Docker 在 AI 开发中的实践:GPU 支持与深度学习环境的容器化
人工智能(AI)和机器学习(ML),特别是深度学习,正以前所未有的速度发展。然而,AI 模型的开发和部署并非易事。开发者常常面临复杂的依赖管理(如 Python 版本、TensorFlow/PyTorch 版本、CUDA、cuDNN)、异构硬件(CPU 和 GPU)支持以及环境复现困难等痛点。这些挑战严重阻碍了 AI 项目的效率和可移植性。
Docker 容器技术 应运而生,为解决这些问题提供了强大的解决方案。通过将 AI 开发环境及其所有依赖打包到独立的容器中,Docker 极大地简化了环境配置、保证了复现性,并提升了可移植性。更重要的是,对于依赖 GPU 进行加速的深度学习任务,NVIDIA Docker (即现在的 NVIDIA Container Toolkit) 提供了一种无缝集成 GPU 资源的方式,使得容器能够充分利用 GPU 的强大计算能力。
本文将深入探讨 AI/深度学习开发环境的常见痛点,解析 Docker 如何通过容器化解决这些问题,重点介绍 NVIDIA Docker 的原理与实践,并结合代码示例,指导您构建和运行 GPU 加速的深度学习容器。
一、AI/深度学习开发环境的痛点
A. 复杂的依赖管理
- Python 版本冲突: 不同 AI 项目可能需要不同的 Python 版本,导致环境冲突。
- 深度学习框架版本: TensorFlow、PyTorch、MXNet 等框架版本更新频繁,不同版本之间可能存在 API 不兼容或性能差异,且与 Python 版本有严格对应关系。
- CUDA/cuDNN 版本: GPU 加速的深度学习依赖 NVIDIA 的 CUDA Toolkit 和 cuDNN 库。这些库的版本必须与 GPU 驱动、深度学习框架版本之间存在严格的兼容性要求,配置起来极其繁琐。
- 系统库依赖: 各种底层的 C/C++ 库、图像处理库(如 OpenCV)等也可能带来依赖冲突。
B. 环境复现困难
“在我机器上能跑”是 AI 领域常见的尴尬。由于环境配置的复杂性,将一个 AI 项目从开发者的机器迁移到测试环境、生产服务器,甚至其他开发者的机器上,往往会因为依赖版本不一致而导致失败。
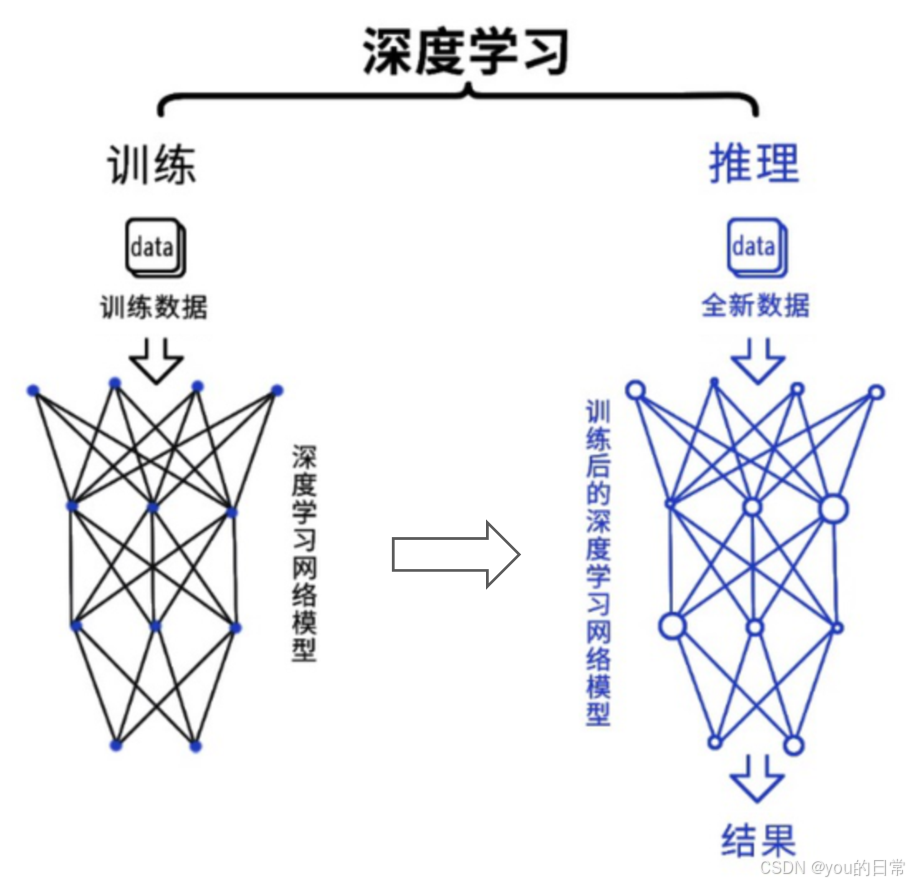
C. 异构硬件支持
AI 模型的训练和推理往往需要强大的 GPU 计算能力。如何在容器中有效访问和利用宿主机的 GPU 资源,是 AI 容器化面临的核心挑战。
二、Docker 如何解决 AI 开发痛点
Docker 容器通过其核心的隔离和打包机制,为 AI 开发带来了显著的优势:
-
A. 环境隔离与一致性:
每个 AI 项目可以在独立的 Docker 容器中运行,拥有自己独立的 Python 环境、依赖库和框架版本,互不干扰。容器镜像确保了从模型开发、训练、验证到最终部署的环境一致性,大大减少了“环境问题”。 -
B. 简化依赖管理:
通过 Dockerfile,所有环境依赖都以声明式的方式被清晰地定义。只需执行一个docker build命令,即可一键构建出完整的 AI 环境,省去了手动安装和配置的繁琐。Docker Hub 和 NVIDIA 官方也提供了大量预装了 CUDA、cuDNN 和流行深度学习框架的基础镜像。 -
C. 提高可移植性:
一旦 AI 环境被打包成 Docker 镜像,它就具备了高度的可移植性。这个镜像可以在任何支持 Docker 的机器上运行,无论是本地开发机、云服务器(如 AWS EC2、Azure VM)、边缘设备,甚至其他操作系统(通过 Docker Desktop)。 -
D. 资源管理:
Docker 允许您限制容器的 CPU 和内存使用,这对于管理 AI 工作负载的资源消耗非常有用。而对于 GPU 资源,则需要借助专门的工具。
三、NVIDIA Docker:深度学习的 GPU 利器
Docker 默认情况下无法直接访问宿主机的 GPU 资源。为了让容器能够利用 GPU 进行深度学习加速,我们需要 NVIDIA Container Toolkit(该工具集以前被称为 nvidia-docker2 或 nvidia-docker)。
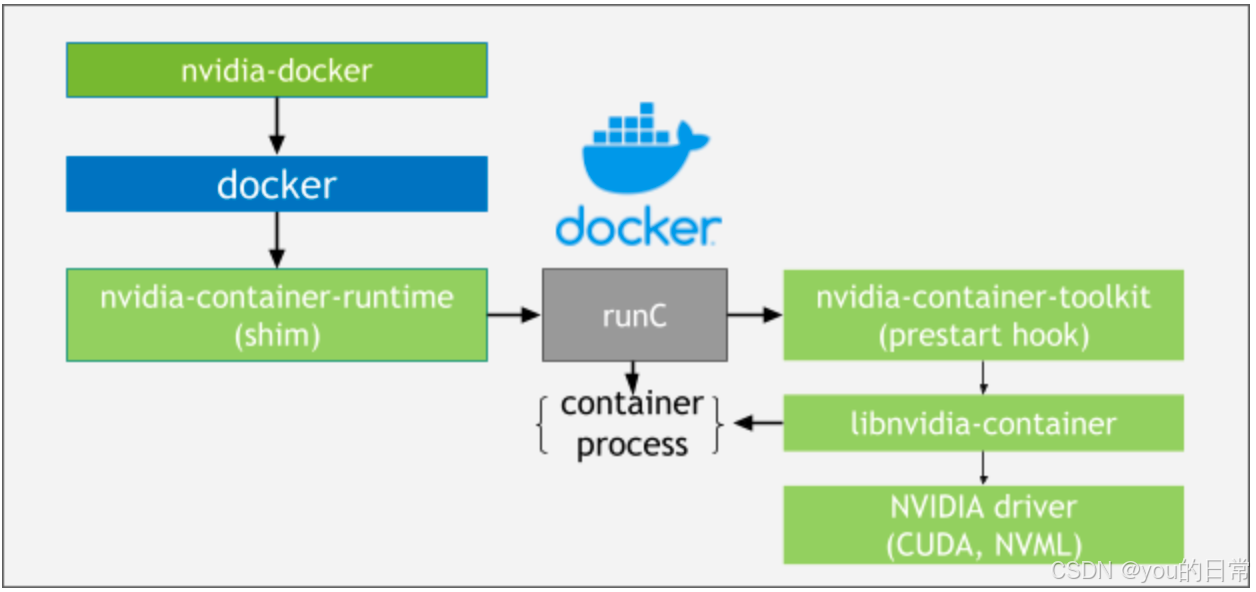
A. 为什么需要 NVIDIA Docker?
它充当了 Docker Engine 和 NVIDIA GPU 驱动之间的桥梁。它提供了一个特殊的容器运行时(nvidia-container-runtime),能够:
- 自动检测宿主机的 NVIDIA GPU 设备。
- 将必要的 GPU 设备文件(如
/dev/nvidia0)和驱动库(如libcuda.so、libnvidia-ml.so)以及 CUDA Toolkit 组件,透明地挂载到容器内部。 - 确保容器内部的深度学习框架能够正确调用 GPU 进行计算。
B. 工作原理
当您使用 docker run --gpus all ... 命令运行容器时,Docker Engine 会调用 nvidia-container-runtime。这个运行时会检查宿主机上的 GPU 状态,并动态地在容器启动时插入必要的 GPU 驱动和设备映射。对于容器内的应用来说,它就像直接在宿主机上运行一样,能够感知并利用 GPU。
C. 安装与配置
安装 NVIDIA Co