AI智能体|扣子(Coze)搭建【公众号对标文章采集拆解】工作流
从发布第一篇文章到今天,一晃时间过去已经半年多了,能坚持更新,全靠兄弟姐妹们的支持。
今天和大家分享一下这半年多做自媒体的感受,其中有开心的时候,也有难过的时候,也有焦虑数据的时候。
这也算是给一些想入行自媒体的伙伴一些告示吧,将来你们可能会遇到的情况。
开心的时候:
比如自己的文章内容获得了一些用户的认可,他们有些人看了我的内容后跑来和我说,我的内容能学到东西,讲的也挺细致的,证明是真在学,虽然我不知道你是不是同行。
再比如,有些文章获得了一些用户的打赏,我认为这是对我最高的认可了,还有一些伙伴支持我的产品,选择加入咱们的学习群,当然我也会好好的交付,做好答疑。
再比如,认识一些志同道合的伙伴,进入了一个学习氛围不错的圈子,大家都在这条路上持续成长,持续进步。
......
难过的时候:
有些人只是把我的服务当成理所当然,比如之前有个兄弟加我,一直问我智能体的问题,他刚学没多久,问题很多,然后我也耐心的给他答疑。
后来有一天,他又跑来问我,但是当时我没有回,因为当时我很忙,我没有看见这条消息,后来过了两天,我再给他回复的时候,他已经把我给删了。
而且这种事情不止发生了一次,这让我非常的无语。
这就好像我是一个工具一样,对他有用,一个劲的白嫖,是不可能付一毛钱的,只在乎自己的利益,我必须帮他,对他没用了,或者不能无条件帮他了,就开始情绪化了。
这也是后来我为啥后来我说多次咨询就按工时算。
因为有些人是不懂”利他“与”感恩“的,帮了他,谢谢也不说,然后第二次又来求助。
好像帮他是我的义务一样,我也不想因为这种事跟你结仇啥的,建立好自己的边界感,相互尊重。
......
焦虑的时候:
做自媒体最焦虑的时候,大多数情况来源于数据不好,那些说不担心的都是假话,毕竟这关乎收益了都。
但其实我的账号并没挣米,你们也看到了,我是没接过广子的,不过后面接不接就得看我会不会穷到哪种程度了。
其实焦虑就是想太多,直接干活就不焦虑了,正在焦虑的伙伴,干起来。
大家也可以去看看”教员当年为啥不焦虑?“
好了,扯完了,开始今天的内容,我们先看看这个工作流的效果如何。
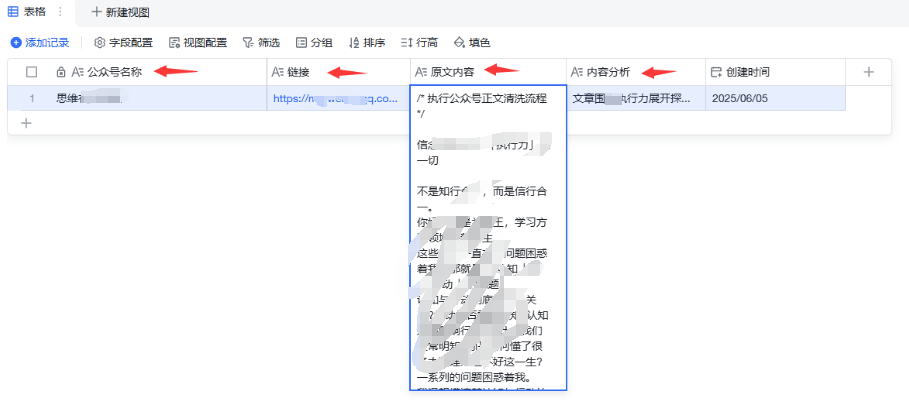
需求分析
有些人可能不知道为啥要做对标账号内容的一个采集,其实本质来说就是降低持续输出内容的一个难度。
刚做自媒体的伙伴,觉得自己肚子有很多的干货,想把这些内容都分享出去。
但当你分享几篇内容之后,你很可能会不知道自己要写什么,没有灵感。
这时候素材库,内容库就极其的重要,没灵感的时候去素材库里找找灵感。
这也是为什么做自媒体的人需要搭建自己的内容库,知识库,案例库等等,如果不搭建就很有可能陷入无内容可写的局面。
但我们人工一点点的去收集这些素材十分耗时耗力,而且这是机械性的活,完全可以交给 AI 来做,把自己的时间花在更有价值的地方上。
因此这个工作流在这方面是有需求的,如果你做自媒体,你肯定懂它的好处。
工作流流程分析
整体的事件流程如下。
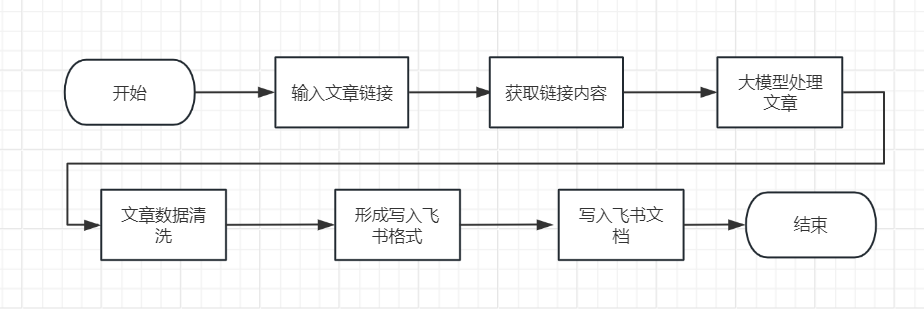
整体的 Coze 工作流如下。
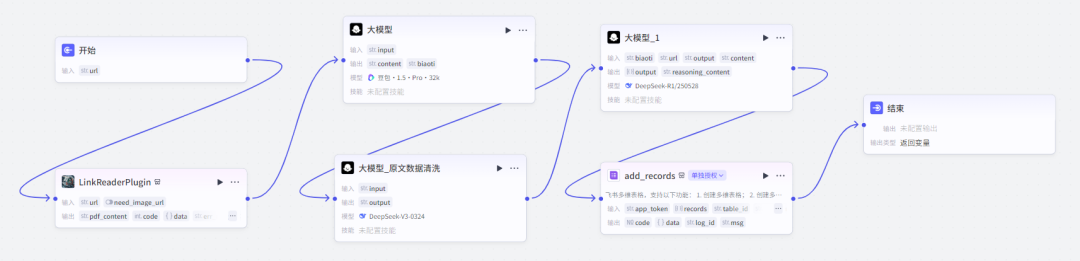
保姆级工作流教程
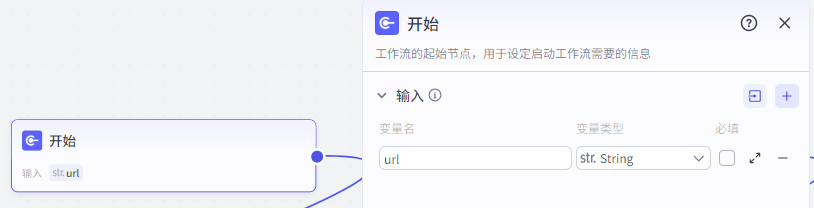
第一步,开始节点
开始节点我们设置一个变量值 url 作为文章的链接输入进去。
第二步,链接读取节点
输入文字链接后,我们需要用这个节点获取文章链接的内容,为后面做准备。
所以我们这里只需要吧 url 的值设置为开始节点的 url 的值就行了。
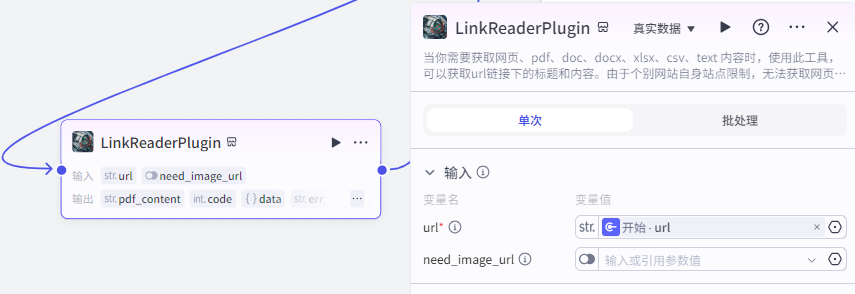
第三步,内容解析节点(大模型)
这个节点的作用就是分析文章内容,拆解爆款的元素,写作手法,大纲结构等等。
这个节点的提示词可以根据自己的情况进行更改,这里我就不提供了,大家自己搞,如果需要用我的,那么就进群就行。
我们这里设置一个变量名 input 数据来源为链接读取节点的 content 。
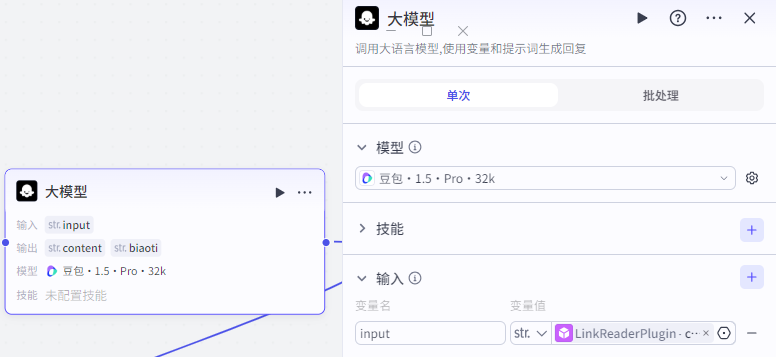
第四步,数据清洗节点
由于链接读取节点输出的文章原文内容数据,存在混乱的情况,导致其排版,内容的格式非常的乱,难以预览。
所以,我们需要添加一个节点,把内容给清洗出来,为其提升可读性,同时也为导入多维表格做准备,这里我们选择 DeepSeep V3 模型。
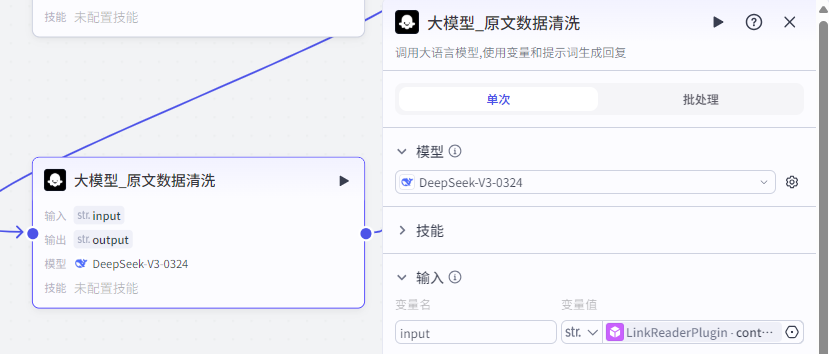
注:提示词这里我就不提供了,有需要的就找我吧。
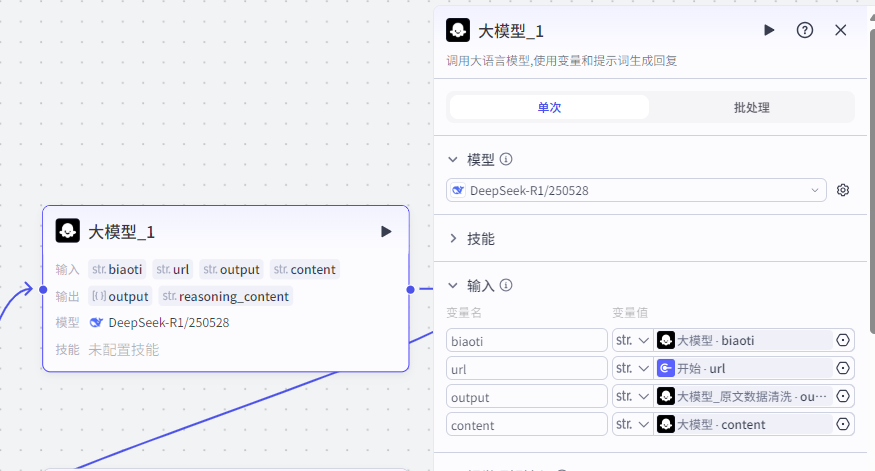
第五步,形成写入飞书文档的格式
大多数将内容写入飞书多维表格的方法都是采用其代码的方式,之前我们也是采用代码的方式来导入飞书中。
但后面考虑到大家不怎么会代码,同时也为了简化操作,我们就更改成了这种方式,降低了难度。
这个节点,我们设置 4 个变量值,biaoti,url,output,content 分别代表的意思是文章的标题,文章的链接,文章的原文,文章的拆解内容。
系统提示词
# 角色
你是一个专业的fields格式转换专家,你需要将用户输入的内容按照格式严格输出,最后以json格式输出。# 能力
## 工作步骤
1、将用户输入的内容在fields中以字符串的格式输出为[{
"fields":{
"公众号名称":"{{biaoti}}",
"链接":"{{url}}",
"原文内容":"{{output}}",
"内容分析":{{content}}
}}]# 要求
你必须严格按照上面的工作步骤输出内容,不得输出其他无关内容,否则扣分。第六步,写入飞书
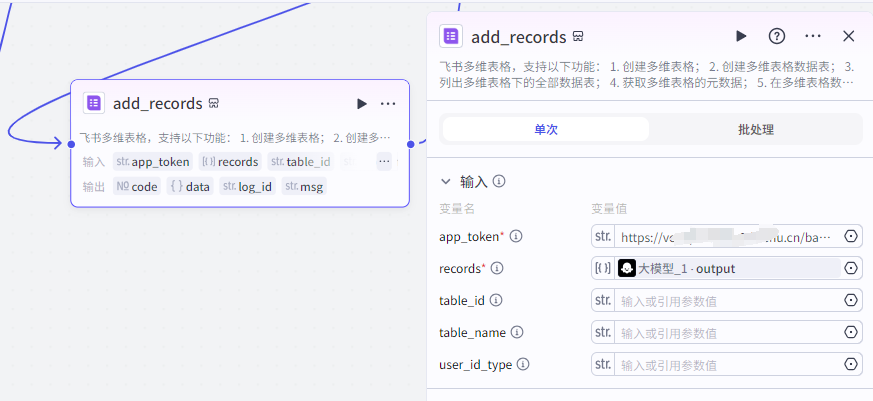
这一步就是将内容导入飞书中了,我们只需要填两个变量值,app_token,records。
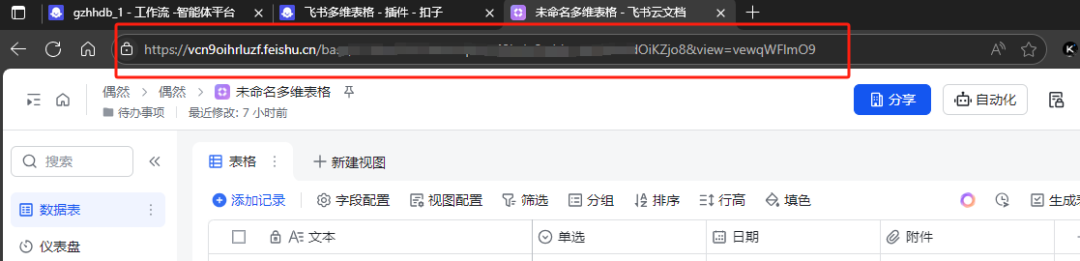
由于存在第一次看我文章的兄弟姐妹们,或者是刚学的兄弟姐妹们,我这里就解释一下 app_token 怎么获取。
我们首先打开飞书的网页版,然后创建一个多维表格,这个多维表格的链接就是 app_token 。
第七步,结束
结束节点不需要内容,单纯完成一个闭环即可。
总结
整体步骤一共有 7 步,操作也不是很难,最重要的是这里面的步骤没用代码,对那些基础不是特别好的小伙伴来说,十分友好。
接下来,咱们再说说自媒体。
我知道看我文章的有些也是做自媒体的同行,你们肯定会遇到一些蛮不讲理的情况,也会遇到焦虑自己数据的情况,担心自己写的不好的情况。
但不要慌,框框干就行了,可以多看看当年教员为啥不焦虑?
祝你们在自媒体的路上越走越远,但一定要勿忘初心,把认可你的用户当朋友来对待,不要装逼不要飘。
注意,我说的是认可你的用户。
最后,感谢兄弟姐妹们的支持,你的认可是我持续进步的动力!