大模型-attention汇总解析之-GQA
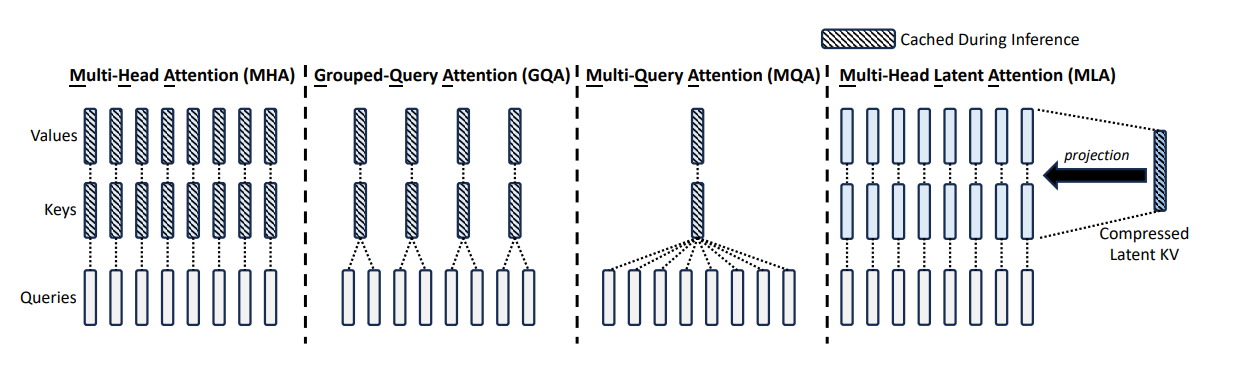
从上面的图可以看出,MHA是一个attention 头有自己独立的kv cache 缓存,这样子的计算效果是最好的,同时kv cache 也是最完善的,意味着也是最占用内存的。MQA 进行了极致的kv cache 共享,那么能不能对多头进行分组,一组多头共享一组KV cache呢?在二者中间做一个折中呢?
论文《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》对这个想法进行了实践。它就是将所有 Head 分为 g个组( h可以整除g ),每组共享同一对 K、V,用数学公式表示为
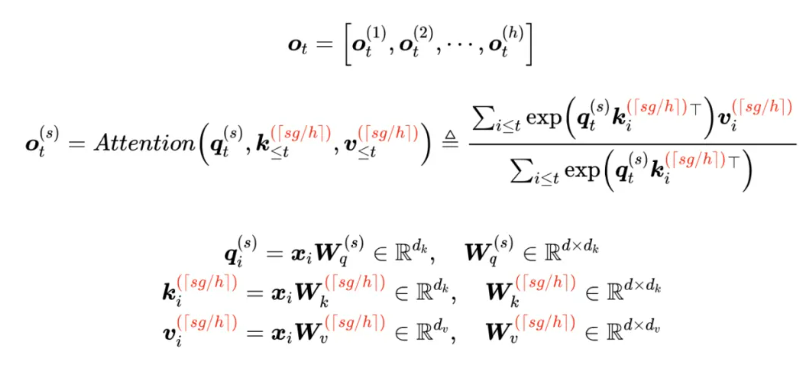
GQA 提供了 MHA 到 MQA 的自然过渡,
-
当g==h 时就是 MHA,
-
g==1 时就是 MQA
-
当 g<h时,它只将 KV Cache 压缩到g/h ,压缩率不如 MQA,但同时也提供了更大的自由度, 更好的计算效果。
GQA 最知名的使用者,大概是 Meta 开源的 LLAMA2-70B,以及 LLAMA3全系列,此外使用 GQA 的模型还有 TigerBot 、DeepSeek-V1、ChatGLM2、ChatGLM3 等,比使用 MQA 的模型更多。
-
MHA:MHA KVCache 在注意力头这个维度和 Q 矩阵一样,属于“一对一”。MHA把一个注意力计算拆成多个注意力头,每个注意力头使用独立的Q、K、V进行计算,需要把K、V都存储下来,KV Cache中每个token需要缓存的参数量为2n*h_d*h_l。而GQA、MQA 在注意力头的维度比 Q 矩阵小。
-
MQA:所有查询头共享相同的单一键和值头,因此只需要存储共享的K和V,KV Cache中每个token需要缓存的参数量为2d_h_l。在计算注意力时,会把共享的单一K头和V头广播给每个查询头,然后分别一一计算。
-
GQA:将所有的Q头分成g组,同一组的Q头共享一个K头和一个V头,因此KV Cache中每个token需要缓存的参数量为2n_g_d_h_l。在计算注意力时,会把KV头复制给所在组的所有Q头进行计算。
n_h是注意力头数量,n_g是GQA分组数,d_h是隐藏层维度,l为模型层数,h_t∈R^d 表示第 𝑡 个token在一个attention层的输入。