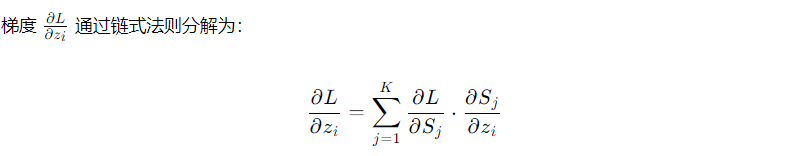SoftMax 函数
SoftMax 函数是机器学习中常用的激活函数,尤其在多分类任务中,用于将输出转化为概率分布。以下是对其详细介绍:
1. 数学定义

2. 核心特性
- 概率解释:输出可视为样本属于各类别的概率。
- 单调性:输入值越大,对应输出概率越高,保持输入的顺序。
- 平移不变性:输入向量整体加减常数 ( c ),输出不变。即:
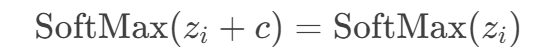
- 这一性质用于数值稳定性优化(见后文)。
3. 数值稳定性
指数运算可能导致数值溢出(如 ( e^1000 ) 超出浮点范围)。解决方法:
- 减去最大值:计算时对输入向量 Z 的每个元素减去最大值 max(z):
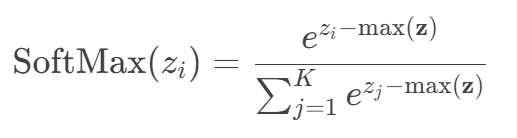
- 此操作不影响结果,但避免指数爆炸。
4. 导数与交叉熵损失
当 SoftMax 与交叉熵损失结合时,梯度计算高效简化:

5. 温度参数(Temperature Scaling)
引入温度 ( T ) 调整输出分布的平滑程度:
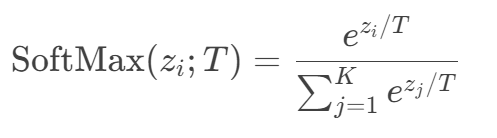
- 高温( T > 1):分布更平缓,探索性增强。
- 低温( T < 1):分布更尖锐,接近 argmax。
- 应用场景:模型蒸馏、调整预测置信度。
6. 与 LogSoftMax 的关系
- LogSoftMax:对 SoftMax 结果取对数:
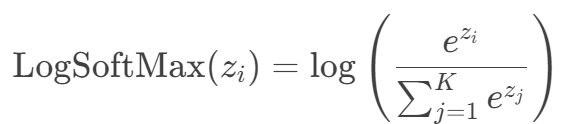
- 优势:数值稳定,直接用于交叉熵损失计算(如 PyTorch 的 nn.LogSoftmax + nn.NLLLoss)。
7. 应用场景
- 多分类输出层:如 CNN 对图像分类(MNIST、CIFAR-10)。
- 强化学习:策略网络输出动作概率。
- 注意力机制:计算注意力权重(如 Transformer)。
8. 示例
输入向量:Z= [1.0, 2.0, 3.0]
- 常规 SoftMax:
- 计算指数:
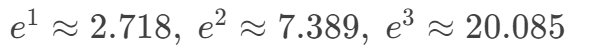
- 归一化:( [0.090, 0.245, 0.665] )
- 第三个类别概率最高(65%)。
- 温度 ( T = 2 ):
- 调整后输入:( [0.5, 1.0, 1.5] )
- 输出更平缓:( [0.186, 0.307, 0.507] )
9. 对比其他函数
| 函数 | 用途 | 输出范围 | 特点 |
| SoftMax | 多分类输出层 | 概率分布(和为1) | 可导,放大差异 |
| Sigmoid | 二分类输出层 | 单个概率(0~1) | 处理二分类问题 |
| ReLU | 隐藏层激活 | 非负值 | 缓解梯度消失,计算高效 |
10. 总结
SoftMax 函数通过指数运算与归一化,将输入映射为概率分布,是多分类任务的核心组件。其数值稳定性优化、与交叉熵损失的高效结合,以及温度参数的灵活性,使其在深度学习中广泛应用。理解其数学原理及实现细节,对模型设计和调试至关重要。
交叉熵损失函数 与 SoftMax 函数的梯度推导如下
1. 链式法则应用