论文review SfM MVS VGGT: Visual Geometry Grounded Transformer
基本信息
题目:VGGT: Visual Geometry Grounded Transformer
来源:CVPR2025 Best Paper
学校:Visual Geometry Group, University of Oxford、Meta AI
是否开源:https://github.com/facebookresearch/vggt
摘要:MVS & SfM with Transformer,里程碑意义
我们提出了VGGT,这是一个前馈神经网络,它直接从一个、几个或数百个视图中推断场景的所有关键三维属性,包括相机参数、点地图、深度图和三维点轨迹。这种方法是三维计算机视觉中的一个进步,在三维计算机视觉中,模型通常被限制在单个任务中。它也是简单而有效的,在一秒钟内重建图像,并且仍然优于需要用视觉几何优化技术进行后处理的替代品。该网络在多个3D任务中取得了最先进的结果,包括相机参数估计、多视角深度估计、稠密点云重建和3D点跟踪。我们还表明,使用预训练的VGGT作为特征骨架显著增强了下游任务,例如非刚性点跟踪和前馈新视图合成。

Introduction
(这还需要做任何总结和删改吗?逐字学习吧!)
我们考虑使用feed forward神经网络来估计在一组图像中捕获的场景的3D属性的问题。传统上,三维重建采用视觉几何方法,利用迭代优化技术,如光束平差( BA ) 。机器学习往往起到了重要的补充作用,解决了单靠几何学无法解决的任务,如特征匹配、单目深度预测等。集成已经变得越来越紧密,现在最先进的SfM ( Structure-from Motion )方法,如VGGSfM [ 125 ],通过可微的BA端到端地结合了机器学习和视觉几何。尽管如此,视觉几何仍然在三维重建中起着主要作用,这增加了复杂度和计算成本。
随着网络的功能越来越强大,我们会问,最后,3D任务是否可以直接通过神经网络来解决,几乎完全避开了几何后处理。最近的贡献如DUSt3R [ 129 ]及其进化MASt3R [ 62 ]在这个方向上取得了很好的效果,但是这些网络只能同时处理两幅图像,并依靠后处理来重建更多的图像,将两两重建融合在一起。
在本文中,我们进一步去掉了在后处理中优化3D几何的需要。我们通过引入 Visual Geometry Grounded Transformer来实现,VGGT是一个前馈神经网络,从一个场景的一个、少数甚至数百个输入视图进行三维重建。VGGT预测一组完整的3D属性,包括相机参数、深度图、点图和3D点轨迹。它在一次前向传播,以秒为单位。值得注意的是,即使没有进一步的处理,它往往优于基于优化的替代方案。这与DUSt3R,MASt3R或VGGSfM有很大的差距,它们仍然需要昂贵的迭代后优化来获得可用的结果。
我们还表明,为三维重建设计一个特殊的网络是不必要的。相反,VGGT是基于一个相当标准的Transformer,没有特定的3D或其他诱导偏差(除了帧间和全局注意力之间的交替),而是在大量具有3D标注的公开数据集上进行训练。因此,VGGT与用于自然语言处理和计算机视觉的大型模型(如GPTs ,CLIP [ 86 ],DINO [ 10、78 ]和Stable Diffusion [ 34 ] )在同一模型中构建。这些已成为可以微调以解决新的具体任务的多用途骨干。类似地,我们证明了VGGT计算的特征可以显著增强下游任务,如动态视频中的点跟踪和新颖的视图合成。
最近有几个大型3D神经网络的例子,包括Depth Anything [ 142 ]、Mo Ge [ 128 ]和LRM [ 49 ]。然而,这些模型只关注单一的三维任务,如单目深度估计或新颖的视图合成。相比之下,VGGT使用一个共享的backbone来共同预测所有感兴趣的3D数量。我们证明,学习预测这些相互关联的3D属性可以提高总体精度,尽管存在潜在的冗余。同时,我们表明,在推断过程中,我们可以从单独的预测深度和相机参数中获得点地图,与直接使用专用的点地图head相比,获得了更好的精度。
归纳起来,我们做出了以下贡献:
- 我们引入了VGGT,一个大型的前馈转换器,给定一个场景的一张、几张甚至上百张图像,可以在几秒内预测其所有关键的3D属性,包括相机内参和外参、点图、深度图和3D点轨迹。
- 我们证明了VGGT的预测是直接可用的,具有很强的竞争力,并且通常优于使用慢速后处理优化技术的最先进方法。
- 我们还表明,当进一步结合BA后处理时,VGGT在所有方面都取得了最先进的结果,即使与专门针对3D任务的子集的方法相比,VGGT也经常大幅度地提高质量。
Related Works
(非常好的综述,也没啥好总结的。VGGT中提到的文献,全部学习就完了!)
Structure from Motion
SfM是一个经典的计算机视觉问题,涉及从不同视点拍摄的静态场景的一组图像中估计相机参数并重建稀疏点云。传统的SfM pipeline 由多个阶段组成,包括影像匹配、三角测量、光束法平差等。COLMAP 是基于传统 pipeline 的最流行的框架。近年来,深度学习对SfM流水线的许多组件进行了改进,其中关键点检测[ superpoint、D2net、disk、Lift]和图像匹配[ 11, Lightglue, Superglue, Clustergnn]是两个主要的关注领域。最近的方法[ 5、FlowMap、Ba-net、Deepv2d、Droid-slam、Demon、122、VGGSfM、Deepsfm、160]探索了端到端可微的SfM,其中VGGSfM在具有挑战性的照片旅游场景中开始优于传统算法。
Multi-view Stereo
MVS目标是从多幅重叠图像中稠密地重建场景的几何结构,通常假设已知的相机参数,这些参数通常用SfM估计。MVS方法可以分为三类:传统手工设计的方法[ 38、39、96、130]、全局优化的方法[ Geo-neus、74、Nerfingmvs、147]和基于学习的方法[ 42、72、84、Mvsnet、Geomvsnet]。正如在SfM中一样,基于学习的MVS方法最近也取得了很大的进展。在这里,DUSt3R 和MASt3R 直接从一对视图中估计对齐密集点云,类似于MVS,但不需要相机参数。一些并行工作[ Mv-dust3r+、127、Fast3r、156]探索用神经网络来代替DUSt3R的测试时间优化,尽管这些尝试只能达到次优或与DUSt3R相当的性能。相反,VGGT比DUSt3R和MASt3R有更大的优势。
Tracking-Any-Point
TAP最早在Particle Video 中提出,并在深度学习时代由PIPs 复兴,旨在跟踪包括动态运动在内的视频序列中的兴趣点。给定一个视频和一些2D查询点,任务是预测这些点在所有其他帧中的2D对应关系。TAP-Vid 为该任务提出了三个benchmarks测试集,随后在TAPIR 中改进了一个简单的benchmark方法。CoTracker 利用不同点之间的相关性来跟踪遮挡,而DOT 实现了遮挡情况下的稠密跟踪。最近,TAPTR 提出一个端到端的转换器,LocoTrack 将常用的逐点特征扩展到附近区域。所有这些方法都是专门的点跟踪器。在这里,我们证明了当与现有的点跟踪器耦合时,VGGT的特征产生了最先进的跟踪性能。
Method
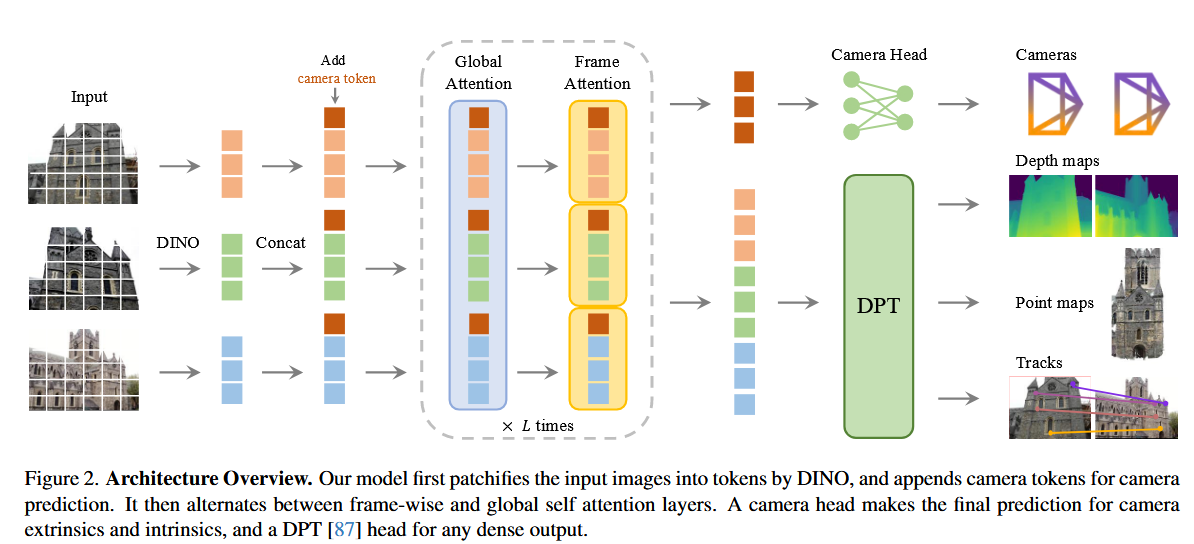
论文提出了一个名为 VGGT(Vision-Geometry Guided Transformer)的大型Transformer模型,用于处理一组输入图像并生成多种3D相关的输出结果。
3.1. Problem definition and notation





3.2. Feature Backbone
这一部分描述了VGGT模型的核心架构,即特征提取的主干网络(backbone)。VGGT采用了一个基于Transformer的大型模型,设计上尽量减少3D先验假设(inductive biases),让模型从大量带3D标注的数据中自主学习。
架构设计
- 最小3D先验:受到近期3D深度学习研究的启发(如DUSt3R 等),VGGT避免引入过多的3D几何假设,而是依赖大规模数据驱动学习。这种设计允许模型从数据中自动发现3D场景的规律,而不是依赖预定义的几何约束。
- 基于Transformer:主干网络是一个大型Transformer模型,通过自注意力机制处理多帧图像的特征,捕捉图像间的几何关系和3D一致性。

 输出
输出
- Transformer处理后的特征块集合 tI 被送入后续的预测头,用于生成相机参数、深度图、点图和跟踪特征。
3.3. Prediction heads
这一部分详细描述了VGGT如何从Transformer的输出特征生成具体的3D预测结果,包括相机参数、深度图、点图和关键点跟踪特征。





3.4. Training
这一部分描述了VGGT模型的训练过程,包括多任务损失函数、数据归一化策略、实现细节和训练数据集。VGGT通过端到端的方式联合优化Transformer模型 f和跟踪模块 T,以生成相机参数、深度图、点图和关键点跟踪特征。





Ground Truth Coordinate Normalization
3D重建任务存在尺度和平移的歧义:如果对场景进行缩放或改变全局参考坐标系,图像内容不会改变,因此多种3D重建结果可能都是合法的。为了消除这种歧义,VGGT对训练数据进行归一化处理,选择一个标准化的表示形式,并要求模型学习这种特定表示。
- 归一化步骤:
- 以第一帧为参考:所有3D量(相机参数、点图、深度图)都以第一帧相机 g1 的坐标系为参考(参考 [129])。
- 尺度归一化:
- 计算点图 P中所有3D点到原点的平均欧几里得距离,作为尺度因子。
- 使用该尺度因子归一化以下量:
- 相机平移向量 ti。
- 点图 Pi(3D点坐标)。
- 深度图 Di(深度值)。
- 关键区别:与DUSt3R [129]不同,VGGT不直接对模型预测结果进行归一化,而是通过训练数据中的归一化方式,强制模型学习这种标准化的输出形式。
- 意义:
- 归一化消除了尺度和平移歧义,确保模型输出一致的3D表示。
- 通过数据驱动的方式,模型能够学习到归一化的几何规律,而非依赖后处理。
训练硬件:
- 使用 64个A100 GPU,训练耗时 9天。(什么!?!?!?,虽然对于高校这个不是一般的实验室能用得起的,但是对于公司来说成本太低了)
训练数据(Training Data)
VGGT使用了一个大规模、多样化的数据集集合进行训练,涵盖室内外场景、真实和合成数据,具体包括:
- Co3Dv2 :多视角物体数据集。
- BlendMVS :多视角立体视觉数据集。
- DL3DV :3D视觉数据集。
- MegaDepth :大规模深度估计数据集。
- Kubric :合成视频数据集。
- WildRGB :野外RGB图像数据集。
- ScanNet :室内场景扫描数据集。
- HyperSim :高逼真度合成室内场景数据集。
- Mapillary :街景图像数据集。
- Habitat 、Replica :虚拟环境数据集。
- MVS-Synth :合成多视角数据集。
- PointOdyssey :点跟踪相关数据集。
- Virtual KITTI :虚拟驾驶场景数据集。
- Aria Synthetic Environments 、Aria Digital Twin :增强现实合成数据集。
- 类似Objaverse 的合成数据集:艺术家创建的资产数据集。
- 数据多样性:
- 涵盖室内外、真实和合成场景,增强模型泛化能力。
- 3D标注来源包括直接传感器捕获、合成引擎生成或结构光流(SfM)技术 。
- 数据集规模和多样性与MASt3R 相当。
(好嘛,市面上所有的MVS、SfM都在里面了吧,可是够训的了,就当帮我整理了一下数据集)
实验
4.1. Camera Pose Estimation
在 CO3Dv2 和 RealEstate10K 数据集上评估相机姿态估计性能。位姿估计相当准
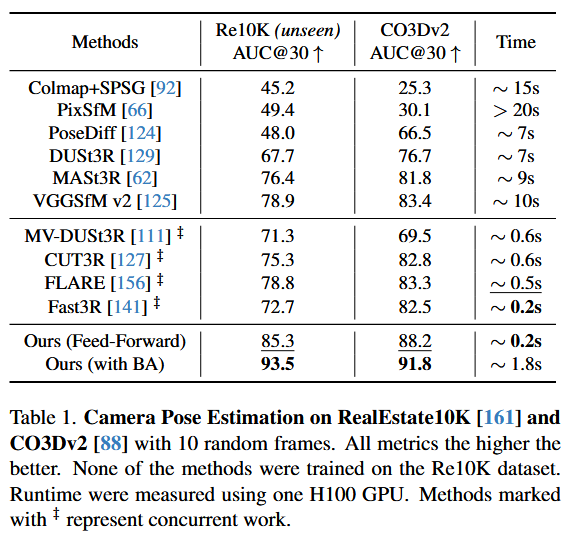
4.2. Multi-view Depth Estimation
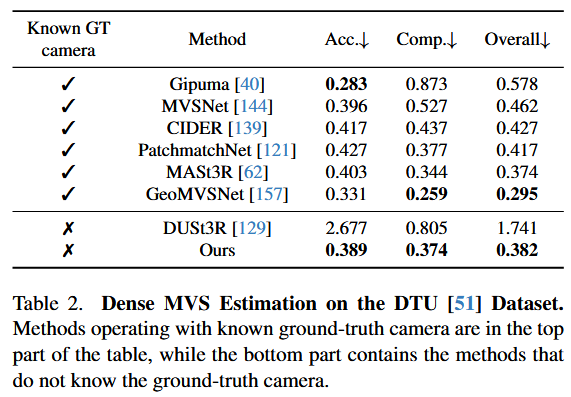
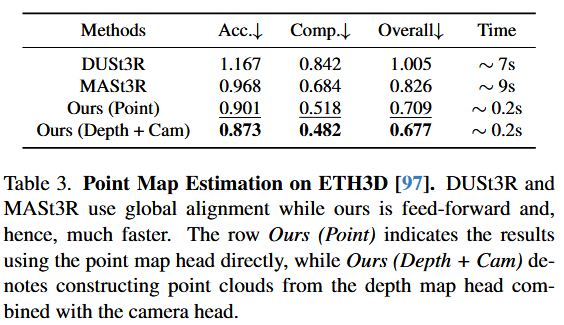
4.3. Point Map Estimation


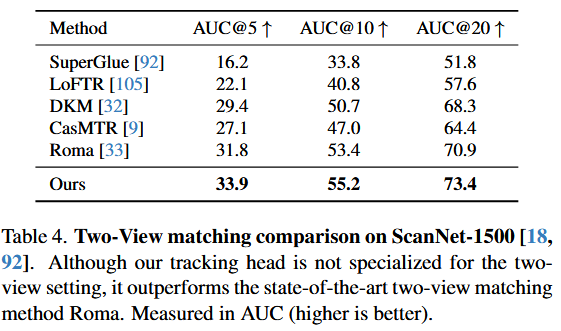
4.4. Image Matching
初体验
https://huggingface.co/spaces/facebook/vggt 效果也太好了吧!而且超级快!
参考文献
[5] Eric Brachmann, Jamie Wynn, Shuai Chen, Tommaso Cavallari, A ́ ron Monszpart, Daniyar Turmukhambetov, and Victor Adrian Prisacariu. Scene coordinate reconstruction: Posing of image collections via incremental learning of a relocalizer. In ECCV, 2024. 2, 13
[10] Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ́e J ́egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin.Emerging properties in self-supervised vision transformers. In Proc. ICCV, 2021. 2, 12
[11] Hongkai Chen, Zixin Luo, Jiahui Zhang, Lei Zhou, Xuyang Bai, Zeyu Hu, Chiew-Lan Tai, and Long Quan. Learning to match features with seeded graph matching network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6301–6310, 2021. 2
[34] Patrick Esser, Robin Rombach, and Bj ̈orn Ommer. Taming transformers for high-resolution image synthesis. In Proc. CVPR, 2021. 2
[38] Yasutaka Furukawa, Carlos Herna ́ndez, et al. Multi-view stereo: A tutorial. Foundations and Trends® in Computer Graphics and Vision, 9(1-2):1–148, 2015. 2
[39] Silvano Galliani, Katrin Lasinger, and Konrad Schindler. Massively parallel multiview stereopsis by surface normal diffusion. In Proceedings of the IEEE international conference on computer vision, pages 873–881, 2015. 2
[42] Xiaodong Gu, Zhiwen Fan, Siyu Zhu, Zuozhuo Dai, Feitong Tan, and Ping Tan. Cascade cost volume for highresolution multi-view stereo and stereo matching. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2495–2504, 2020. 2
[49] Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: Large reconstruction model for single image to 3D. In Proc. ICLR, 2024. 2, 9
[62] Vincent Leroy, Yohann Cabon, and Je ́roˆme Revaud. Grounding image matching in 3d with mast3r. arXiv preprint arXiv:2406.09756, 2024. 2, 7, 12, 13
[72] Zeyu Ma, Zachary Teed, and Jia Deng. Multiview stereo with cascaded epipolar raft. In European Conference on Computer Vision, pages 734–750. Springer, 2022. 2
[74] Michael Niemeyer, Lars Mescheder, Michael Oechsle, and Andreas Geiger. Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3504–3515, 2020. 2
[78] Maxime Oquab, Timothe ́e Darcet, The ́o Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin ElNouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, and Piotr Bojanowski. DINOv2: Learning robust visual features without supervision. Transactions on Machine Learning Research, 2024. 2, 4, 11
[84] Rui Peng, Rongjie Wang, Zhenyu Wang, Yawen Lai, and Ronggang Wang. Rethinking depth estimation for multiview stereo: A unified representation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8645–8654, 2022. 2
[86] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Proc. ICML, pages 8748–8763, 2021. 2
[96] Johannes L Scho ̈nberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14, pages 501–518. Springer, 2016. 2
[122] Jianyuan Wang, Yiran Zhong, Yuchao Dai, Stan Birchfield, Kaihao Zhang, Nikolai Smolyanskiy, and Hongdong Li. Deep two-view structure-from-motion revisited. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 8953–8962, 2021. 2, 13
[125] Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. VGGSfM: visual geometry grounded deep structure from motion. In Proc. CVPR, 2024. 1, 2, 3, 6, 7, 10, 12, 13
[127] Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A. Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state, 2025. 2, 7
[128] Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. MoGe: unlocking accurate monocular geometry estimation for opendomain images with optimal training supervision. arXiv, 2410.19115, 2024. 2
[129] Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: Geometric 3D vision made easy. In Proc. CVPR, 2024. 1, 2, 3, 4, 6, 7, 11, 12, 13
[130] Yuesong Wang, Zhaojie Zeng, Tao Guan, Wei Yang, Zhuo Chen, Wenkai Liu, Luoyuan Xu, and Yawei Luo. Adaptive patch deformation for textureless-resilient multi-view stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1621–1630, 2023. 2
[142] Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. In Proc. CVPR, 2024. 2
[147] Lior Yariv, Yoni Kasten, Dror Moran, Meirav Galun, Matan Atzmon, Basri Ronen, and Yaron Lipman. Multiview neural surface reconstruction by disentangling geometry and appearance. Advances in Neural Information Processing Systems, 33:2492–2502, 2020. 2
[156] Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou, Yujun Shen, and Gordon Wetzstein. Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views, 2025. 2, 7
[160] Tinghui Zhou, Matthew Brown, Noah Snavely, and David G Lowe. Unsupervised learning of depth and egomotion from video. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 18511858, 2017. 2, 13