如何选择有效的CoT提示提升模型推理性能!
摘要:尽管大型语言模型(LLMs)取得了显著的成功,但其底层的 Transformer 架构在处理复杂推理任务时存在固有限制。链式思维(Chain-of-Thought,CoT)提示作为一种实用的解决方法应运而生,但大多数基于 CoT 的方法依赖于单一的通用提示,例如“逐步思考”,而没有针对具体任务的适应性。这些方法期望模型自行发现有效的推理路径,迫使其在庞大的提示空间中进行搜索。相比之下,许多研究已经探索了针对具体任务的提示设计,以提升性能。然而,这些设计通常是通过试错法开发的,缺乏理论基础。因此,提示工程仍然主要是临时性的且缺乏指导。在本文中,我们提供了一个理论框架,解释了为什么某些提示能够成功,而其他提示则会失败。我们表明,提示的作用是作为选择器,在链式思维推理过程中从模型的完整隐藏状态中提取特定的与任务相关的信息。每个提示定义了通过答案空间的独特轨迹,而选择这一轨迹对于任务性能以及在答案空间中的未来导航至关重要。我们分析了为给定任务寻找最优提示的复杂性以及提示空间的大小。我们的理论揭示了有效提示设计背后的原则,并表明使用像“逐步思考”这样的模型自引导提示的简单 CoT 方法可能会严重阻碍性能。通过实验,我们展示了最优提示搜索可以在推理任务上带来超过 50% 的性能提升,我们的工作为提示工程提供了理论基础。
一、背景动机
论文题目:Why Prompt Design Matters and Works: A Complexity Analysis of Prompt Search Space in LLMs
论文地址:https://arxiv.org/pdf/2503.10084
Transformer模型由于注意力机制的固定深度限制,难以处理需要多步递归推理的复杂任务(如数学运算、逻辑推理),无法实现真正的递归计算。 传统的“仅生成答案”的自回归模型(如GPT)缺乏中间推理步骤,导致在需要迭代更新状态的任务中表现不佳(例如国际象棋棋盘状态更新、多位数累加)。
思维链(CoT)提示通过将推理过程外化为文本,模拟递归计算,理论上可提升模型的推理深度。然而,主流方法依赖通用提示(如“think step by step”),缺乏任务特定的引导,导致模型在庞大的提示空间中盲目搜索,易生成次优推理路径。 现有提示工程多基于试错法,缺乏理论支撑,难以解释为何某些提示有效而其他提示失败。
该文章首次从理论层面解析提示对LLM推理的影响,为提示工程从经验主义走向科学方法论奠定基础,推动“模型能力+提示优化”的协同进化范式。
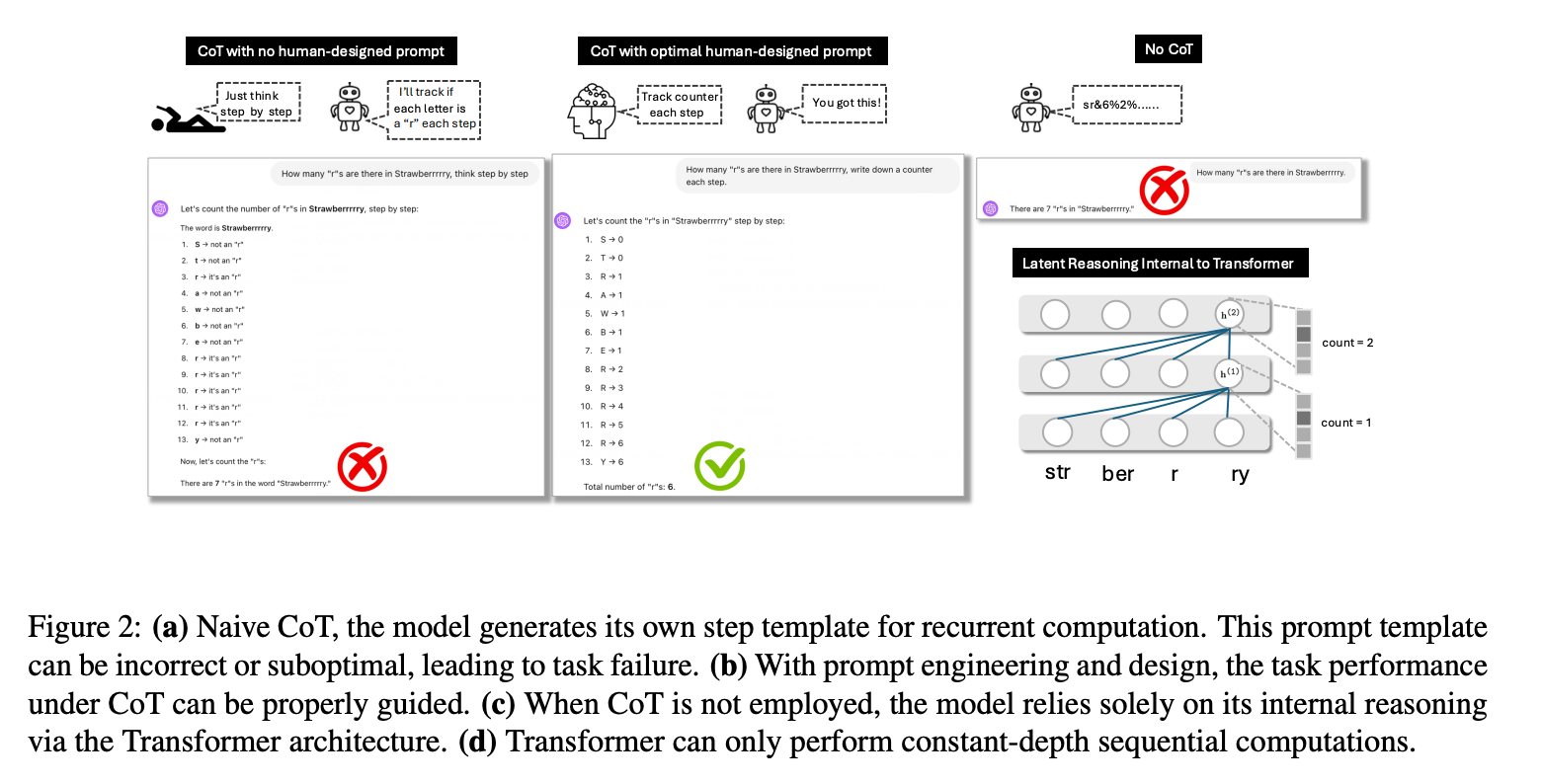
二、核心贡献
1. 提出提示空间与答案空间的理论框架
- 提示空间:由所有可能的推理步骤模板组成,每个模板定义了从模型隐藏状态 ( h ) 中提取信息的方式(如提取计数器、状态标志等)。
- 答案空间:在特定提示模板下,模型生成的所有可能答案路径。
- 证明提示模板的选择直接影响答案空间的复杂度。例如,正确的提示可将问题复杂度从指数级降至多项式级,而次优提示可能导致搜索空间爆炸。
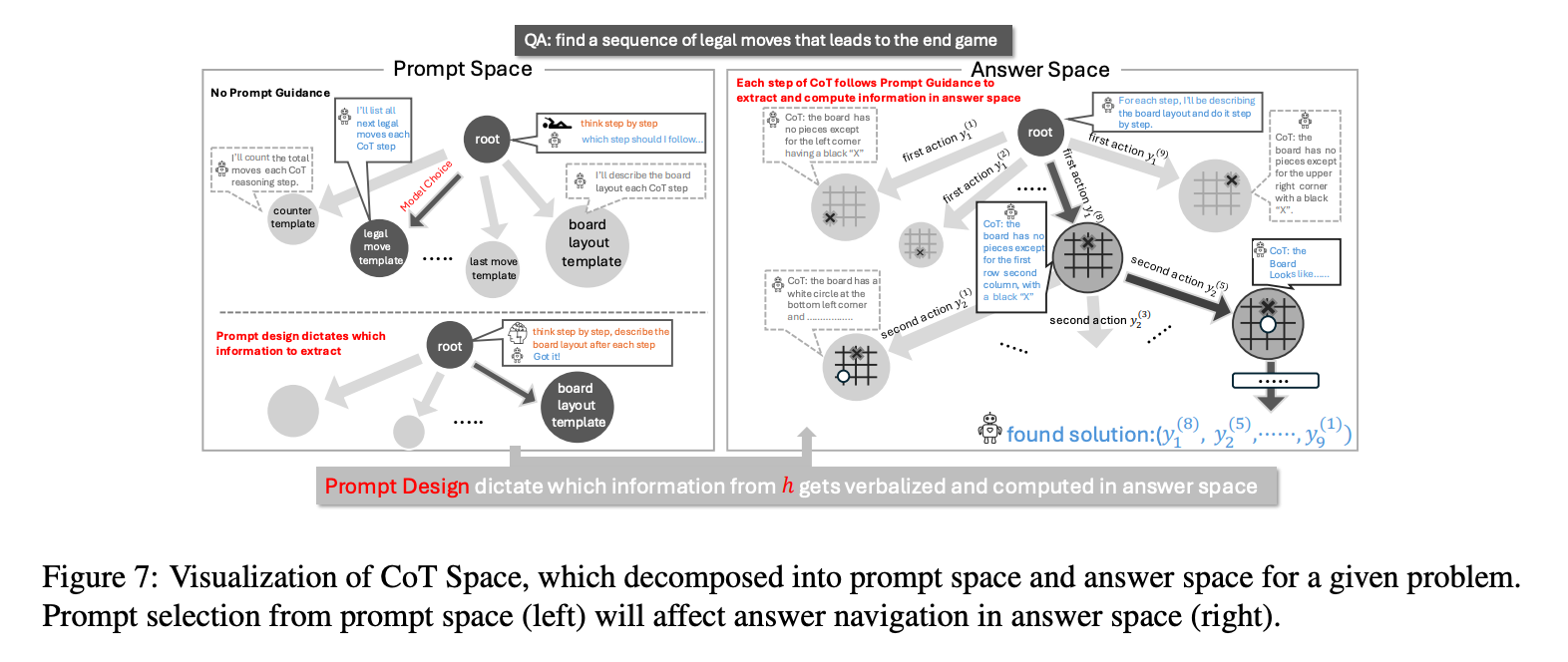
2. 揭示提示设计的关键原理
- 提示作为“信息选择器”,其作用是从隐藏状态 ( h ) 中提取任务相关的关键信息(如数学运算中的中间结果、逻辑判断中的标志位),并通过自然语言令牌序列 ( o ) 重新注入模型,形成递归计算的伪循环。
- 理论推导提示空间复杂度为组合数 ( C(n, s) ),其中 ( n ) 为隐藏状态信息量,( s ) 为单步提示提取的信息量。任务难度越高,所需 ( s ) 越大,对提示设计的依赖性越强。
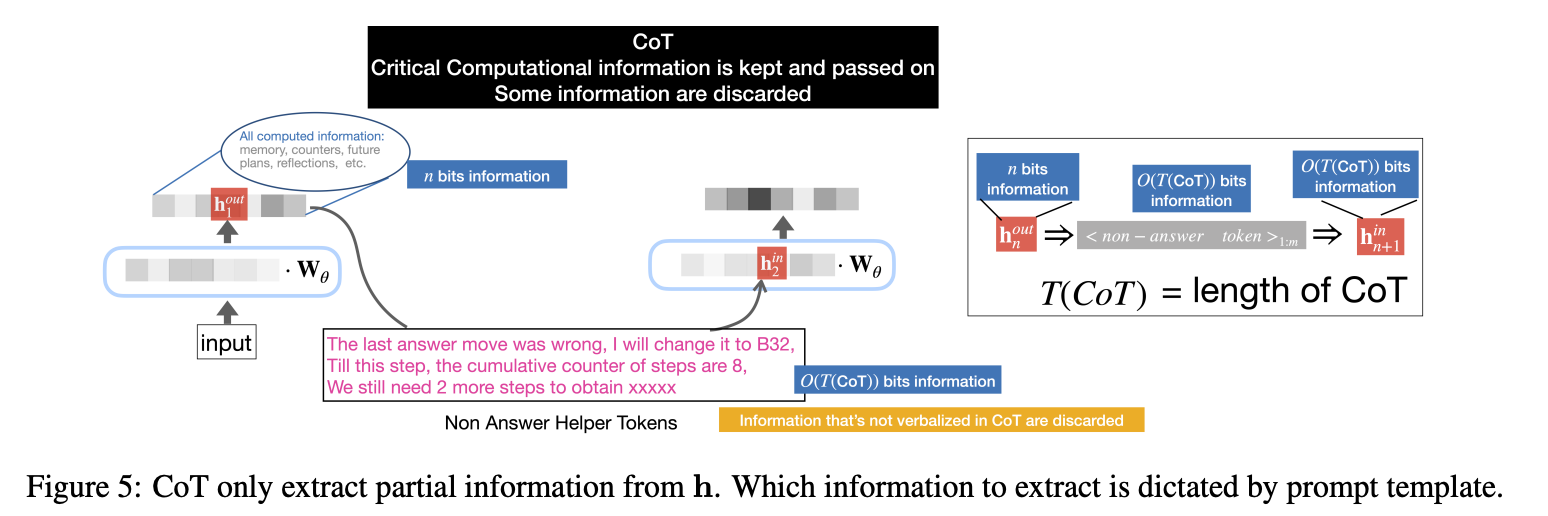
三、实现方法
3.1 任务分解与提示设计
- 将复杂任务拆解为可递归的子步骤,设计任务特定提示模板,明确每一步需提取的信息类型。
- 奇偶校验任务:提示模板指定“初始化计数器→逐元素计数→判断奇偶性”的步骤,强制模型提取计数器状态。
- 列表反转任务:提示模板要求“从列表头部移除元素并添加到结果字符串前端”,引导模型模拟栈操作。
3.2 两阶段训练策略
- 监督微调(SFT):使用多智能体系统生成高质量推理轨迹(CoT数据),包含任务特定提示和中间步骤。
- 规划器:分解任务为子问题,生成初始查询。
- 重写器:优化搜索查询,提升信息检索准确性。
- 观察者:分析搜索结果,决定是否继续推理或终止。
- 强化学习(RL):采用动态采样策略优化(DAPO),结合格式奖励(响应结构正确性)和答案奖励(结果准确性),惩罚冗余信息生成,奖励关键信息提取。
3.3 课程学习与复杂度控制
- 按掩码数量(即推理步骤数)递增设计训练数据,从简单单步任务(( k=1 ))逐步过渡到复杂多步任务(( k=4 )),避免模型因任务难度骤增而陷入局部最优。
四、实验结论
4.1 核心性能对比
- 在正则任务(如奇偶校验、循环导航)中,使用最优提示的CoT模型准确率达95%以上,显著优于无CoT模型(<60%)和通用提示CoT(<85%)。
- 在上下文无关任务(如列表反转、栈操作)中,次优提示导致准确率下降30%-50%,而最优提示使模型接近专家循环神经网络(RNN)的性能(>90%)。
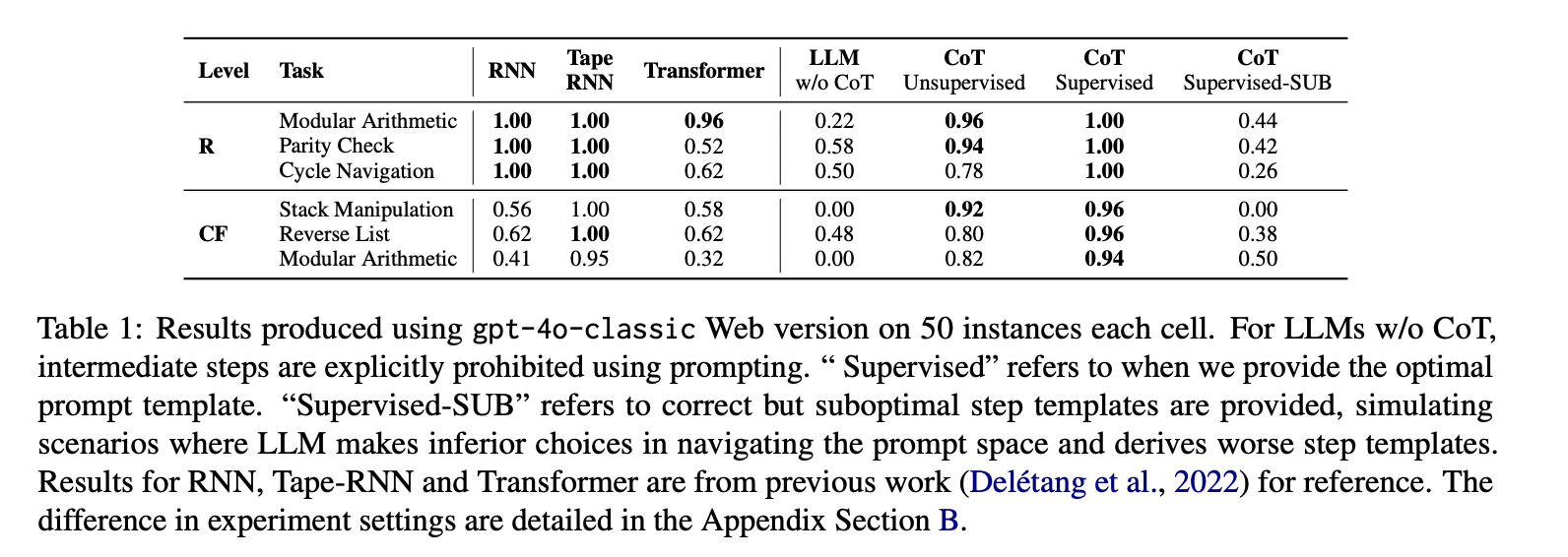
4.2 提示空间搜索的重要性
- 消融实验表明,移除提示监督后,模型在复杂任务中的准确率随机波动(约50%),验证了任务特定提示对递归推理的必要性。
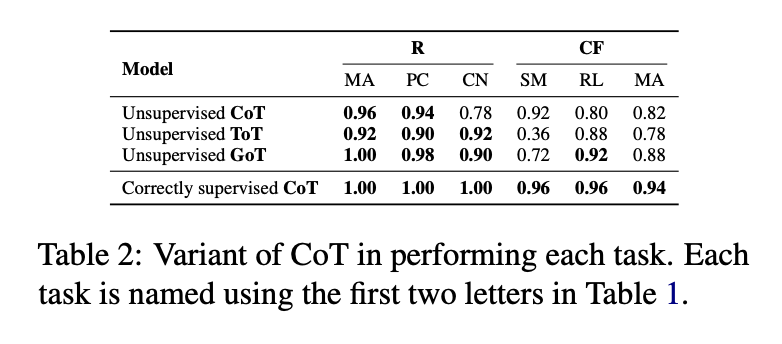
- CoT变体(ToT、GoT)在最优提示下仅提升5%-8%准确率,但在次优提示下无法挽救性能,说明其优化范围局限于答案空间,无法弥补提示设计缺陷。
五、总结
文章通过对 CoT 提示的理论分析和实验验证,揭示了提示空间和答案空间的复杂性及其相互作用对 LLMs 推理性能的影响。研究强调了在 CoT 过程中,正确选择提示模板的重要性,并展示了人类监督在提高模型推理能力方面的关键作用。尽管文章的研究主要集中在简单的推理任务上,但其发现对于理解和设计更有效的 CoT 提示策略具有重要意义,为未来在更复杂任务上的研究提供了理论基础和实践指导。