 工具来检查存储在任意给定正样本文件中的样本。为此只需指定
-vec、-w和-h参数即可。 - 这里提供了一个 vec 文件的示例
opencv/data/vec_files/trainingfaces_24-24.vec。该文件可用于训练窗口大小为-w 24 -h 24的人脸检测器。
使用 OpenCV 的集成标注工具
自 OpenCV 3.x 版本起,社区提供并维护了一款开源标注工具,用于生成 -info 文件。如果已构建 OpenCV 应用程序,可通过命令 opencv_annotation 调用该工具。
该工具使用起来非常简单,它接受几个必需参数和一些可选参数:
--annotations(必需):指定存储标注结果的 txt 文件路径,该文件后续会传递给-info参数 [示例 - /data/annotations.txt]--images(必需):包含待标注对象图片的文件夹路径 [示例 - /data/testimages/]--maxWindowHeight(可选):如果输入图像高度超过此处设定的分辨率,则通过--resizeFactor缩放图像以便于标注--resizeFactor(可选):与--maxWindowHeight参数配合使用时,指定图像缩放比例因子
注意:可选参数必须搭配使用。下方展示了一个典型的使用命令示例
opencv_annotation --annotations=/path/to/annotations/file.txt --images=/path/to/image/folder/
该命令将启动一个窗口,显示第一张图片和您的鼠标光标,用于进行标注操作。关于如何使用标注工具的视频可参考此处。基本操作是通过几个按键触发动作:首先用鼠标左键选择对象的第一个角点,持续绘制直到满意为止,当再次点击鼠标左键时停止绘制。每次选择后您有以下选项:
- 按下
c键:确认标注,标注线将变为绿色并确认已存储 - 按下
d键:从标注列表中删除最后一个标注(便于移除错误标注) - 按下
n键:继续处理下一张图片 - 按下
ESC键:退出标注软件
最终您将获得一个可用的标注文件,该文件可传递给opencv_createsamples的-info参数使用。
级联训练
下一步是基于预先准备好的正负样本数据集,对弱分类器的增强级联进行实际训练。
opencv_traincascade应用程序的命令行参数按用途分组如下:
-
通用参数:
-data <cascade_dir_name>:训练好的分类器存储路径。该目录需提前手动创建。-vec <vec_file_name>:包含正样本的vec文件(由opencv_createsamples工具生成)。-bg <background_file_name>:背景描述文件,包含负样本图像。-numPos <number_of_positive_samples>:每个分类器阶段训练使用的正样本数量。-numNeg <number_of_negative_samples>:每个分类器阶段训练使用的负样本数量。-numStages <number_of_stages>:需要训练的级联阶段数。-precalcValBufSize <precalculated_vals_buffer_size_in_Mb>:预计算特征值缓冲区大小(MB)。分配内存越大训练越快,但需注意-precalcValBufSize和-precalcIdxBufSize总和不应超过可用系统内存。-precalcIdxBufSize <precalculated_idxs_buffer_size_in_Mb>:预计算特征索引缓冲区大小(MB)。分配内存越大训练越快,但需注意-precalcValBufSize和-precalcIdxBufSize总和不应超过可用系统内存。-baseFormatSave:仅适用于Haar特征。若指定,级联将以旧格式保存。此参数仅为向后兼容而保留,使依赖旧接口的用户至少能通过新接口训练模型。-numThreads <max_number_of_threads>:训练时使用的最大线程数。实际线程数可能更低,取决于设备和编译选项。默认情况下,若OpenCV编译时支持TBB(此优化的必要条件),将选择最大可用线程数。-acceptanceRatioBreakValue <break_value>:用于控制模型学习精度和停止条件。建议训练不超过10e-5,防止模型在训练数据上过拟合。默认值-1表示禁用此功能。
-
级联参数:
-stageType <BOOST(default)>:阶段类型。目前仅支持增强分类器作为阶段类型。-featureType<{HAAR(default), LBP}>:特征类型:HAAR表示类Haar特征,LBP表示局部二值模式。-w <sampleWidth>:训练样本宽度(像素)。必须与创建训练样本时(opencv_createsamples工具)使用的值严格一致。-h <sampleHeight>:训练样本高度(像素)。必须与创建训练样本时(opencv_createsamples工具)使用的值严格一致。
-
增强分类器参数:
-bt <{DAB, RAB, LB, GAB(default)}>:增强分类器类型:DAB-离散AdaBoost,RAB-实数AdaBoost,LB-LogitBoost,GAB-温和AdaBoost。-minHitRate <min_hit_rate>:每个分类器阶段的最小期望命中率。总命中率可估算为(min_hit_rate^number_of_stages),参见[287]§4.1。-maxFalseAlarmRate <max_false_alarm_rate>:每个分类器阶段的最大允许误检率。总误检率可估算为(max_false_alarm_rate^number_of_stages),参见[287]§4.1。-weightTrimRate <weight_trim_rate>:指定是否使用权重修剪及其比率。推荐值为0.95。-maxDepth <max_depth_of_weak_tree>:弱树的最大深度。推荐值为1(即树桩结构)。-maxWeakCount <max_weak_tree_count>:每个级联阶段的弱树最大数量。增强分类器(阶段)将包含足够多的弱树(≤maxWeakCount)以满足给定的-maxFalseAlarmRate。
-
类Haar特征参数:
-mode <BASIC (default) | CORE | ALL>:选择训练使用的Haar特征集类型。BASIC仅使用直立特征,ALL使用包含直立和45度旋转特征的完整集合。详见[168]。
-
局部二值模式参数:无特定参数。
当opencv_traincascade应用程序完成工作后,训练好的级联将保存在-data文件夹的cascade.xml文件中。该文件夹中的其他文件是为训练中断情况创建的,训练完成后可删除。
训练完成后,即可测试您的级联分类器!
可视化级联分类器
有时可视化训练好的级联分类器会很有帮助,可以查看它选择了哪些特征以及各阶段的复杂度。为此,OpenCV 提供了一个 opencv_visualisation 应用程序。该应用程序包含以下命令:
--image(必选):对象模型的参考图像路径。这应该是一个标注图像,其尺寸 [-w,-h] 需与传递给opencv_createsamples和opencv_traincascade应用程序的参数一致。--model(必选):训练好的模型路径,该模型应位于opencv_traincascade应用程序-data参数指定的文件夹中。--data(可选):如果提供了数据文件夹(需事先手动创建),将存储阶段输出和特征视频。
下面是一个示例命令:
opencv_visualisation --image=/data/object.png --model=/data/model.xml --data=/data/result/
当前可视化工具的一些限制
-
仅支持使用opencv_traincascade工具训练的级联分类器模型,且决策树必须为桩决策树[默认设置]。
-
提供的图像必须是原始模型尺寸的样本窗口,需通过
--image参数传入。
以安吉丽娜·朱莉的特定窗口运行HAAR/LBP人脸模型的示例(该窗口与级联分类器文件采用相同预处理流程)–>24x24像素图像、灰度转换及直方图均衡化:
为每个阶段的可视化特征制作了视频:

每个阶段的特征被存储为图像以便后续验证:
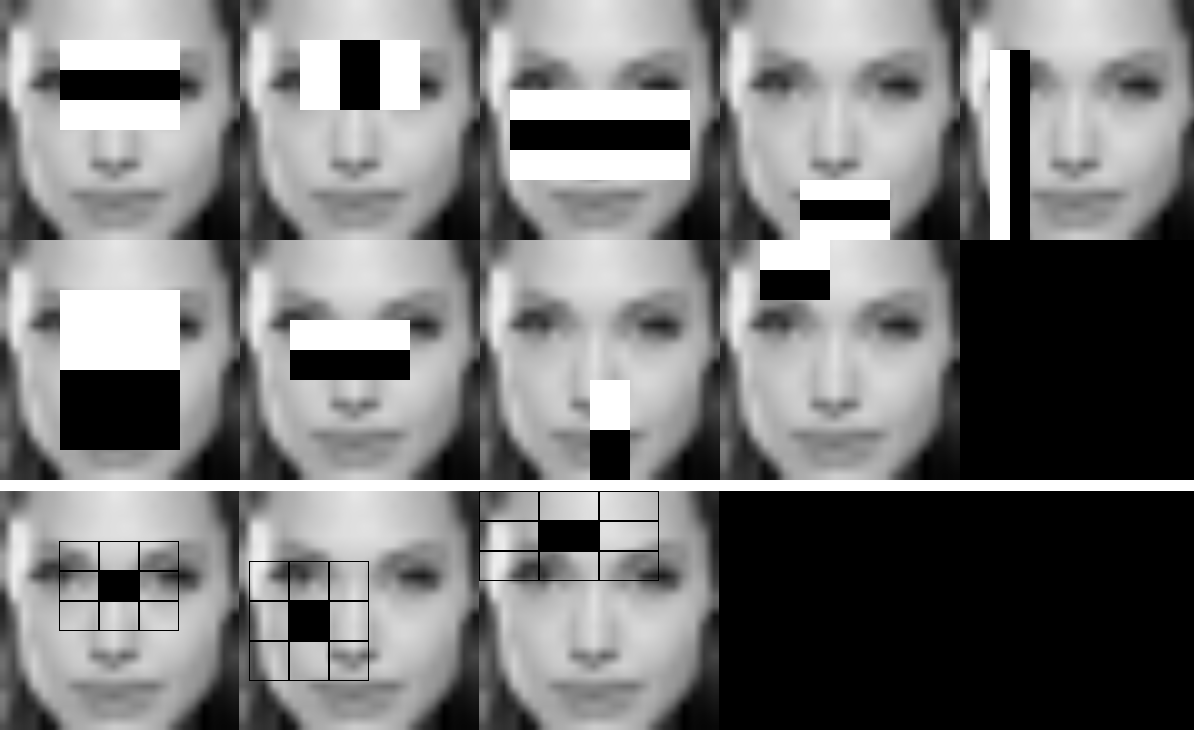
本作品由StevenPuttemans为OpenCV 3 Blueprints创建,经Packt Publishing同意整合至OpenCV。
由doxygen 1.12.0生成于2025年4月30日周三 23:08:42,适用于OpenCV
条形码识别
https://docs.opencv.org/4.x/d6/d25/tutorial_barcode_detect_and_decode.html
上一教程: 级联分类器训练
下一教程: 支持向量机简介
| 兼容性 | OpenCV >= 4.8 |
目标
在本章中,我们将熟悉 OpenCV 中可用的条形码检测和解码方法。
基础概念
条形码是现实生活中识别商品的主要技术手段。常见的条形码由反射率差异显著的黑白条平行排列组成。条形码识别的原理是:通过水平方向扫描条形码,获取由不同宽度和颜色的条组成的二进制码串,即条形码的编码信息。通过与多种条形码编码规则匹配,可以解码出条形码的内容。目前我们支持 EAN-8、EAN-13、UPC-A 和 UPC-E 标准。
参考链接:https://en.wikipedia.org/wiki/Universal_Product_Code 和 https://en.wikipedia.org/wiki/International_Article_Number
相关论文:[304]](https://docs.opencv.org/4.x/d0/de3/citelist.html#CITEREF_xiangmin2015research) 、[[144] 、[21]`
代码示例
主类
本文介绍了多种用于条形码识别的算法。
在编写代码时,我们首先需要创建一个 cv::barcode::BarcodeDetector 对象。该对象主要包含三个成员函数,我们将在下文进行详细介绍。
初始化
用户可选择性地构建带有超分辨率模型的条码检测器,该模型需从 https://github.com/WeChatCV/opencv_3rdparty/tree/wechat_qrcode 下载(sr.caffemodel、sr.prototxt)。
try{app.bardet = makePtr<barcode::BarcodeDetector>(sr_prototxt, sr_model);}catch (const std::exception& e){cout <<"\n---------------------------------------------------------------\n""Failed to initialize super resolution.\n""Please, download 'sr.*' from\n""https://github.com/WeChatCV/opencv_3rdparty/tree/wechat_qrcode\n""and put them into the current directory.\n""Or you can leave sr_prototxt and sr_model unspecified.\n""---------------------------------------------------------------\n";cout << e.what() << endl;return -1;}
我们需要创建变量来存储输出结果。
vector<Point> corners;vector<string> decode_info;vector<string> decode_type;
检测
cv::barcode::BarcodeDetector::detect方法采用基于方向一致性的算法。首先,计算每个像素的平均平方梯度[21]`](https://docs.opencv.org/4.x/d0/de3/citelist.html#CITEREF_bazen2002systematic)。接着,将图像划分为方形区块,分别计算各区块的梯度方向一致性和平均梯度方向。然后,连接所有具有高梯度方向一致性且梯度方向相似的区块。在此阶段,采用多尺度区块来捕捉不同尺寸条形码的梯度分布,并应用非极大值抑制来过滤重复的候选区域。最后,使用[`cv::minAreaRect`框定感兴趣区域,并输出矩形的角点坐标。
在输入图像中检测编码,并输出检测到的矩形角点:
bardet->detectMulti(frame, corners);
解码
cv::barcode::BarcodeDetector::decode方法首先会对图像进行超分辨率放大(可选操作,当图像尺寸小于阈值时),然后锐化图像并通过OTSU或局部二值化处理进行二值化。接着,该方法通过匹配指定条形码模式的相似度来读取条形码内容。
检测与解码
cv::barcode::BarcodeDetector::detectAndDecode 将 detect 和 decode 功能整合在单次调用中。以下简单示例展示了如何使用该函数:
bardet->detectAndDecodeWithType(frame, decode_info, decode_type, corners);
可视化结果:
for (size_t i = 0; i < corners.size(); i += 4){const size_t idx = i / 4;const bool isDecodable = idx < decode_info.size()&& idx < decode_type.size()&& !decode_type[idx].empty();const Scalar lineColor = isDecodable ? greenColor : redColor;// draw barcode rectanglevector<Point> contour(corners.begin() + i, corners.begin() + i + 4);const vector< vector<Point> > contours {contour};drawContours(frame, contours, 0, lineColor, 1);// draw verticesfor (size_t j = 0; j < 4; j++)circle(frame, contour[j], 2, randColor(), -1);// write decoded textif (isDecodable){ostringstream buf;buf << "[" << decode_type[idx] << "] " << decode_info[idx];putText(frame, buf.str(), contour[1], FONT_HERSHEY_COMPLEX, 0.8, yellowColor, 1);}}
结果
原始图像:

检测后:

由 doxygen 1.12.0 生成于 2025年4月30日 星期三 23:08:42 用于 OpenCV
支持向量机简介
https://docs.opencv.org/4.x/d1/d73/tutorial_introduction_to_svm.html
上一教程: 条形码识别
下一教程: 非线性可分数据的支持向量机
| 原作者 | Fernando Iglesias García |
| 兼容性 | OpenCV >= 3.0 |
目标
在本教程中,您将学习如何:
- 使用OpenCV函数
cv::ml::SVM::train基于支持向量机(SVM)构建分类器 - 使用
cv::ml::SVM::predict函数测试分类器性能
什么是支持向量机?
支持向量机(SVM)是一种通过分离超平面定义的判别式分类器。简而言之,给定带有标签的训练数据(监督学习),该算法会输出一个最优超平面,用于对新样本进行分类。
这个超平面在什么意义下是最优的呢?让我们考虑以下简单问题:
对于线性可分的二维点集,这些点属于两个类别之一,找到一条分隔直线。

注意:本例中我们处理的是笛卡尔平面中的直线和点,而非高维空间中的超平面和向量。这是问题的简化形式。需要理解的是,这样做仅因为从易于想象的例子出发更符合直觉。但相同的概念适用于样本分类空间维度高于二维的任务。
从上图可见,存在多条直线都能解决问题。其中是否有某条直线比其他更好?我们可以直观地定义一个标准来评估这些直线的优劣:若某条直线过于接近某些点,则其表现不佳,因为它会对噪声敏感且泛化能力差。 因此,我们的目标是找到一条尽可能远离所有点的直线。
于是,SVM算法的核心在于寻找那个使训练样本最小距离最大化的超平面。这个距离的两倍在SVM理论中有一个重要名称——间隔。因此,最优分隔超平面就是能够最大化训练数据间隔的那个。

最优超平面是如何计算的?
让我们先介绍用于形式化定义超平面的符号表示:
\[f(x) = \beta_{0} + \beta^{T} x,\]
其中 \(\beta\) 称为权重向量,\(\beta_{0}\) 称为偏置项。
注:关于超平面更深入的描述,可参考 T. Hastie、R. Tibshirani 和 J. H. Friedman 所著《统计学习基础》第 4.5 节(分离超平面)([274]`)。
最优超平面可以通过缩放 \(\beta\) 和 \(\beta_{0}\) 以无限多种方式表示。按照惯例,我们选择以下特定表示形式:
\[|\beta_{0} + \beta^{T} x| = 1\]
其中 \(x\) 代表距离超平面最近的训练样本。通常,这些最接近超平面的训练样本被称为支持向量。这种表示形式称为规范超平面。
根据几何学结论,点 \(x\) 到超平面 \((\beta, \beta_{0})\) 的距离公式为:
\[\mathrm{distance} = \frac{|\beta_{0} + \beta^{T} x|}{||\beta||}.\]
特别地,对于规范超平面,分子等于 1,因此支持向量的距离为:
\[\mathrm{distance}{\text{支持向量}} = \frac{|\beta{0} + \beta^{T} x|}{||\beta||} = \frac{1}{||\beta||}.\]
前文提到的间隔(此处记作 \(M\))是最接近样本距离的两倍:
\[M = \frac{2}{||\beta||}\]
最终,最大化 \(M\) 的问题等价于在特定约束条件下最小化函数 \(L(\beta)\)。这些约束条件要求超平面必须正确分类所有训练样本 \(x_{i}\)。形式化表示为:
\[\min_{\beta, \beta_{0}} L(\beta) = \frac{1}{2}||\beta||^{2} \text{ 约束条件为 } y_{i}(\beta^{T} x_{i} + \beta_{0}) \geq 1 \text{ } \forall i,\]
其中 \(y_{i}\) 表示各训练样本的标签。
这是一个拉格朗日优化问题,可通过拉格朗日乘数法求解,从而得到最优超平面的权重向量 \(\beta\) 和偏置项 \(\beta_{0}\)。
源代码
可下载代码:C++ | Java | Python
代码概览:
import cv2 as cv
import numpy as np# Set up training datalabels = np.array([1, -1, -1, -1])
trainingData = np.matrix([[501, 10], [255, 10], [501, 255], [10, 501]], dtype=np.float32)# Train the SVMsvm = cv.ml.SVM_create()
svm.setType(cv.ml.SVM_C_SVC)
svm.setKernel(cv.ml.SVM_LINEAR)
svm.setTermCriteria((cv.TERM_CRITERIA_MAX_ITER, 100, 1e-6))svm.train(trainingData, cv.ml.ROW_SAMPLE, labels)# Data for visual representation
width = 512
height = 512
image = np.zeros((height, width, 3), dtype=np.uint8)# Show the decision regions given by the SVMgreen = (0,255,0)
blue = (255,0,0)
for i in range(image.shape[0]):for j in range(image.shape[1]):sampleMat = np.matrix([[j,i]], dtype=np.float32)response = svm.predict(sampleMat)[1]if response == 1:image[i,j] = greenelif response == -1:image[i,j] = blue# Show the training datathickness = -1
cv.circle(image, (501, 10), 5, ( 0, 0, 0), thickness)
cv.circle(image, (255, 10), 5, (255, 255, 255), thickness)
cv.circle(image, (501, 255), 5, (255, 255, 255), thickness)
cv.circle(image, ( 10, 501), 5, (255, 255, 255), thickness)# Show support vectorsthickness = 2
sv = svm.getUncompressedSupportVectors()for i in range(sv.shape[0]):cv.circle(image, (int(sv[i,0]), int(sv[i,1])), 6, (128, 128, 128), thickness)cv.imwrite('result.png', image) # save the imagecv.imshow('SVM Simple Example', image) # show it to the user
cv.waitKey()
说明
设置训练数据
本练习的训练数据由一组标记的二维点组成,这些点属于两个不同类别之一;其中一个类别包含一个点,另一个类别包含三个点。
labels = np.array([1, -1, -1, -1])
trainingData = np.matrix([[501, 10], [255, 10], [501, 255], [10, 501]], dtype=np.float32)
后续将使用的 cv::ml::SVM::train 函数要求训练数据以浮点型 cv::Mat 对象的形式存储。因此,我们需要根据上面定义的数组来创建这些对象:
labels = np.array([1, -1, -1, -1])
trainingData = np.matrix([[501, 10], [255, 10], [501, 255], [10, 501]], dtype=np.float32)
设置SVM参数
在本教程中,我们介绍了最简单情况下SVM的理论,即训练样本被分为线性可分的两个类别。然而,SVM可以应用于各种不同的问题(例如非线性可分数据的问题,使用核函数提升样本维度的SVM等)。因此,在训练SVM之前,我们需要定义一些参数。这些参数存储在类cv::ml::SVM的对象中。
svm = cv.ml.SVM_create()
svm.setType(cv.ml.SVM_C_SVC)
svm.setKernel(cv.ml.SVM_LINEAR)
svm.setTermCriteria((cv.TERM_CRITERIA_MAX_ITER, 100, 1e-6))
以下是翻译后的中文内容:
-
SVM类型选择。这里我们选用C_SVC`类型,该类型适用于多类分类(n≥2)。其重要特性是能处理类别不完全分离的情况(即训练数据非线性可分)。虽然当前数据是线性可分的,这个特性并不关键,但我们仍选择该类型,因为它是实际应用中最常用的SVM类型。
-
核函数类型。由于当前训练数据特性,我们尚未讨论核函数。不过简要说明其核心思想:核函数通过对训练数据进行映射,增强其与线性可分数据的相似性。这种映射通过提升数据维度实现,并借助核函数高效完成。此处我们选择LINEAR`](https://docs.opencv.org/4.x/d1/d2d/classcv_1_1ml_1_1SVM.html#aad7f1aaccced3c33bb256640910a0e56ab92a19ab0c193735c3fd71f938dd87e7)类型,表示不进行任何映射。该参数通过[`cv::ml::SVM::setKernel`方法设置。
-
算法终止条件。SVM训练过程通过迭代方式求解约束二次优化问题实现。这里我们指定最大迭代次数和容错阈值,允许算法在未计算出最优超平面时提前终止。该参数通过
cv::TermCriteria结构体定义。 -
训练SVM模型。调用
cv::ml::SVM::train方法构建SVM模型。
svm.train(trainingData, cv.ml.ROW_SAMPLE, labels)
SVM分类的区域
方法 cv::ml::SVM::predict 用于通过训练好的SVM对输入样本进行分类。在本例中,我们使用该方法根据SVM的预测结果对空间进行着色。换句话说,我们将图像遍历,将其像素解释为笛卡尔平面上的点。每个点根据SVM预测的类别进行着色:如果属于标签为1的类别则显示为绿色,如果属于标签为-1的类别则显示为蓝色。
green = (0,255,0)
blue = (255,0,0)
for i in range(image.shape[0]):for j in range(image.shape[1]):sampleMat = np.matrix([[j,i]], dtype=np.float32)response = svm.predict(sampleMat)[1]if response == 1:image[i,j] = greenelif response == -1:image[i,j] = blue
支持向量
这里我们采用几种方法来获取支持向量的相关信息。方法 cv::ml::SVM::getSupportVectors 可获取所有的支持向量。我们运用该方法来识别作为支持向量的训练样本,并将其突出显示。
thickness = 2
sv = svm.getUncompressedSupportVectors()for i in range(sv.shape[0]):cv.circle(image, (int(sv[i,0]), int(sv[i,1])), 6, (128, 128, 128), thickness)
实验结果
- 代码打开一张图片,展示两个类别的训练样本。其中一个类别的样本点用白色圆圈表示,另一个类别则用黑色圆圈表示。
- 训练支持向量机(SVM)模型后,对图像所有像素进行分类。结果显示图像被划分为蓝色区域和绿色区域,两个区域之间的分界线即为最优分隔超平面。
- 最后通过在训练样本周围显示灰色圆环来展示支持向量。

本文档由 doxygen 1.12.0 生成于 2025年4月30日 星期三 23:08:42,针对 OpenCV 库
支持向量机处理非线性可分数据
https://docs.opencv.org/4.x/d0/dcc/tutorial_non_linear_svms.html
上一教程: 支持向量机简介
下一教程: 主成分分析(PCA)简介
| 原作者 | Fernando Iglesias García |
| 兼容性 | OpenCV >= 3.0 |
目标
在本教程中,您将学习:
- 当训练数据无法线性分离时,如何为支持向量机(SVM)定义优化问题。
- 如何配置参数以使您的SVM适应此类问题。
动机
为什么扩展SVM优化问题以处理非线性可分的训练数据是有意义的?在计算机视觉中使用SVM的大多数应用场景中,我们需要的工具比简单的线性分类器更强大。这是因为在这些任务中,训练数据很少能通过超平面实现完全分离。
以人脸检测任务为例。这类任务的训练数据由两部分组成:包含人脸的图像集和不含人脸的图像集(即除人脸外的所有其他事物)。这类训练数据过于复杂,我们很难找到一种样本表示方式(即特征向量),使得所有人脸样本能与非人脸样本实现线性可分。
优化问题的扩展
使用支持向量机(SVM)时,我们会得到一个分隔超平面。由于训练数据现在是非线性可分的,我们必须承认找到的超平面会错误分类部分样本。这种误分类成为优化问题中必须考虑的新变量。新模型需要同时满足两个要求:既要找到能提供最大边界的超平面,又要通过限制过多分类错误来正确泛化训练数据。
我们从寻找最大化边界的超平面优化问题出发(这在之前的教程《支持向量机简介》中已说明):
\[\min_{\beta, \beta_{0}} L(\beta) = \frac{1}{2}||\beta||^{2} \text{ 约束条件 } y_{i}(\beta^{T} x_{i} + \beta_{0}) \geq 1 \text{ } \forall i\]
有多种方法可以修改此模型以考虑误分类错误。例如,可以尝试最小化相同量加上一个常数乘以训练数据中的误分类错误数,即:
\[\min ||\beta||^{2} + C \text{(误分类错误数)}\]
然而,这并不是一个很好的解决方案,原因之一是我们没有区分那些距离其正确决策区域较近的误分类样本和那些距离较远的样本。因此,更好的解决方案应考虑误分类样本到其正确决策区域的距离,即:
\[\min ||\beta||^{2} + C \text{(误分类样本到其正确区域的距离)}\]
对于训练数据中的每个样本,定义一个新参数\(\xi_{i}\)。每个参数表示对应训练样本到其正确决策区域的距离。下图展示了两类非线性可分的训练数据、一个分隔超平面以及误分类样本到其正确区域的距离。
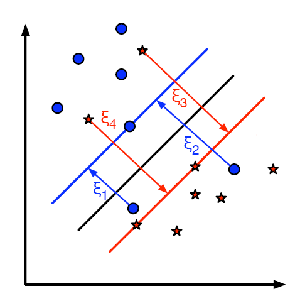
注意:图中仅显示了误分类样本的距离。其余样本的距离为零,因为它们已位于正确的决策区域内。图中出现的红线和蓝线是每个决策区域的边界。非常重要的是要认识到,每个\(\xi_{i}\)表示一个误分类训练样本到其适当区域边界的距离。
最终,优化问题的新表述为:
\[\min_{\beta, \beta_{0}} L(\beta) = ||\beta||^{2} + C \sum_{i} {\xi_{i}} \text{ 约束条件 } y_{i}(\beta^{T} x_{i} + \beta_{0}) \geq 1 - \xi_{i} \text{ 且 } \xi_{i} \geq 0 \text{ } \forall i\]
如何选择参数C?显然,这个问题的答案取决于训练数据的分布。虽然没有通用的答案,但以下规则很有帮助:
- 较大的C值会给出较少误分类错误但边界较小的解。这种情况下,误分类错误的代价较高。由于优化的目标是最小化参数,因此允许的误分类错误较少。
- 较小的C值会给出边界较大但分类错误较多的解。此时,最小化过程不太关注求和项,而更侧重于寻找具有较大边界的超平面。
源代码
你可以在OpenCV源码库的samples/cpp/tutorial_code/ml/non_linear_svms目录下找到源代码,或者从这里下载。
可下载代码: C++ | Java | Python
代码概览:
from __future__ import print_function
import cv2 as cv
import numpy as np
import random as rngNTRAINING_SAMPLES = 100 # Number of training samples per class
FRAC_LINEAR_SEP = 0.9 # Fraction of samples which compose the linear separable part# Data for visual representation
WIDTH = 512
HEIGHT = 512
I = np.zeros((HEIGHT, WIDTH, 3), dtype=np.uint8)# --------------------- 1. Set up training data randomly ---------------------------------------
trainData = np.empty((2*NTRAINING_SAMPLES, 2), dtype=np.float32)
labels = np.empty((2*NTRAINING_SAMPLES, 1), dtype=np.int32)rng.seed(100) # Random value generation class# Set up the linearly separable part of the training data
nLinearSamples = int(FRAC_LINEAR_SEP * NTRAINING_SAMPLES)trainClass = trainData[0:nLinearSamples,:]
# The x coordinate of the points is in [0, 0.4)
c = trainClass[:,0:1]
c[:] = np.random.uniform(0.0, 0.4 * WIDTH, c.shape)
# The y coordinate of the points is in [0, 1)
c = trainClass[:,1:2]
c[:] = np.random.uniform(0.0, HEIGHT, c.shape)# Generate random points for the class 2
trainClass = trainData[2*NTRAINING_SAMPLES-nLinearSamples:2*NTRAINING_SAMPLES,:]
# The x coordinate of the points is in [0.6, 1]
c = trainClass[:,0:1]
c[:] = np.random.uniform(0.6*WIDTH, WIDTH, c.shape)
# The y coordinate of the points is in [0, 1)
c = trainClass[:,1:2]
c[:] = np.random.uniform(0.0, HEIGHT, c.shape)#------------------ Set up the non-linearly separable part of the training data ---------------trainClass = trainData[nLinearSamples:2*NTRAINING_SAMPLES-nLinearSamples,:]
# The x coordinate of the points is in [0.4, 0.6)
c = trainClass[:,0:1]
c[:] = np.random.uniform(0.4*WIDTH, 0.6*WIDTH, c.shape)
# The y coordinate of the points is in [0, 1)
c = trainClass[:,1:2]
c[:] = np.random.uniform(0.0, HEIGHT, c.shape)#------------------------- Set up the labels for the classes ---------------------------------
labels[0:NTRAINING_SAMPLES,:] = 1 # Class 1
labels[NTRAINING_SAMPLES:2*NTRAINING_SAMPLES,:] = 2 # Class 2#------------------------ 2. Set up the support vector machines parameters --------------------
print('Starting training process')svm = cv.ml.SVM_create()
svm.setType(cv.ml.SVM_C_SVC)
svm.setC(0.1)
svm.setKernel(cv.ml.SVM_LINEAR)
svm.setTermCriteria((cv.TERM_CRITERIA_MAX_ITER, int(1e7), 1e-6))#------------------------ 3. Train the svm ----------------------------------------------------svm.train(trainData, cv.ml.ROW_SAMPLE, labels)print('Finished training process')#------------------------ 4. Show the decision regions ----------------------------------------green = (0,100,0)
blue = (100,0,0)
for i in range(I.shape[0]):for j in range(I.shape[1]):sampleMat = np.matrix([[j,i]], dtype=np.float32)response = svm.predict(sampleMat)[1]if response == 1:I[i,j] = greenelif response == 2:I[i,j] = blue#----------------------- 5. Show the training data --------------------------------------------thick = -1
# Class 1
for i in range(NTRAINING_SAMPLES):px = trainData[i,0]py = trainData[i,1]cv.circle(I, (int(px), int(py)), 3, (0, 255, 0), thick)# Class 2
for i in range(NTRAINING_SAMPLES, 2*NTRAINING_SAMPLES):px = trainData[i,0]py = trainData[i,1]cv.circle(I, (int(px), int(py)), 3, (255, 0, 0), thick)#------------------------- 6. Show support vectors --------------------------------------------thick = 2
sv = svm.getUncompressedSupportVectors()for i in range(sv.shape[0]):cv.circle(I, (int(sv[i,0]), int(sv[i,1])), 6, (128, 128, 128), thick)cv.imwrite('result.png', I) # save the Image
cv.imshow('SVM for Non-Linear Training Data', I) # show it to the user
cv.waitKey()
说明
设置训练数据
本练习的训练数据由一组标记的二维点组成,这些点属于两个不同类别之一。为了使练习更具吸引力,训练数据是使用均匀概率密度函数(PDF)随机生成的。
我们将训练数据的生成分为两个主要部分。
在第一部分中,我们为两个类别生成线性可分的数据。
trainClass = trainData[0:nLinearSamples,:]
# The x coordinate of the points is in [0, 0.4)
c = trainClass[:,0:1]
c[:] = np.random.uniform(0.0, 0.4 * WIDTH, c.shape)
# The y coordinate of the points is in [0, 1)
c = trainClass[:,1:2]
c[:] = np.random.uniform(0.0, HEIGHT, c.shape)# Generate random points for the class 2
trainClass = trainData[2*NTRAINING_SAMPLES-nLinearSamples:2*NTRAINING_SAMPLES,:]
# The x coordinate of the points is in [0.6, 1]
c = trainClass[:,0:1]
c[:] = np.random.uniform(0.6*WIDTH, WIDTH, c.shape)
# The y coordinate of the points is in [0, 1)
c = trainClass[:,1:2]
c[:] = np.random.uniform(0.0, HEIGHT, c.shape)
设置支持向量机参数
注意:在前一篇教程支持向量机简介中,已经对cv::ml::SVM类的属性进行了说明。在训练SVM之前,我们需要先配置这些参数。
svm = cv.ml.SVM_create()
svm.setType(cv.ml.SVM_C_SVC)
svm.setC(0.1)
svm.setKernel(cv.ml.SVM_LINEAR)
svm.setTermCriteria((cv.TERM_CRITERIA_MAX_ITER, int(1e7), 1e-6))
我们在此处的配置与参考教程(支持向量机入门)仅存在两点差异:
- C参数。这里选择较小的参数值以避免在优化过程中对分类错误施加过重惩罚。这种做法的初衷是为了获得更接近直觉预期的解。但建议通过调整该参数来深入理解问题本质。
注意:当前类间重叠区域中的样本点极少。通过减小FRAC_LINEAR_SEP值可以增加点密度,从而深入探究C参数的影响效果。
-
算法终止条件。为正确解决非线性可分训练数据问题,必须大幅增加最大迭代次数。具体而言,我们将该值提高了五个数量级。
-
训练SVM模型
调用方法cv::ml::SVM::train构建SVM模型。请注意训练过程可能耗时较长,运行程序时请保持耐心。
Python
svm.train(trainData, cv.ml.ROW_SAMPLE, labels)
显示决策区域
方法 cv::ml::SVM::predict 用于通过训练好的 SVM 对输入样本进行分类。在本示例中,我们利用该方法根据 SVM 的预测结果对空间进行着色。换句话说,程序会遍历图像,将其像素解释为笛卡尔平面上的点。每个点根据 SVM 预测的类别进行着色:若属于标签为 1 的类别则显示深绿色,若属于标签为 2 的类别则显示深蓝色。
green = (0,100,0)
blue = (100,0,0)
for i in range(I.shape[0]):for j in range(I.shape[1]):sampleMat = np.matrix([[j,i]], dtype=np.float32)response = svm.predict(sampleMat)[1]if response == 1:I[i,j] = greenelif response == 2:I[i,j] = blue
方法 cv::circle 用于显示构成训练数据的样本。标记为类别1的样本显示为浅绿色,标记为类别2的样本显示为浅蓝色。
thick = -1
# Class 1
for i in range(NTRAINING_SAMPLES):px = trainData[i,0]py = trainData[i,1]cv.circle(I, (int(px), int(py)), 3, (0, 255, 0), thick)# Class 2
for i in range(NTRAINING_SAMPLES, 2*NTRAINING_SAMPLES):px = trainData[i,0]py = trainData[i,1]cv.circle(I, (int(px), int(py)), 3, (255, 0, 0), thick)
支持向量
这里我们采用几种方法来获取有关支持向量的信息。方法 cv::ml::SVM::getSupportVectors 可获取所有支持向量。我们已使用该方法找出作为支持向量的训练样本,并将其突出显示。
thick = 2
sv = svm.getUncompressedSupportVectors()for i in range(sv.shape[0]):cv.circle(I, (int(sv[i,0]), int(sv[i,1])), 6, (128, 128, 128), thick)
结果
- 代码打开一张图片并展示两个类别的训练样本。其中一个类别的点用浅绿色表示,另一个类别则用浅蓝色表示。
- 训练支持向量机(SVM)并用它对图像所有像素进行分类。这导致图像被划分为蓝色区域和绿色区域。两个区域之间的边界就是分离超平面。由于训练数据是非线性可分的,可以看到两个类别都有部分样本被误分类:一些绿点位于蓝色区域,而一些蓝点位于绿色区域。
- 最后通过在训练样本周围显示灰色圆环来展示支持向量。

您可以在YouTube上观看此程序的运行实例:https://www.youtube.com/watch?v=vFv2yPcSo-Q。
主成分分析(PCA)简介
https://docs.opencv.org/4.x/d1/dee/tutorial_introduction_to_pca.html
上一教程: 非线性可分数据的支持向量机
| 原作者 | Theodore Tsesmelis |
| 兼容性 | OpenCV >= 3.0 |
目标
在本教程中,您将学习如何:
- 使用 OpenCV 类
cv::PCA计算物体的方向。
什么是PCA?
主成分分析(PCA)是一种统计方法,用于提取数据集中最重要的特征。

假设你有一组如上图所示的二维数据点,每个维度对应你感兴趣的特征。乍看之下,这些点似乎是随机分布的。但仔细观察会发现,存在一个难以忽视的线性模式(如蓝线所示)。PCA的核心在于降维——即减少数据集特征数量的过程。例如在上例中,我们可以将这些点近似为一条直线,从而将数据维度从2D降至1D。
此外,你会注意到这些点沿蓝线方向的变异程度,远大于沿特征1轴或特征2轴的变异。这意味着,相比仅知道点在特征1轴或特征2轴上的位置,了解点沿蓝线的位置能提供更多信息。
因此,PCA能帮助我们找到数据变异最大的方向。实际上,对图中点集运行PCA会得到两个称为特征向量的结果向量,它们就是数据集的主成分。

每个特征向量的大小由其对应的特征值编码,表示数据沿该主成分的变异程度。特征向量的起点是数据集中所有点的中心点。将PCA应用于N维数据集会产生:N个N维特征向量、N个特征值和1个N维中心点。理论介绍到此为止,下面我们来看看如何用代码实现这些概念。
如何计算特征向量和特征值?
目标是将维度为p的给定数据集X转换为维度更小(L)的替代数据集Y。等价地说,我们需要找到矩阵Y,其中Y是矩阵X的Karhunen–Loève变换(KLT):
\[ \mathbf{Y} = \mathbb{K} \mathbb{L} \mathbb{T} \{\mathbf{X}\} \]
组织数据集
假设你有一组包含p个变量的观测数据,希望将数据降维,使得每个观测值仅用L个变量描述(L < p)。进一步假设数据由n个数据向量\( x_1…x_n \)组成,每个\( x_i \)表示p个变量的单次分组观测。
- 将\( x_1…x_n \)写作行向量,每个行向量包含p列
- 将这些行向量组合成维度为\( n\times p \)的矩阵X
计算经验均值
- 对每个维度\( j = 1, …, p \)计算经验均值
- 将计算结果存入维度为\( p\times 1 \)的经验均值向量u
\[ \mathbf{u[j]} = \frac{1}{n}\sum_{i=1}^{n}\mathbf{X[i,j]} \]
计算均值偏差
均值减法是寻找主成分基的关键步骤,该基能最小化数据逼近的均方误差。因此我们按以下方式中心化数据:
- 从数据矩阵X的每一行减去经验均值向量u
- 将均值中心化后的数据存储在\( n\times p \)矩阵B中
\[ \mathbf{B} = \mathbf{X} - \mathbf{h}\mathbf{u^{T}} \]
其中h是\( n\times 1 \)的全1列向量:
\[ h[i] = 1, i = 1, …, n \]
求协方差矩阵
- 通过矩阵B与其自身的外积,计算\( p\times p \)经验协方差矩阵C:
\[ \mathbf{C} = \frac{1}{n-1} \mathbf{B^{*}} \cdot \mathbf{B} \]
其中*表示共轭转置算子。注意如果B完全由实数组成(多数应用场景如此),"共轭转置"等同于常规转置。
求协方差矩阵的特征向量和特征值
- 计算对角化协方差矩阵C的特征向量矩阵V:
\[ \mathbf{V^{-1}} \mathbf{C} \mathbf{V} = \mathbf{D} \]
其中D是C的特征值对角矩阵
- 矩阵D将呈现\( p \times p \)对角矩阵形式:
\[ D[k,l] = \left\{\begin{matrix} \lambda_k, k = l \\ 0, k \neq l \end{matrix}\right. \]
这里\( \lambda_j \)是协方差矩阵C的第j个特征值
- 同样维度为p x p的矩阵V包含p个列向量,每个长度为p,代表协方差矩阵C的p个特征向量
- 特征值和特征向量按顺序配对,第j个特征值对应第j个特征向量
注:参考文献[1]、[2],特别感谢Svetlin Penkov的原始教程。
源代码
可下载代码: C++ | Java | Python
from __future__ import print_function
from __future__ import division
import cv2 as cv
import numpy as np
import argparse
from math import atan2, cos, sin, sqrt, pidef drawAxis(img, p_, q_, colour, scale):p = list(p_)q = list(q_)angle = atan2(p[1] - q[1], p[0] - q[0]) # angle in radianshypotenuse = sqrt((p[1] - q[1]) * (p[1] - q[1]) + (p[0] - q[0]) * (p[0] - q[0]))# Here we lengthen the arrow by a factor of scaleq[0] = p[0] - scale * hypotenuse * cos(angle)q[1] = p[1] - scale * hypotenuse * sin(angle)cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), colour, 1, cv.LINE_AA)# create the arrow hooksp[0] = q[0] + 9 * cos(angle + pi / 4)p[1] = q[1] + 9 * sin(angle + pi / 4)cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), colour, 1, cv.LINE_AA)p[0] = q[0] + 9 * cos(angle - pi / 4)p[1] = q[1] + 9 * sin(angle - pi / 4)cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), colour, 1, cv.LINE_AA)def getOrientation(pts, img):sz = len(pts)data_pts = np.empty((sz, 2), dtype=np.float64)for i in range(data_pts.shape[0]):data_pts[i,0] = pts[i,0,0]data_pts[i,1] = pts[i,0,1]# Perform PCA analysismean = np.empty((0))mean, eigenvectors, eigenvalues = cv.PCACompute2(data_pts, mean)# Store the center of the objectcntr = (int(mean[0,0]), int(mean[0,1]))cv.circle(img, cntr, 3, (255, 0, 255), 2)p1 = (cntr[0] + 0.02 * eigenvectors[0,0] * eigenvalues[0,0], cntr[1] + 0.02 * eigenvectors[0,1] * eigenvalues[0,0])p2 = (cntr[0] - 0.02 * eigenvectors[1,0] * eigenvalues[1,0], cntr[1] - 0.02 * eigenvectors[1,1] * eigenvalues[1,0])drawAxis(img, cntr, p1, (0, 255, 0), 1)drawAxis(img, cntr, p2, (255, 255, 0), 5)angle = atan2(eigenvectors[0,1], eigenvectors[0,0]) # orientation in radiansreturn angleparser = argparse.ArgumentParser(description='Code for Introduction to Principal Component Analysis (PCA) tutorial.\This program demonstrates how to use OpenCV PCA to extract the orientation of an object.')
parser.add_argument('--input', help='Path to input image.', default='pca_test1.jpg')
args = parser.parse_args()src = cv.imread(cv.samples.findFile(args.input))
# Check if image is loaded successfully
if src is None:print('Could not open or find the image: ', args.input)exit(0)cv.imshow('src', src)# Convert image to grayscale
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY)# Convert image to binary
_, bw = cv.threshold(gray, 50, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)contours, _ = cv.findContours(bw, cv.RETR_LIST, cv.CHAIN_APPROX_NONE)for i, c in enumerate(contours):# Calculate the area of each contourarea = cv.contourArea(c)# Ignore contours that are too small or too largeif area < 1e2 or 1e5 < area:continue# Draw each contour only for visualisation purposescv.drawContours(src, contours, i, (0, 0, 255), 2)# Find the orientation of each shapegetOrientation(c, src)cv.imshow('output', src)
cv.waitKey()
注意:另一个使用PCA进行降维同时保持一定方差的示例可在opencv_source_code/samples/cpp/pca.cpp找到。
说明
读取图像并转换为二值图像
这里我们应用必要的预处理步骤,以便能够检测出感兴趣的目标对象。
parser = argparse.ArgumentParser(description='Code for Introduction to Principal Component Analysis (PCA) tutorial.\This program demonstrates how to use OpenCV PCA to extract the orientation of an object.')
parser.add_argument('--input', help='Path to input image.', default='pca_test1.jpg')
args = parser.parse_args()src = cv.imread(cv.samples.findFile(args.input))
# Check if image is loaded successfully
if src is None:print('Could not open or find the image: ', args.input)exit(0)cv.imshow('src', src)# Convert image to grayscale
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY)# Convert image to binary
_, bw = cv.threshold(gray, 50, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
提取目标对象
接着根据尺寸查找并筛选轮廓,获取剩余轮廓的方向信息。
contours, _ = cv.findContours(bw, cv.RETR_LIST, cv.CHAIN_APPROX_NONE)for i, c in enumerate(contours):# Calculate the area of each contourarea = cv.contourArea(c)# Ignore contours that are too small or too largeif area < 1e2 or 1e5 < area:continue# Draw each contour only for visualisation purposescv.drawContours(src, contours, i, (0, 0, 255), 2)# Find the orientation of each shapegetOrientation(c, src)
提取方向
方向信息通过调用 getOrientation() 函数提取,该函数执行完整的 PCA 处理流程。
sz = len(pts)data_pts = np.empty((sz, 2), dtype=np.float64)for i in range(data_pts.shape[0]):data_pts[i,0] = pts[i,0,0]data_pts[i,1] = pts[i,0,1]# Perform PCA analysismean = np.empty((0))mean, eigenvectors, eigenvalues = cv.PCACompute2(data_pts, mean)# Store the center of the objectcntr = (int(mean[0,0]), int(mean[0,1]))
首先需要将数据排列成大小为n×2的矩阵,其中n代表数据点的数量。随后即可执行PCA分析。计算得到的均值(即质心位置)存储在cntr变量中,特征向量和特征值则分别存入对应的std::vector容器。
- 结果可视化
最终结果通过drawAxis()函数进行可视化:主成分以线段形式绘制,每个特征向量会乘以对应的特征值并平移到均值位置。
cv.circle(img, cntr, 3, (255, 0, 255), 2)p1 = (cntr[0] + 0.02 * eigenvectors[0,0] * eigenvalues[0,0], cntr[1] + 0.02 * eigenvectors[0,1] * eigenvalues[0,0])p2 = (cntr[0] - 0.02 * eigenvectors[1,0] * eigenvalues[1,0], cntr[1] - 0.02 * eigenvectors[1,1] * eigenvalues[1,0])drawAxis(img, cntr, p1, (0, 255, 0), 1)drawAxis(img, cntr, p2, (255, 255, 0), 5)angle = atan2(eigenvectors[0,1], eigenvectors[0,0]) # orientation in radians
angle = atan2(p[1] - q[1], p[0] - q[0]) # angle in radianshypotenuse = sqrt((p[1] - q[1]) * (p[1] - q[1]) + (p[0] - q[0]) * (p[0] - q[0]))# Here we lengthen the arrow by a factor of scaleq[0] = p[0] - scale * hypotenuse * cos(angle)q[1] = p[1] - scale * hypotenuse * sin(angle)cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), colour, 1, cv.LINE_AA)# create the arrow hooksp[0] = q[0] + 9 * cos(angle + pi / 4)p[1] = q[1] + 9 * sin(angle + pi / 4)cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), colour, 1, cv.LINE_AA)p[0] = q[0] + 9 * cos(angle - pi / 4)p[1] = q[1] + 9 * sin(angle - pi / 4)cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), colour, 1, cv.LINE_AA)
结果
该代码会打开一张图像,检测出感兴趣物体的方向,然后通过绘制以下内容来可视化结果:检测到的感兴趣物体轮廓、中心点,以及根据提取方向确定的x轴和y轴。