【T2I】TOKENCOMPOSE: Text-to-Image Diffusion with Token-level Supervision
CODE:CVPR 2024
TokenCompose: Text-to-Image Diffusion with Token-level Supervision
Abstract
我们提出了TokenCompose,这是一种用于文本到图像生成的潜在扩散模型,可在用户指定的文本提示和模型生成的图像之间实现增强的一致性。尽管取得了巨大的成功,但潜扩散模型中的标准去噪过程仅以文本提示为条件,对文本提示与图像内容的一致性没有明确的约束,导致组合多个对象类别的结果不理想。我们提出的TokenCompose旨在通过在微调阶段引入图像内容和对象分割映射之间的token-wise一致性术语来改善多类别实例组合。TokenCompose可以直接应用于现有的文本条件扩散模型的训练管道,而无需额外的人工标记信息。通过使用我们的方法微调稳定扩散,该模型在多类别实例组成和增强其生成图像的真实感方面表现出显着的改进。
Introduction
没有额外的推理成本
Related Works
Compositional Generation. 旨在改进文本条件图像生成模型的合成图像生成的努力主要集中在训练和推理阶段。在训练中改进扩散模型合成生成的一种方法是通过引入额外的模块,如ControlNet,来指定图像中的高级特征。然而,扩散模型中添加的模块增加了模型的大小,导致额外的训练和推理成本。通过训练的另一种方法是利用奖励函数来鼓励基于构图提示的忠实生成图像[4 Training diffusion models with reinforcement learning,26 T2i-compbench,33 Aligning text-to-image models using human feedback.,71 Imagereward]。尽管奖励函数很有效,但它们是稀疏的,不能提供密集的监督信号。
基于推理的方法旨在改变潜在和/或交叉注意图。Composable Diffusion将组合提示分解为子提示以生成不同的潜在,并使用评分函数将潜在组合在一起,而Layout Guidance Diffusion使用自定义令牌和边界框将梯度反向传播到潜在。并引导交叉注意地图将重点放在特定区域的特定令牌上。其他方法使用高斯核[Attend-and-excite]或利用语言特征[16 structured diffusion,53 Linguistic binding in diffusion models]来操纵交叉注意图。虽然这些方法不需要进一步的训练,但它们在推理过程中增加了相当大的成本,在其他生成配置保持不变的情况下,生成单个图像的成本最多增加×3.37倍。
我们的框架是基于训练的,不需要将额外的模块合并到图像生成管道中。此外,基于分割图的注意力图优化提供了密集和可解释的监督。该模型是一种基于训练的方法,它联合优化了token-image对应和image生成,不需要进行推理时间的操作,但在条件生成中实现了较强的组合性和有竞争力的image quality。
Benchmarks for Compositional Generation. 已经提出了几个基准来评估文本条件图像生成模型的组合性。大多数方法通过将属性绑定到对象并指定对象之间的关系来评估组合性。例如,空间关系根据提示符[2,11,18,26,58]检查两个不同的对象是否出现在正确的空间布局中。颜色绑定检查文本条件图像生成模型是否能够正确地将指定的颜色分配给不同的对象,特别是当颜色分配违反直觉时[2,6,16,26,58]。计数绑定检查指定实例是否以提示符[2,11,58]中指定的正确计数出现。还有其他类型的属性绑定和关系规范在不同的基准测试中进行评估,例如动作和大小[2],形状和纹理[26]。
然而,大多数此类基准将评估绑定正确属性或指定正确的对象间关系的能力与提示符中提到的成功生成指定对象的能力相混淆。这使得很难评估改进是通过更强的属性分配和关系规范能力还是更高的对象精度来实现的[11,18,23]。VISOR[18]通过计算正确空间关系的成功率,将对象的准确性从空间关系的组合性中解耦,该成功率以提示符成功生成所有指定实例为条件。相比之下,几乎所有其他基准都不分离这些因素,而是在整体基础上评估组合性。
现有的多类别实例组合基准测试主要关注成功生成两个类别。另一方面,领先的图像生成模型在多类别实例组成方面取得了显著的进步[3,61],能够以较高的成功率生成多类别的实例。为了填补在评估两类以上的多类别实例组合方面的研究空白,并评估我们的多类别实例组合训练框架,我们提出了MULTIGEN基准测试,该基准测试包含文本提示,其中每个提示包含来自多个类别的任意组合的对象。
Generative Models for Image Understanding. 在开放词汇的图像理解任务中,文本条件图像生成模型的使用呈上升趋势,如分类[12,34]、检测[9,36]和分割[29,38,44,48,63,64,67 - 70,77]。
使用生成模型进行图像理解任务的一个固有优势是开放词汇,因为文本到图像的扩散模型是用开放词汇的文本提示进行训练的。尽管使用Stable Diffusion[55]进行无监督零样本学习图像理解的结果在相同设置(即零样本学习和开放词汇表)的方法中显示出巨大的潜力,但这些方法与使用专业模型进行图像理解的方法之间仍然存在性能差距[5,10,31,42,74]。这为我们提供了利用理解模型的知识来优化生成模型(例如,稳定扩散)的经验基础。此外,通过使用我们的方法优化扩散模型,我们还观察到下游分割任务的性能有所提高[39,63],这进一步反映了该知识的成功转移。
Method
Preliminaries
![]()
![]()
Token-level Attention Loss
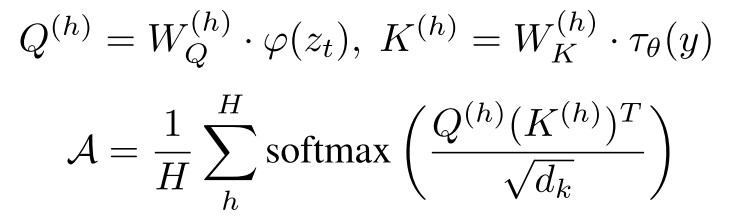
根据经验,我们观察到仅使用LLDM训练扩散模型通常会导致不同实例令牌的交叉注意映射的激活无法关注训练过程中图像中出现的相应实例,从而导致在推理过程中组合多类别实例的能力较差。

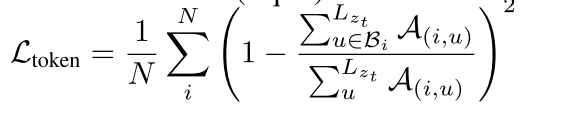
与Training-Free Layout Control with Cross-Attention Guidance和CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching方法类似
Pixel-level Attention Loss


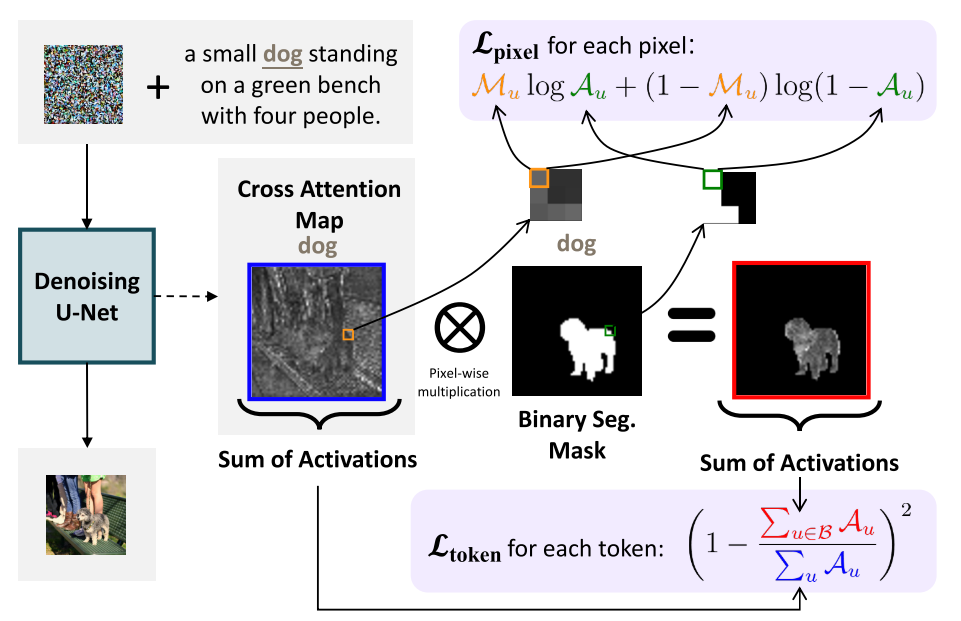
图3. Ltoken和Lpixel的图解。我们说明了如何在给定交叉注意图Ai和二元分割掩码Mi的情况下计算Ltoken和Lpixel。Ltoken聚集了Mi的非掩码区域的注意激活,并且该目标通过Ai的总激活归一化。然而,它并没有限制激活在非屏蔽区域内的位置。Lpixel给出了精确的监督一个像素是否属于分割的区域,约束激活的地方应该是二进制值。然而,它不是由Ai的总激活量规范化的。结合Ltoken和Lpixel,我们充分利用了每个目标的优势,同时将其副作用降到最低。我们在图4中展示了使用Ltoken和Lpixel优化的模型的交叉注意激活示例,其中一个是Ltoken和Lpixel,另一个是Ltoken和Lpixel。
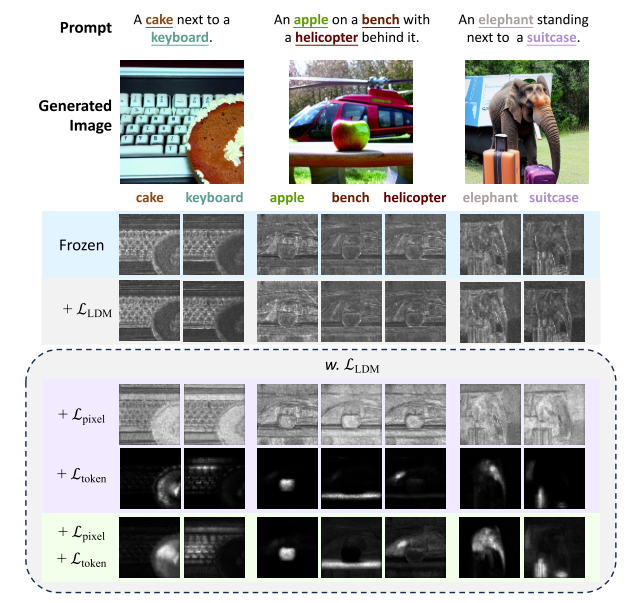
图4。不同目标对交叉注意激活的影响。我们首先证明了仅用LLDM对稳定扩散进行微调并不能提高接地能力。单独添加Lpixel通常会增加交叉注意激活。添加Ltoken在改善token接地方面起着至关重要的作用,但会导致激活在目标的子区域中聚集。通过Ltoken和Lpixel的结合,该模型在基于图像特征的文本标记方面有了很大的改进。在本例中,我们将空文本反演[47]技术应用于所有模型,允许它们为可比的交叉注意地图生成相同的图像。
Experiment
Training Details
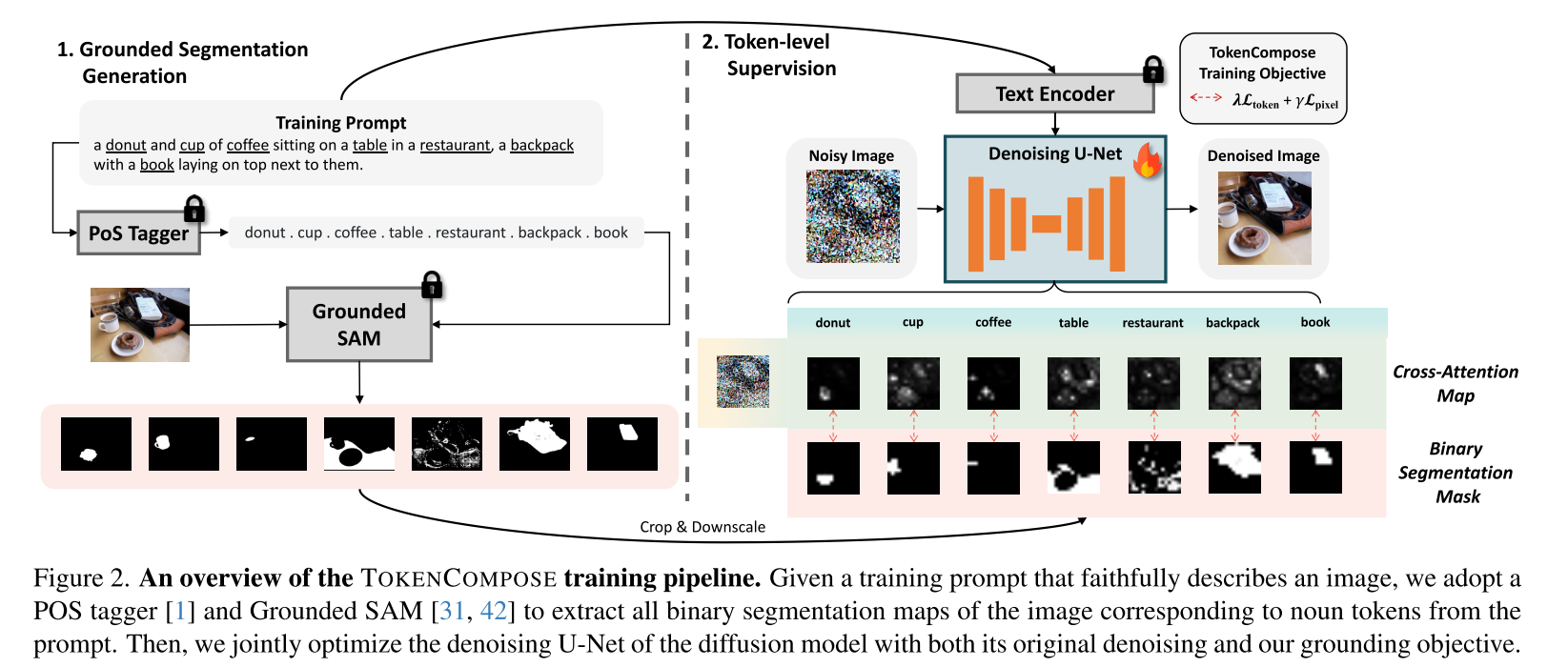
Dataset. 为了研究标记着陆目标的有效性,我们对COCO图像标题对子集上的稳定扩散模型进行了微调。具体来说,我们首先从视觉空间推理数据集中选择所有唯一的图像,因为这些图像具有更少的视觉语言歧义,并且每个图像中出现的不同类别数量更多。然后使用CLIP模型选择与其对应图像语义相似度最高的标题。最后,我们采用预训练的名词解析器从标题中解析所有名词,并利用ground - sam为每个名词(或名词短语)生成二值分割掩码。最终的数据集由~ 4526个图像标题对及其各自的二值分割掩码组成。我们在图2中演示了一个高级数据和训练管道。
Setup. 我们的主要实验是使用Stable Diffusion v1.4进行的,这是一种用于高质量生成的流行文本到图像扩散模型。除了原始去噪目标LLDM之外,还使用Ltoken和Lpixel,使用AdamW优化器,其恒定的全局学习率为5e-6,共24,000步(稳定扩散v2.1为32,000步)。在单个GPU上以1和4个梯度累积步骤的批处理大小训练整个U-Net。对所有训练图像及其各自的分割图m应用中心裁剪。对于Stable Diffusion v1.4,交叉注意层位于U-Net编码器UE,中间块UMid和解码器UD。我们将Ltoken和Lpixel应用于UMid和UD中的所有交叉注意层。
Main Results
Baselines. 我们将我们的微调后的Stable Diffusion v1.4模型与几个基线进行了比较:
(1)Composable Diffusion,它将提示分解为不同的条件,并使用基于分数的机制对图像进行去噪
(2)Layout Guidance Diffusion,将交叉注意地图梯度反向传播到带有用户指定对象标记和边界框的噪声潜势,以生成空间可控的成分;
(3)Structured Diffusion,自动将提示解析为选区树,并操纵交叉关注键和值以生成组合;
(4) Attend-and-Excite,它应用来自用户指定标记的高斯核注意图,并使用平滑的注意图来生成合成。
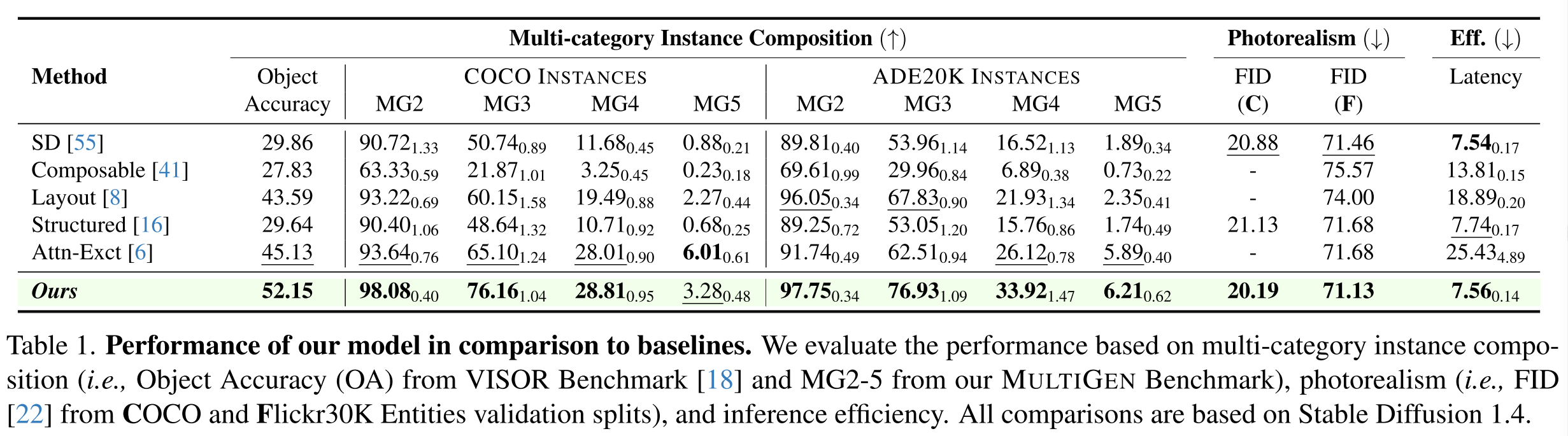
Multi-category Instance Composition. 检查这种组合性的基准测试侧重于在文本条件中提到的图像中成功生成多个类别的实例。我们使用现有的基准测试VISOR和我们的基准测试MULTIGEN来研究模型在多类别实例组合中的能力。VISOR基准从COCO中获得80个对象类别的所有唯一成对组合,并将每对(A, B)转换为具有任意空间关系(R)的文本提示符,遵循模板“<A> <R> <B>”,例如,“摩托车在大象的左边”。对于从这些提示生成的图像,VISOR使用开放词汇检测器来检测对中每个类别的存在和空间位置。对象准确性(OA)度量从两个类别生成实例的成功率。VISOR还提供空间关系的度量。然而,由于我们的工作重点是多类别实例组合,因此我们只采用OA度量,并在表1中报告相关数字。
与VISOR相比,MULTIGEN使用了类似的评估策略,但它被设计成一个更具挑战性的多类别实例组合指标。具体来说,给定一组大小为N的不同实例类别,我们随机抽取5个类别(例如,a, B, C, D, E),将它们格式化成一个句子(即,a, B, C, D和E的照片),并将它们用作文本到图像扩散模型生成图像的条件。然后,我们使用一个强大的开放词汇检测器[46]来检测这些类别在生成的图像中的存在。我们对80个类别的coco实例[39]和100个类别的ADE20K实例[78,79]执行了1000次采样过程,从每个数据集中得到1000个文本提示作为多类别实例组合。对于每个生成的图像,我们利用检测器来检测图像中出现了多少类别的实例。我们将生成5个特定类别中的2-5个的总体成功率汇总为MG2-5。
合成图像的生成通常涉及推理方差。为了解决这个问题,使用MULTIGEN中的每个提示符生成10轮图像,这导致为每个数据集的类别组合生成10 × 1000张图像。我们计算了每轮MG2-5,并在表1中报告了10轮MG2-5成功率的平均值和标准差(下标)。根据评估,我们的模型在目标精度和MG2-4方面超过了所有基线。我们发现,Attend-and-Excite[6]在生成所有5个类别方面都有相当大的成功率,但在生成2-4个类别方面却相对不足。我们推测这是由于训练分布,其中标题不包括多达5个或更多类别的实例,这不可避免地导致多类别实例组成的改进减少。
Photorealism. 我们使用Fr ' cheet初始距离(FID)度量[22]比较基线和模型生成的图像质量。对于除了标题之外不需要额外条件输入的基线,我们基于从COCO验证集(C)中采样的10,000对图像标题对计算FID分数。我们还报告了基于来自Flickr30K实体验证集(F)[50]的1,000对图像标题对的FID度量。由于该数据集为标题中的实体提供了标签和边界框[73],因此它可以被需要此类输入的基于推理的方法使用。我们在表1中报告所有适用的分数。与图5中的模型相比,我们还结合不同基线上的多类别实例组合对图像质量进行了定性评估。为了公平起见,我们在每次比较中使用相同的初始潜在值。
Efficiency. 作为一种基于训练的方法,与标准的文本到图像扩散管道相比,我们的模型不需要额外的推理时间操作。另一方面,大多数基于推理的方法对合成生成施加了不可忽视的计算负担,其中最慢的基线(Attend-and-Excite)需要超过3倍的时间来生成单个图像。我们在表1中报告了在单个NVIDIA RTX 3090 GPU上使用50个DDIM步骤和无分类器引导生成图像所需的秒数的效率结果。

Generalization
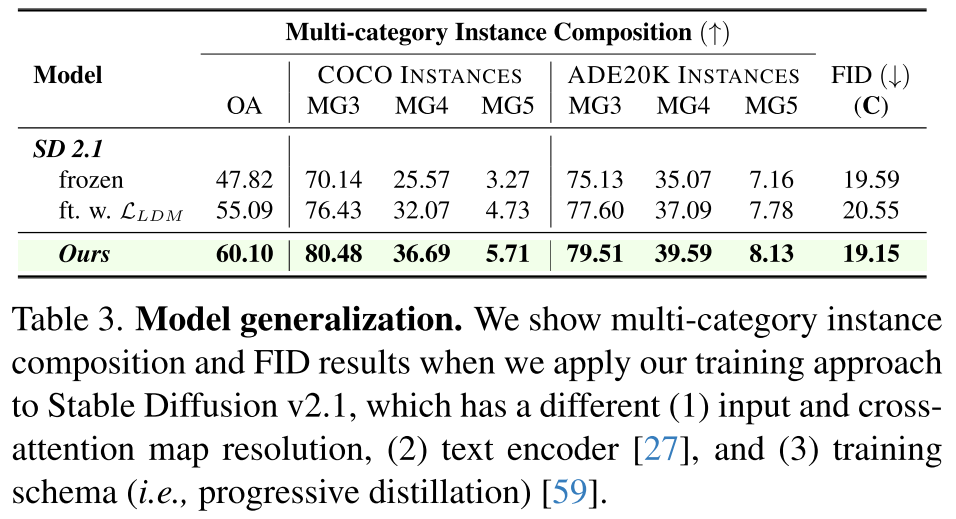
我们评估了我们的训练方法是否可以推广到文本到图像模型的不同变体。为此,我们将Ltoken和Lpixel以及LLDM应用到Stable Diffusion v2.1中,并在表3中比较了冻结基线和仅使用LLDM训练的基线在多类别实例组成和真实感方面的结果。结果表明,这些接地目标也显著有利于Stable Diffusion v2.1。
Knowledge Transfer

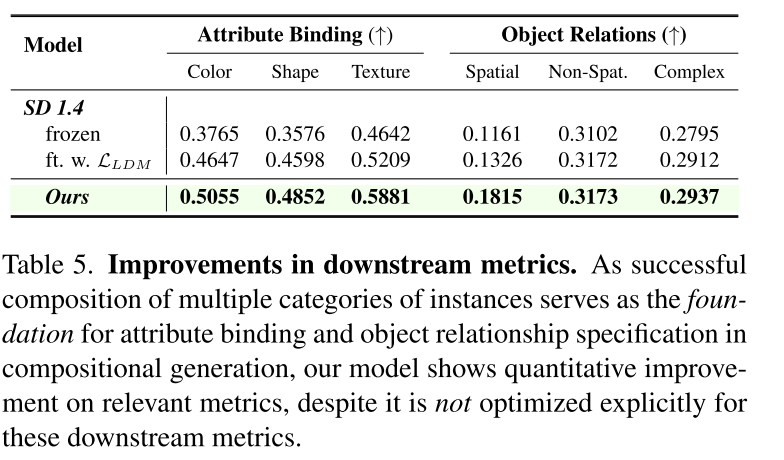
Downstream Metrics
Ablations
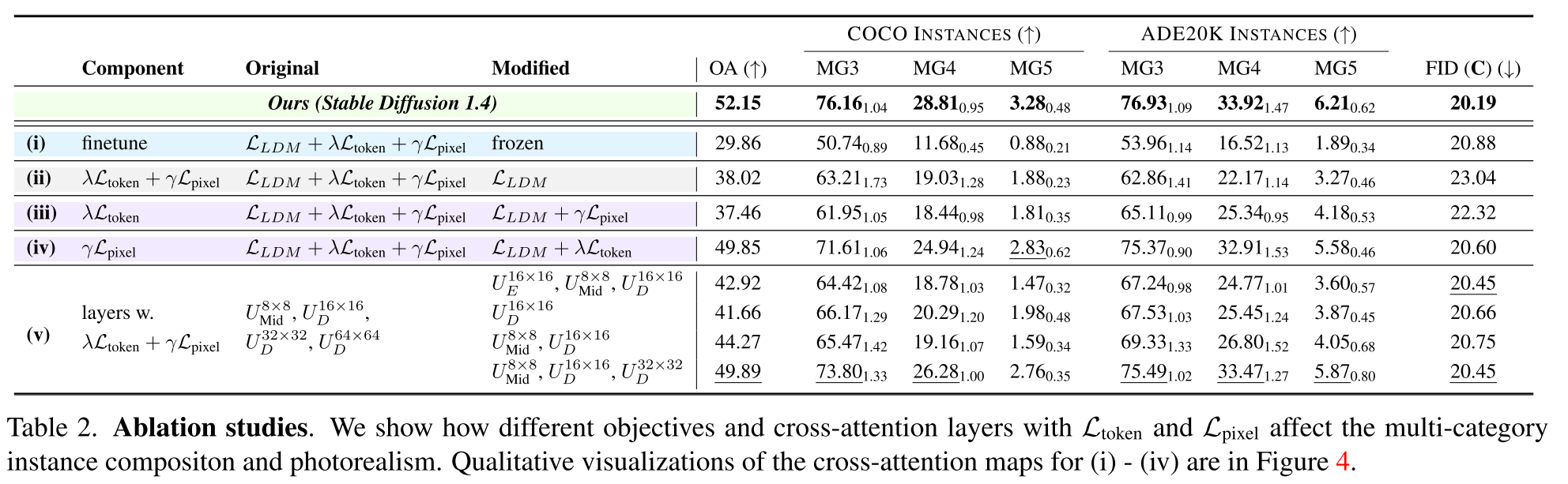
Grounding Objectives
Layers with Grounding Objectives
最后,我们尝试在去噪的U-Net (v)的不同交叉关注层添加Lpixel和Ltoken。我们发现,在U-Net的中间块和解码器中添加接地目标可以提高多类别实例组合的整体性能。从中间块中删除约束或将约束添加到编码器中会降低性能。此外,对于可变分辨率解码器的交叉注意层,我们发现使用Lpixel和Ltoken优化的层越多,在多类别实例组成和照片真实感方面的性能越好。
Limitation & Conclusion
作为探索使用理解模型改进具有图像-标记一致性的文本条件生成模型的潜力的开创性工作之一,我们仅在文本提示的名词标记中添加监督术语。虽然我们表明这种方法显著提高了多类别实例组合,但文本提示中有更多元素可以利用理解模型来改进生成模型,例如形容词、动词和/或限定词作为细粒度标记级训练目标。