C++手撕STL-其叁
Deque
今天我们进入新的容器:deque,一般叫做双端队列。
比起传统的先入先出的队列queue,deque的出场率显然要低得多,事实上deque比起queue来说最大的特点就是多了一个push_front()和pop_front(),其他并没有太多不同。
我们首先来介绍deque的真实数据结构:
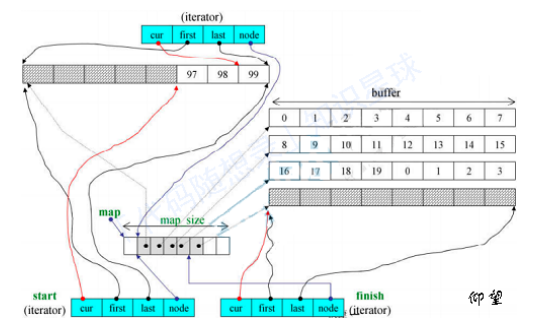
在queue中,我们只能操作队列尾部的元素(添加或者删除),所以队列可以用一个数组来实现,队列也确实是严谨的地址连续的数组。而双端队列则不然:他的队列头部也可以操作元素,这就带来一个问题:我们怎么给地址连续的数据结构的首部添加元素呢?
如图所示,他是通过一个中控的数组来控制多个缓冲区(缓冲区就是我们添加的元素),然后中控数组和各个缓冲区的地址是连续的,我们用迭代器start()和end()来实现对deque的访问。
template<class T, class Alloc=alloc, size_t Bufsize = 0>
class deque {
public:typedef T value_type;typedef value_type pointer*;typedef size_t size_type;// ...
public:typedef _deque_iterator<T, T &, T *, BufSiz> iterator;
protected:typedef pointer *map_pointer;
protected:iterator start;iterator finish;map_pointer map;//指向mapsize_type map_size;//map内可容纳多少指针
}这是deque的大体代码,其中的map_pointer类型就是我们的中控数组类型,size_type类型的map_size则是表明我们的中控数组具体可以容纳多少指针。deque除了维护⼀个map指针以外,还维护了start与finish迭代器分别指向第⼀缓冲区的第⼀个元素,和最后⼀个缓冲区的最后⼀个元素的下⼀个元素,同时它还必须记住当前map的大小。
然后我们首先来看看deque的迭代器具体是怎么工作的:
template<class T, class Ref, class Ptr, size_t BufSiz>
struct _deque_iterator {typedef _deque_iterator<T, T &, T *, BufSiz> iterator;typedef _deque_iterator<T, cosnt T &, const T *, BufSiz> const_iterator;static size_t buffer_size() { return _deque_buf_size(BufSiz, sizeof(T)); };typedef randem_access_iterator_tag iterator_category;typedef T value_type;typedef Ptr pointer;typedef Ref reference;typedef size_t size_type;typedef ptrdiff_t difference_type;typedef T **map_pointer;typedef _deque_iterator self;T *cur;T *first;T *last;map_pointer node;// ...//这是⼀个设置缓存区⼤⼩的函数inline size_t _deque_buf_size(size_t n, size_t sz) {return n != 0 ? n :(sz < 512 ? size_t(512 / sz) : size_t(1));}
}可以看到首先是常量/非常量的迭代器:常量迭代器满足查的需求而非常量满足增删改的需求。
然后我们是一个返回缓冲区大小的函数,一个是否允许随机访问的变量(之前的vector中出现过),数据类型,指针,引用,数据大小,指针差异(之前vector都有),然后是一个T**的数据类型(T**是什么呢其实就是一个指向T类型指针的指针(从右往左看))变量map_pointer,这里他指向的自然就是我们的中控数组(确切地说,数组指针)。
下面是一个用inline修饰的函数:设置缓冲区大小的函数,其中的内容含义是:参数为数据个数n和元素大小sz,如果n不等于0则直接返回n,否则我们判断单个元素的大小是否超过512,超过的话就返回1(占据一个缓冲区),否则我们就用512来除以元素大小来表示可以存储的元素个数。可能看起来有点晕,其实核心思路就是如果一个元素过大我们一个缓冲区就存一个元素,否则我们一个缓冲区可以多存几个元素,我们用这个准则来设置缓冲区大小。
然后是我们迭代器的一系列方法:
//迭代器的关键⾏为,其中要注意的是⼀旦遇到缓冲区边缘,可能需要跳⼀个缓存区
void set_node(map_pointer new_node) {node = new_node;first = *new_node;last = first + difference_type(buffer_size());
}
//接下来᯿载运算⼦是_deque_iterator<>成功运作的关键
reference operator*() const { return *cur; }
pointer operator->() const { return &(operator*()); }
difference_type operator— (const self &x) const {return difference_type (buffer_szie()) * (node-x.node-1)+(cur-first)+(x.last-x.cur);
}
self &operator++() {++cur;if (cur == last) {set_node(node + 1);cur = first;}return *this;
}
self operator++(int) {self temp = *this;++*this;return temp;
}
self &operator--() {if (cur == first) {set_node(node - 1);cur = last;}--cur;return *this;
}
self operator-(int) {self temp = *this;--*this;return temp;
}
//以下实现随机存取,迭代器可以直接跳跃n个距离
self &operator+=(difference_type n) {difference_type offest = n + (cur - first);if (offest > 0 && offest < difference_type(buffer_size()))cur += n;else {offest > 0 ? offest / fifference_type(buffer_size()) : -difference_type((-
offest - 1) / buffer_size()) - 1;set_node(node + node_offest);cur = first + (offest - node_offest * difference_type(buffer_size()));}return *this;
}
self operator+(differnece_type n) {self tmp = *this;return tmp += n;
}
self operator-=() { return *this += -n; }
self operator-(difference_type n) {self temp = *this;return *this -= n;
}
rference operator[](difference_type n) {return *(*this + n);
}
bool operator==(const self &x) const { return cur == x.cur; }
bool operator!=(const self &x) const { return !(*this == x); }
bool operatoe<(const self &x) const {return (node == x.node) ? (cur < x.cur) : (node - x.node);
}set_node是一个切换缓冲区的函数,我们把node、first、last都切换为新缓冲区的对应元素,然后是解指针和引用的运算符重载,我们重载*和->来返回指针和引用。然后是迭代器的距离计算函数,然后就是迭代器的移动,通过重载++和--实现,这里注意我们似乎有一个返回引用而一个不返回引用,这是为什么呢?那是因为其实我们做了一个前置自增和后置自增,也就是++i和i++的区别:对于前置自增,我们直接在原地修改数据,所以直接返回引用即可;而后置自增我们返回的是复制出来的备份,显然只能返回数据本身。剩下的无非就是一些基本的迭代器中的运算符重载,不再赘述。
回到我们的deque类,我们的deque的空间分配器有两个:
typedef simple_alloc <value_type, Alloc> data_allocator;
typedef simple_alloc <pointer, Alloc> map_allocator;如果你还不知道什么是分配器的话:
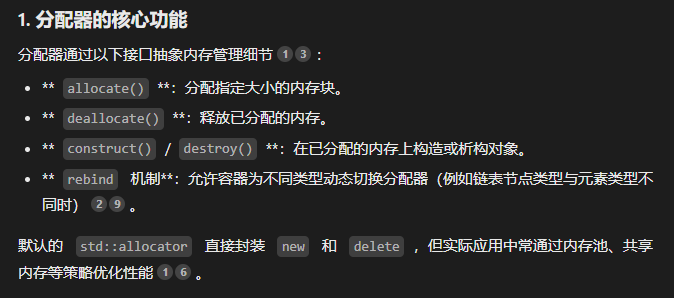
对于deque中,需要管理内存的有两部分:中控数组和缓冲区。
deque(int n, const value_type &value) : start(), finish(), map(0), map_size(0) {fill_initialize(n, value);//这个函数就是⽤来构建deque结构,并设⽴初值
}
template<class T, class Alloc, size_t BufSize)
void deque<T, Alloc, BufSize>::fill_initialize(size_type n, const value_type &value) {creat_map_and_node(n);//安排结构map_pointer cur;_STL_TRY {//为每个缓存区赋值for (cur=start.node;cur<finish.node;++cur)uninitalized_ fill(*cur, *cur+buffer_size(), value);//设置最后⼀个节点有⼀点不同uninitalized_fill(finish.first, finish.cur, value);}catch() {// ...}
}
template<class T, class Alloc, size_t Bufsize>
void deque<T, alloc, Bufsize>::creat_map_and_node(size_type num_elements) {//需要节点数=元素个数/每个缓存区的可容纳元素个数+1size_type num_nodes = num_elements / Buf_size() + 1;map_size = max(initial_map_size(), num_nodes + 2);//前后预留2个供扩充//创建⼀个⼤⼩为map_size的mapmap = map_allocator::allocate(map_size);//创建两个指针指向map所拥有的全部节点的最中间区段map_pointer nstart = map + (map_size() - num_nodes) / 2;map_poniter nfinish = nstart + num_nodes - 1;map_pointer cur;_STL_TRY {//为每个节点配置缓存区for (cur=nstart;cur<nfinish;++cur)+cur=allocate_node();}catch() {// ...}//最后为deque内的start和finish设定内容start.set_node(nstart);finish.set_node(nfinish);start.cur = start.first;finish.cur = finish.first + num_elements % buffer_szie();
}一开始的构造函数不用多说。
写deque命名空间内的初始化函数fill_initialize,准确地说是填充函数,使用了一个STL_TRY和catch,其实就是宏定义下替换的try。
void push_back(const value_type &t) {if (finish.cur != finish.last - 1) {construct(finish.cur, t);++finish.cur;} elsepush_back_aux(t);
}
// 由于尾端只剩⼀个可⽤元素空间(finish.cur=finish.last-1),
// 所以我们必须᯿新配置⼀个缓存区,在设置新元素的内容,然后更改迭代器的状态
tempalate<class T, class Alloc, size_t BufSize>
void deque<T, alloc, BufSize>::push_back_aux(const value_type &t) {value_type t_copy = t;reserve_map_at_back();*(finish.node + 1) = allocate_node();_STL_TRY {construct(finish.cur, t_copy);finish.set_node(finish.node+1);finish.cur=finish.first;}- STL_UNWIND {deallocate_node(*(finish.node + 1));}
}
//push_front也是⼀样的逻辑最后实现我们的push_back和push_front函数,最大的点就是要关注我们的map(中控数组)是否有扩容的需求,有的话我们要重新开辟一块新的内存空间,然后把我们的中控数组复制过去,然后把各个缓冲区的指针也复制过去,这样我们扩容的开销就会非常之小。
Stack
讲述完我们的deque之后,我们就来聊聊在deque的基础之上完成的配接器吧:
如果你还不知道什么是配接器的话:
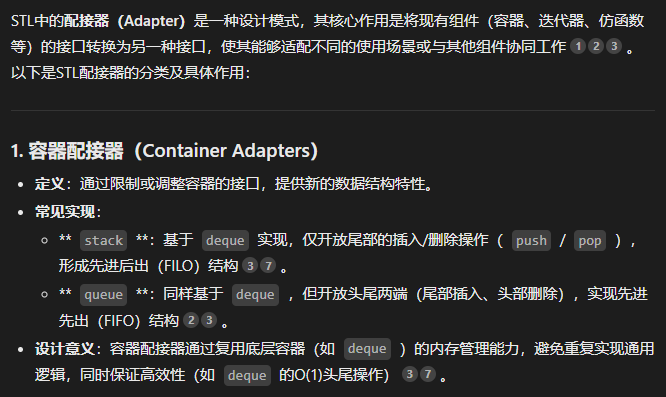
大白话说的话就是:把接口不适配的容器进行接口修改以达到适配的效果。
虽然我觉得应该没有人不认识栈和队列,但还是给大家一个图先:

栈的源码如图:
template<class T, class Sequence=deque<T>>
class stack {
public:typedef typename Sequence::value_type value_type;typedef typename Sequence::size_type size_type;typedef typename Sequence::reference reference;typedef typename Sequence::const_reference const_reference;
protected:Sequence c; // 底层容器对象
};我们在类模板中提供名为Sequense的参数且默认为deque<T>,然后取Sequense中的变量进行类型名重命名。
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
reference top() { return c.back(); }
void push(const value_type &x) { c.push_back(x); }
void pop_back() { c.pop_back(); }一些基本的方法 。
template<class T, class Sequence>
bool operator==(const stack<T,Sequence>& x, const stack<T,Sequence>& y) {return x.c == y.c;
}
template<class T, class Sequence>
bool operator<(const stack<T,Sequence>& x, const stack<T,Sequence>& y) {return x.c < y.c;
}重载==和<。
stack<int, vector<int>> custom_stack; // 使用vector作为底层这里是显示地声明创建底层实现为vector<int>的适配器stack。
priority_queue
写完了栈怎么能不写堆呢?
如果有人不知道堆的话:

话虽如此,在C++之中并没有堆的现成数据结构,但是有堆的实现算法,而优先队列本质上其实就是一个堆,但是他还提供了类似于队列的访问方式和数据结构。
template<class T, class Sequence=vector <T>, class Compare=less<typename
Sequence::value_type>>
class priority_queue {
public:typedef typename Sequence::value_type value_type;typedef typename Sequence::size_type size_type;typedef typename Sequence::reference reference;typedef typename Sequence::const_reference const_refernece;
protected:Sequence c;//底层容器Compare comp//容器⽐较⼤⼩标准
public: priority_queue() : c() {}explicit priority_queue(const Compare &x) : c(), comp(x) {}//以下⽤到的make_heap(),push_heap(),pop_heap()都是C++自带的泛型算法//任何⼀个构造函数都可以⽴即在底层产⽣⼀个heaptemplate<class InputIterator>priority_queue(InputIterator first, InputIterator last const Compare &x):c(first, last), comp(x) { make_heap(c.begin(), c.end(), comp); }template<class InputIterator>priority_queue(InputIterator first, InputIterator last const Compare &x):c(first, last) { make_heap(c.begin(), c.end(), comp); }bool empty() const { return c.empty(); }size_type size() const { return c.size(); }const_reference top() const { return c.front(); }void push(const value_type &x) {_STL_TRY {c.push_back(X);push_heap(c.begin(), c.end(), comp);}_STL_UNWIND{c.clear()};}void pop() {_STL_TRY {pop_heap(c.begin(), c.end(), comp);c.pop_back();}_STL_UNWEIND{c.clear()};}
};
// priority_queue⽆迭代器可以看到,成员变量的定义方式和之前的stack差不太多;如果一定要说有什么可讲的话,我觉得是这两个构造函数,区别就在于有无将comp(仿函数)显式地给定。就这样,我们使用vector<int>作为底层容器,一个仿函数以及一系列C++提供的有关heap的函数(make_heap(),push_heap(),pop_heap())就实现了一个优先队列了。