全连接神经网络
文章目录
- 前言
- 一、神经网络简介
- 二、全连接神经网络
- 1.基本结构
- 2.构建神经网络
- 二、数据准备
- 1. 构建数据类
- 2.数据加载器
前言
通过今天的学习,我掌握了全连接神经网络的基本概念以及构建;数据准备的相关函数。
一、神经网络简介
神经网络(Neural Networks)是一种模拟人脑神经元网络结构的计算模型,用于处理复杂的模式识别、分类和预测等任务。
人工神经元是神经网络的基本单元,组成部分包括:
- 输入:代表输入数据,每一个数据对应一个权重。
- 权重:每个数据对应一个权重。
- 偏置:类似线性回归中的截距。
- 激活函数:将加权求和后的结果进行非线性映射,为模型引入非线性,表示更加复杂的关系。
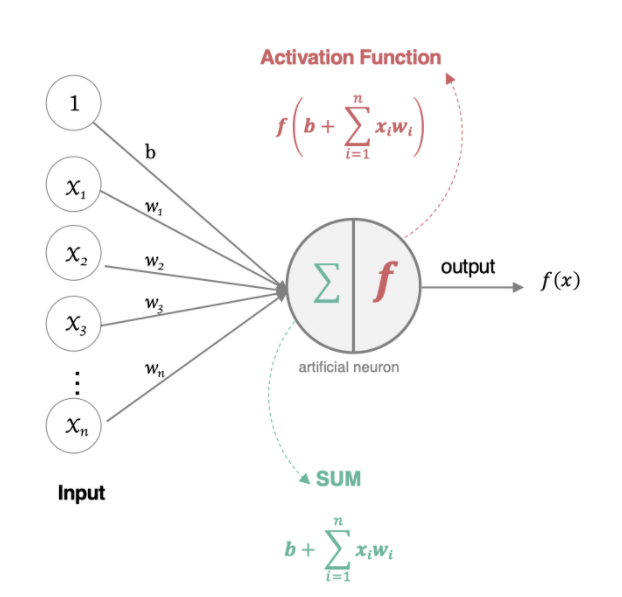
tips:可以粗略地理解为“加权求和以及激活函数映射”
二、全连接神经网络
1.基本结构
神经网络有三个基础层构成:
-
输入层(Input): 神经网络的第一层,负责接收外部数据,不进行计算。
-
隐藏层(Hidden): 位于输入层和输出层之间,进行特征提取和转换。隐藏层一般有多层,每一层有多个神经元。
-
输出层(Output): 网络的最后一层,产生最终的预测结果或分类结果
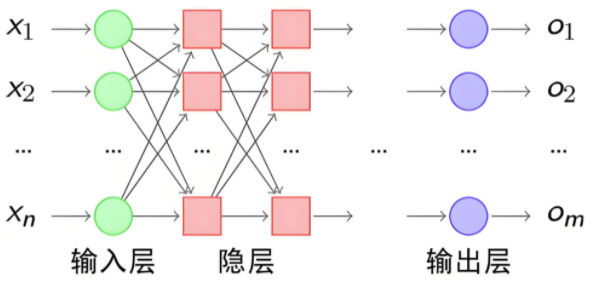
如果当前节点的每一个神经元都与前一层所有神经元连接且本层之间没有连接,则构成了全连接神经网络。
实际情况中,样本以及特征往往是大量的,我们一般用向量进行表示。即:
z=xwT+bz =xw^T+bz=xwT+b -
x代表输入数据,形状为 (batch_size, in_features),分别代表样本的个数和单个样本的特征数。
-
w代表权重矩阵,形状为 (out_features, in_features),out_features:当前层输出特征数量。
-
b代表偏置项,形状为 (out_features).
-
z代表输出,形状为(batch_size, out_features),out_features:每个样本经过神经网络得到的结果。
全连接神经网络的局限性也比较明显:
1.权重数量较大,面对海量数据和特征会导致计算量显著增大。
2.模型学习全局特征,在进行扁平化后无法很好地学习到数据的局部特征。
tips:深入理解“全连接”的意义,可以帮助理解各个部分的形状,每一个神经元都会与前一层所有神经元连接,所以当前层输入的形状应该与上一层输出的形状对应。
2.构建神经网络
了解了结构,我们可以自己构建神经网络。
这里以比较简单的网络结构为例,介绍一些常用的组件:
- torch.nn.Linear(in_features, out_features, bias=True),线性层组件,用于构建线性层。
- torch.nn.functional,包括常用的激活函数,如:sigmoid,tanh,relu,softmax。
- 损失函数组件,包括均方损失,L1损失(用于回归)等;交叉熵损失,二元交叉熵损失(用于分类)。
- 优化器组件,用于更新参数以及最小化损失函数,包括:SGD,Adagrad,Adma等。同时提供了zero_grad(),backward(),step(),实现了梯度清空,反向传播以及参数更新的功能。
import torch
from torch import nn
from torch.data
import torch.optim as opt# 输入值
x = torch.tensor([1,2,3,4,5],dtype=torch.float).reshape(5,1)
y = torch.tensor([3,5,7,9,11],dtype=torch.float).reshape(5,1)# 创建模型
model = nn.Linear(in_features=1,out_features=1,bias=True)# 构建损失函数
cri = nn.MSELoss()# 定义优化器
optmizer = opt.SGD(model.parameters(),lr=0.01)# 迭代次数
epochs = 100for epoch in range(epochs):# 预测值y_perd = model(x)loss = cri(y_pred,y)# 清空梯度opt.zero_grad()# 反向传播loss.backward()# 更新参数opt.step()if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')
也可以自定义全连接网络模型:
1.继承nn.Model类
2.自定义__init__
import torch
from torch import nnclass MyFcnn(nn.Model):def __init__(self,input_size,output_size):super(MyFcnn,self).__init__()self.fc1 = nn.Linear(input_size,64)self.fc2 = nn.Linear(64,32)self.fc3 = nn.Linear(32,output_size)def forward(seld,x):x = self.fc1(x)x = self.fc2(x)x = self.fc3(x)
二、数据准备
1. 构建数据类
(1).DataSet类,一个抽象类,必须实现:
__len__: 返回数据集的大小__getitem__: 支持整数索引,返回对应的样本
import torch
from torch import nn
from torch.utils.data import Datasetclass MyDataset(Dataset):def __init__(self,data,labels):self.data = dataself.labels = labeldef __len__(self):return len(self.data)def __getitem__(self,index):sample = self.data[index]label = self.labels[index]return sample,label
(2)TensorDatasets类,已经自动实现了__len__和__getitem__,更加方便但灵活性下降。
2.数据加载器
数据加载器的主要用途是批量地取出数据,同时还具有打乱数据顺序以及多线程加载的功能。
返回一个可迭代对象,可用循环依次取出。
dataloader = Dataloader(dataset, # 数据集batch_size, # 批量大小shuffle, # 是否打乱num_worker # 多线程
)
THE END